 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo 3D Gaussian Splatting SLAM for Outdoor Urban Scenes
Jul 31, 20253D Gaussian Splatting (3DGS) has recently gained popularity in SLAM applications due to its fast rendering and high-fidelity representation. However, existing 3DGS-SLAM systems have predominantly focused on indoor environments and relied on active depth sensors, leaving a gap for large-scale outdoor applications. We present BGS-SLAM, the first binocular 3D Gaussian Splatting SLAM system designed for outdoor scenarios. Our approach uses only RGB stereo pairs without requiring LiDAR or active sensors. BGS-SLAM leverages depth estimates from pre-trained deep stereo networks to guide 3D Gaussian optimization with a multi-loss strategy enhancing both geometric consistency and visual quality. Experiments on multiple datasets demonstrate that BGS-SLAM achieves superior tracking accuracy and mapping performance compared to other 3DGS-based solutions in complex outdoor environments.
Ov3R: Open-Vocabulary Semantic 3D Reconstruction from RGB Videos
Jul 29, 2025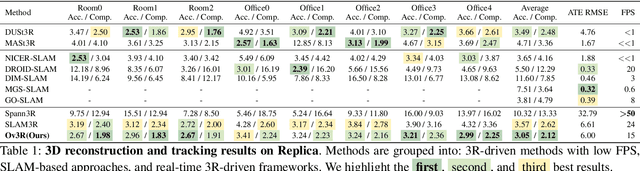
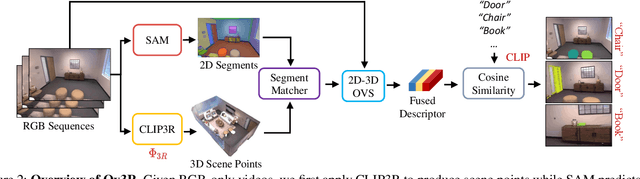

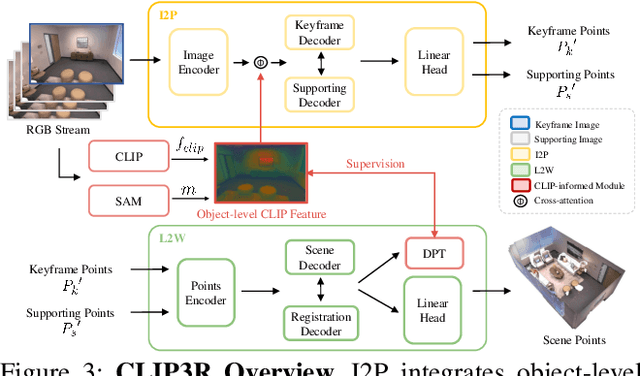
We present Ov3R, a novel framework for open-vocabulary semantic 3D reconstruction from RGB video streams, designed to advance Spatial AI. The system features two key components: CLIP3R, a CLIP-informed 3D reconstruction module that predicts dense point maps from overlapping clips while embedding object-level semantics; and 2D-3D OVS, a 2D-3D open-vocabulary semantic module that lifts 2D features into 3D by learning fused descriptors integrating spatial, geometric, and semantic cues. Unlike prior methods, Ov3R incorporates CLIP semantics directly into the reconstruction process, enabling globally consistent geometry and fine-grained semantic alignment. Our framework achieves state-of-the-art performance in both dense 3D reconstruction and open-vocabulary 3D segmentation, marking a step forward toward real-time, semantics-aware Spatial AI.
HS-SLAM: Hybrid Representation with Structural Supervision for Improved Dense SLAM
Mar 27, 2025NeRF-based SLAM has recently achieved promising results in tracking and reconstruction. However, existing methods face challenges in providing sufficient scene representation, capturing structural information, and maintaining global consistency in scenes emerging significant movement or being forgotten. To this end, we present HS-SLAM to tackle these problems. To enhance scene representation capacity, we propose a hybrid encoding network that combines the complementary strengths of hash-grid, tri-planes, and one-blob, improving the completeness and smoothness of reconstruction. Additionally, we introduce structural supervision by sampling patches of non-local pixels rather than individual rays to better capture the scene structure. To ensure global consistency, we implement an active global bundle adjustment (BA) to eliminate camera drifts and mitigate accumulative errors. Experimental results demonstrate that HS-SLAM outperforms the baselines in tracking and reconstruction accuracy while maintaining the efficiency required for robotics.
How NeRFs and 3D Gaussian Splatting are Reshaping SLAM: a Survey
Feb 20, 2024Over the past two decades, research in the field of Simultaneous Localization and Mapping (SLAM) has undergone a significant evolution, highlighting its critical role in enabling autonomous exploration of unknown environments. This evolution ranges from hand-crafted methods, through the era of deep learning, to more recent developments focused on Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (3DGS) representations. Recognizing the growing body of research and the absence of a comprehensive survey on the topic, this paper aims to provide the first comprehensive overview of SLAM progress through the lens of the latest advancements in radiance fields. It sheds light on the background, evolutionary path, inherent strengths and limitations, and serves as a fundamental reference to highlight the dynamic progress and specific challenges.
ProBio: A Protocol-guided Multimodal Dataset for Molecular Biology Lab
Nov 01, 2023The challenge of replicating research results has posed a significant impediment to the field of molecular biology. The advent of modern intelligent systems has led to notable progress in various domains. Consequently, we embarked on an investigation of intelligent monitoring systems as a means of tackling the issue of the reproducibility crisis. Specifically, we first curate a comprehensive multimodal dataset, named ProBio, as an initial step towards this objective. This dataset comprises fine-grained hierarchical annotations intended for the purpose of studying activity understanding in BioLab. Next, we devise two challenging benchmarks, transparent solution tracking and multimodal action recognition, to emphasize the unique characteristics and difficulties associated with activity understanding in BioLab settings. Finally, we provide a thorough experimental evaluation of contemporary video understanding models and highlight their limitations in this specialized domain to identify potential avenues for future research. We hope ProBio with associated benchmarks may garner increased focus on modern AI techniques in the realm of molecular biology.