 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-MotionControl Technical Report
Mar 03, 2026Character animation aims to generate lifelike videos by transferring motion dynamics from a driving video to a reference image. Recent strides in generative models have paved the way for high-fidelity character animation. In this work, we present Kling-MotionControl, a unified DiT-based framework engineered specifically for robust, precise, and expressive holistic character animation. Leveraging a divide-and-conquer strategy within a cohesive system, the model orchestrates heterogeneous motion representations tailored to the distinct characteristics of body, face, and hands, effectively reconciling large-scale structural stability with fine-grained articulatory expressiveness. To ensure robust cross-identity generalization, we incorporate adaptive identity-agnostic learning, facilitating natural motion retargeting for diverse characters ranging from realistic humans to stylized cartoons. Simultaneously, we guarantee faithful appearance preservation through meticulous identity injection and fusion designs, further supported by a subject library mechanism that leverages comprehensive reference contexts. To ensure practical utility, we implement an advanced acceleration framework utilizing multi-stage distillation, boosting inference speed by over 10x. Kling-MotionControl distinguishes itself through intelligent semantic motion understanding and precise text responsiveness, allowing for flexible control beyond visual inputs. Human preference evaluations demonstrate that Kling-MotionControl delivers superior performance compared to leading commercial and open-source solutions, achieving exceptional fidelity in holistic motion control, open domain generalization, and visual quality and coherence. These results establish Kling-MotionControl as a robust solution for high-quality, controllable, and lifelike character animation.
Segment and Matte Anything in a Unified Model
Jan 17, 2026Segment Anything (SAM) has recently pushed the boundaries of segmentation by demonstrating zero-shot generalization and flexible prompting after training on over one billion masks. Despite this, its mask prediction accuracy often falls short of the precision required in real-world applications. While several refinement modules have been proposed to boost SAM's segmentation quality, achieving highly accurate object delineation within a single, unified framework remains an open challenge. Furthermore, interactive image matting, which aims to generate fine-grained alpha mattes guided by diverse user hints, has not yet been explored in the context of SAM. Insights from recent studies highlight strong correlations between segmentation and matting, suggesting the feasibility of a unified model capable of both tasks. In this paper, we introduce Segment And Matte Anything (SAMA), a lightweight extension of SAM that delivers high-quality interactive image segmentation and matting with minimal extra parameters. Our Multi-View Localization Encoder (MVLE) captures detailed features from local views, while the Localization Adapter (Local-Adapter) refines mask outputs by recovering subtle boundary details. We also incorporate two prediction heads for each task into the architecture to generate segmentation and matting masks, simultaneously. Trained on a diverse dataset aggregated from publicly available sources, SAMA achieves state-of-the-art performance across multiple segmentation and matting benchmarks, showcasing its adaptability and effectiveness in a wide range of downstream tasks.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
KlingAvatar 2.0 Technical Report
Dec 15, 2025Avatar video generation models have achieved remarkable progress in recent years. However, prior work exhibits limited efficiency in generating long-duration high-resolution videos, suffering from temporal drifting, quality degradation, and weak prompt following as video length increases. To address these challenges, we propose KlingAvatar 2.0, a spatio-temporal cascade framework that performs upscaling in both spatial resolution and temporal dimension. The framework first generates low-resolution blueprint video keyframes that capture global semantics and motion, and then refines them into high-resolution, temporally coherent sub-clips using a first-last frame strategy, while retaining smooth temporal transitions in long-form videos. To enhance cross-modal instruction fusion and alignment in extended videos, we introduce a Co-Reasoning Director composed of three modality-specific large language model (LLM) experts. These experts reason about modality priorities and infer underlying user intent, converting inputs into detailed storylines through multi-turn dialogue. A Negative Director further refines negative prompts to improve instruction alignment. Building on these components, we extend the framework to support ID-specific multi-character control. Extensive experiments demonstrate that our model effectively addresses the challenges of efficient, multimodally aligned long-form high-resolution video generation, delivering enhanced visual clarity, realistic lip-teeth rendering with accurate lip synchronization, strong identity preservation, and coherent multimodal instruction following.
Kling-Avatar: Grounding Multimodal Instructions for Cascaded Long-Duration Avatar Animation Synthesis
Sep 11, 2025



Recent advances in audio-driven avatar video generation have significantly enhanced audio-visual realism. However, existing methods treat instruction conditioning merely as low-level tracking driven by acoustic or visual cues, without modeling the communicative purpose conveyed by the instructions. This limitation compromises their narrative coherence and character expressiveness. To bridge this gap, we introduce Kling-Avatar, a novel cascaded framework that unifies multimodal instruction understanding with photorealistic portrait generation. Our approach adopts a two-stage pipeline. In the first stage, we design a multimodal large language model (MLLM) director that produces a blueprint video conditioned on diverse instruction signals, thereby governing high-level semantics such as character motion and emotions. In the second stage, guided by blueprint keyframes, we generate multiple sub-clips in parallel using a first-last frame strategy. This global-to-local framework preserves fine-grained details while faithfully encoding the high-level intent behind multimodal instructions. Our parallel architecture also enables fast and stable generation of long-duration videos, making it suitable for real-world applications such as digital human livestreaming and vlogging. To comprehensively evaluate our method, we construct a benchmark of 375 curated samples covering diverse instructions and challenging scenarios. Extensive experiments demonstrate that Kling-Avatar is capable of generating vivid, fluent, long-duration videos at up to 1080p and 48 fps, achieving superior performance in lip synchronization accuracy, emotion and dynamic expressiveness, instruction controllability, identity preservation, and cross-domain generalization. These results establish Kling-Avatar as a new benchmark for semantically grounded, high-fidelity audio-driven avatar synthesis.
MIDAS: Multimodal Interactive Digital-humAn Synthesis via Real-time Autoregressive Video Generation
Aug 28, 2025Recently, interactive digital human video generation has attracted widespread attention and achieved remarkable progress. However, building such a practical system that can interact with diverse input signals in real time remains challenging to existing methods, which often struggle with heavy computational cost and limited controllability. In this work, we introduce an autoregressive video generation framework that enables interactive multimodal control and low-latency extrapolation in a streaming manner. With minimal modifications to a standard large language model (LLM), our framework accepts multimodal condition encodings including audio, pose, and text, and outputs spatially and semantically coherent representations to guide the denoising process of a diffusion head. To support this, we construct a large-scale dialogue dataset of approximately 20,000 hours from multiple sources, providing rich conversational scenarios for training. We further introduce a deep compression autoencoder with up to 64$\times$ reduction ratio, which effectively alleviates the long-horizon inference burden of the autoregressive model. Extensive experiments on duplex conversation, multilingual human synthesis, and interactive world model highlight the advantages of our approach in low latency, high efficiency, and fine-grained multimodal controllability.
Stereo 3D Gaussian Splatting SLAM for Outdoor Urban Scenes
Jul 31, 20253D Gaussian Splatting (3DGS) has recently gained popularity in SLAM applications due to its fast rendering and high-fidelity representation. However, existing 3DGS-SLAM systems have predominantly focused on indoor environments and relied on active depth sensors, leaving a gap for large-scale outdoor applications. We present BGS-SLAM, the first binocular 3D Gaussian Splatting SLAM system designed for outdoor scenarios. Our approach uses only RGB stereo pairs without requiring LiDAR or active sensors. BGS-SLAM leverages depth estimates from pre-trained deep stereo networks to guide 3D Gaussian optimization with a multi-loss strategy enhancing both geometric consistency and visual quality. Experiments on multiple datasets demonstrate that BGS-SLAM achieves superior tracking accuracy and mapping performance compared to other 3DGS-based solutions in complex outdoor environments.
Ov3R: Open-Vocabulary Semantic 3D Reconstruction from RGB Videos
Jul 29, 2025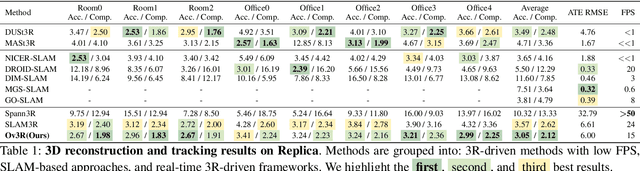
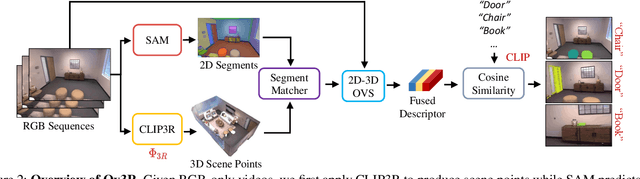

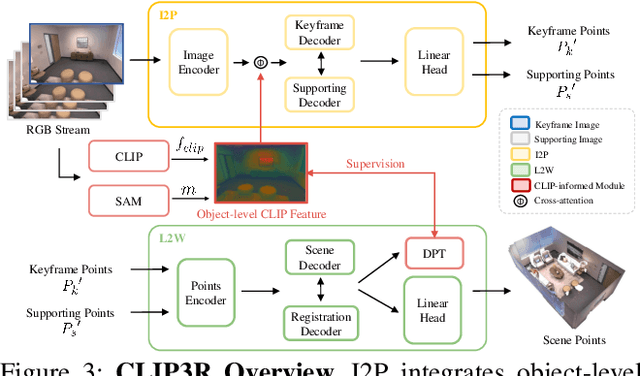
We present Ov3R, a novel framework for open-vocabulary semantic 3D reconstruction from RGB video streams, designed to advance Spatial AI. The system features two key components: CLIP3R, a CLIP-informed 3D reconstruction module that predicts dense point maps from overlapping clips while embedding object-level semantics; and 2D-3D OVS, a 2D-3D open-vocabulary semantic module that lifts 2D features into 3D by learning fused descriptors integrating spatial, geometric, and semantic cues. Unlike prior methods, Ov3R incorporates CLIP semantics directly into the reconstruction process, enabling globally consistent geometry and fine-grained semantic alignment. Our framework achieves state-of-the-art performance in both dense 3D reconstruction and open-vocabulary 3D segmentation, marking a step forward toward real-time, semantics-aware Spatial AI.
Natural Language Generation in Healthcare: A Review of Methods and Applications
May 07, 2025Natural language generation (NLG) is the key technology to achieve generative artificial intelligence (AI). With the breakthroughs in large language models (LLMs), NLG has been widely used in various medical applications, demonstrating the potential to enhance clinical workflows, support clinical decision-making, and improve clinical documentation. Heterogeneous and diverse medical data modalities, such as medical text, images, and knowledge bases, are utilized in NLG. Researchers have proposed many generative models and applied them in a number of healthcare applications. There is a need for a comprehensive review of NLG methods and applications in the medical domain. In this study, we systematically reviewed 113 scientific publications from a total of 3,988 NLG-related articles identified using a literature search, focusing on data modality, model architecture, clinical applications, and evaluation methods. Following PRISMA (Preferred Reporting Items for Systematic reviews and Meta-Analyses) guidelines, we categorize key methods, identify clinical applications, and assess their capabilities, limitations, and emerging challenges. This timely review covers the key NLG technologies and medical applications and provides valuable insights for future studies to leverage NLG to transform medical discovery and healthcare.
Bayesian Reasoning Enabled by Spin-Orbit Torque Magnetic Tunnel Junctions
Apr 11, 2025



Bayesian networks play an increasingly important role in data mining, inference, and reasoning with the rapid development of artificial intelligence. In this paper, we present proof-of-concept experiments demonstrating the use of spin-orbit torque magnetic tunnel junctions (SOT-MTJs) in Bayesian network reasoning. Not only can the target probability distribution function (PDF) of a Bayesian network be precisely formulated by a conditional probability table as usual but also quantitatively parameterized by a probabilistic forward propagating neuron network. Moreover, the parameters of the network can also approach the optimum through a simple point-by point training algorithm, by leveraging which we do not need to memorize all historical data nor statistically summarize conditional probabilities behind them, significantly improving storage efficiency and economizing data pretreatment. Furthermore, we developed a simple medical diagnostic system using the SOT-MTJ as a random number generator and sampler, showcasing the application of SOT-MTJ-based Bayesian reasoning. This SOT-MTJ-based Bayesian reasoning shows great promise in the field of artificial probabilistic neural network, broadening the scope of spintronic device applications and providing an efficient and low-storage solution for complex reasoning tasks.