 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Inference Consistent Segmented Execution for Long-Context LLMs
May 12, 2026Transformer-based large language models face severe scalability challenges in long-context generation due to the computational and memory costs of full-context attention. Under practical computation and memory constraints, many inference-efficient long-context methods improve efficiency by adopting bounded-context or segment-level execution only during inference, while continuing to train models under full-context attention, resulting in a mismatch between training and inference execution and state-transition semantics. Based on this insight, we propose a training-inference consistent segment-level generation framework, in which training and inference follow the same segment-level forward execution semantics. During training, consistency with inference is enforced by restricting gradient propagation to KV states carried over from the immediately preceding segment, while permitting head-specific access to past KV states during the forward pass without involving them in gradient propagation. Across long-context benchmarks, our approach achieves performance comparable to full-context attention, while achieving competitive latency-memory trade-offs against strong inference-efficient baselines, and substantially improving scalability at very long context lengths (e.g., approximately 6x lower peak prefill memory at 128K compared to full-context attention with FlashAttention).
Who Wrote This Line? Evaluating the Detection of LLM-Generated Classical Chinese Poetry
Apr 11, 2026The rapid development of large language models (LLMs) has extended text generation tasks into the literary domain. However, AI-generated literary creations has raised increasingly prominent issues of creative authenticity and ethics in literary world, making the detection of LLM-generated literary texts essential and urgent. While previous works have made significant progress in detecting AI-generated text, it has yet to address classical Chinese poetry. Due to the unique linguistic features of classical Chinese poetry, such as strict metrical regularity, a shared system of poetic imagery, and flexible syntax, distinguishing whether a poem is authored by AI presents a substantial challenge. To address these issues, we introduce ChangAn, a benchmark for detecting LLM-generated classical Chinese poetry that containing total 30,664 poems, 10,276 are human-written poems and 20,388 poems are generated by four popular LLMs. Based on ChangAn, we conducted a systematic evaluation of 12 AI detectors, investigating their performance variations across different text granularities and generation strategies. Our findings highlight the limitations of current Chinese text detectors, which fail to serve as reliable tools for detecting LLM-generated classical Chinese poetry. These results validate the effectiveness and necessity of our proposed ChangAn benchmark. Our dataset and code are available at https://github.com/VelikayaScarlet/ChangAn.
McBE: A Multi-task Chinese Bias Evaluation Benchmark for Large Language Models
Jul 02, 2025As large language models (LLMs) are increasingly applied to various NLP tasks, their inherent biases are gradually disclosed. Therefore, measuring biases in LLMs is crucial to mitigate its ethical risks. However, most existing bias evaluation datasets focus on English and North American culture, and their bias categories are not fully applicable to other cultures. The datasets grounded in the Chinese language and culture are scarce. More importantly, these datasets usually only support single evaluation tasks and cannot evaluate the bias from multiple aspects in LLMs. To address these issues, we present a Multi-task Chinese Bias Evaluation Benchmark (McBE) that includes 4,077 bias evaluation instances, covering 12 single bias categories, 82 subcategories and introducing 5 evaluation tasks, providing extensive category coverage, content diversity, and measuring comprehensiveness. Additionally, we evaluate several popular LLMs from different series and with parameter sizes. In general, all these LLMs demonstrated varying degrees of bias. We conduct an in-depth analysis of results, offering novel insights into bias in LLMs.
Mitigating Heterogeneity among Factor Tensors via Lie Group Manifolds for Tensor Decomposition Based Temporal Knowledge Graph Embedding
Apr 14, 2024



Recent studies have highlighted the effectiveness of tensor decomposition methods in the Temporal Knowledge Graphs Embedding (TKGE) task. However, we found that inherent heterogeneity among factor tensors in tensor decomposition significantly hinders the tensor fusion process and further limits the performance of link prediction. To overcome this limitation, we introduce a novel method that maps factor tensors onto a unified smooth Lie group manifold to make the distribution of factor tensors approximating homogeneous in tensor decomposition. We provide the theoretical proof of our motivation that homogeneous tensors are more effective than heterogeneous tensors in tensor fusion and approximating the target for tensor decomposition based TKGE methods. The proposed method can be directly integrated into existing tensor decomposition based TKGE methods without introducing extra parameters. Extensive experiments demonstrate the effectiveness of our method in mitigating the heterogeneity and in enhancing the tensor decomposition based TKGE models.
Ensuring Safe and High-Quality Outputs: A Guideline Library Approach for Language Models
Mar 23, 2024Large Language Models (LLMs) exhibit impressive capabilities but also present risks such as biased content generation and privacy issues. One of the current alignment techniques includes principle-driven integration, but it faces challenges arising from the imprecision of manually crafted rules and inadequate risk perception in models without safety training. To address these, we introduce Guide-Align, a two-stage approach. Initially, a safety-trained model identifies potential risks and formulates specific guidelines for various inputs, establishing a comprehensive library of guidelines and a model for input-guidelines retrieval. Subsequently, the retrieval model correlates new inputs with relevant guidelines, which guide LLMs in response generation to ensure safe and high-quality outputs, thereby aligning with human values. An additional optional stage involves fine-tuning a model with well-aligned datasets generated through the process implemented in the second stage. Our method customizes guidelines to accommodate diverse inputs, thereby enhancing the fine-grainedness and comprehensiveness of the guideline library. Furthermore, it incorporates safety expertise from a safety-trained LLM through a lightweight retrieval model. We evaluate our approach on three benchmarks, demonstrating significant improvements in LLM security and quality. Notably, our fine-tuned model, Labrador, even at 13 billion parameters, outperforms GPT-3.5-turbo and surpasses GPT-4 in alignment capabilities.
Improving CTC-AED model with integrated-CTC and auxiliary loss regularization
Aug 15, 2023Connectionist temporal classification (CTC) and attention-based encoder decoder (AED) joint training has been widely applied in automatic speech recognition (ASR). Unlike most hybrid models that separately calculate the CTC and AED losses, our proposed integrated-CTC utilizes the attention mechanism of AED to guide the output of CTC. In this paper, we employ two fusion methods, namely direct addition of logits (DAL) and preserving the maximum probability (PMP). We achieve dimensional consistency by adaptively affine transforming the attention results to match the dimensions of CTC. To accelerate model convergence and improve accuracy, we introduce auxiliary loss regularization for accelerated convergence. Experimental results demonstrate that the DAL method performs better in attention rescoring, while the PMP method excels in CTC prefix beam search and greedy search.
TransERR: Translation-based Knowledge Graph Completion via Efficient Relation Rotation
Jun 26, 2023This paper presents translation-based knowledge graph completion method via efficient relation rotation (TransERR), a straightforward yet effective alternative to traditional translation-based knowledge graph completion models. Different from the previous translation-based models, TransERR encodes knowledge graphs in the hypercomplex-valued space, thus enabling it to possess a higher degree of translation freedom in mining latent information between the head and tail entities. To further minimize the translation distance, TransERR adaptively rotates the head entity and the tail entity with their corresponding unit quaternions, which are learnable in model training. The experiments on 7 benchmark datasets validate the effectiveness and the generalization of TransERR. The results also indicate that TransERR can better encode large-scale datasets with fewer parameters than the previous translation-based models. Our code is available at: \url{https://github.com/dellixx/TransERR}.
Coarse-to-Fine Recursive Speech Separation for Unknown Number of Speakers
Mar 30, 2022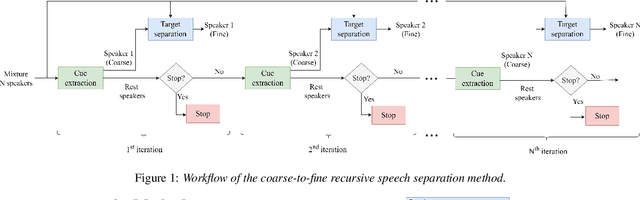
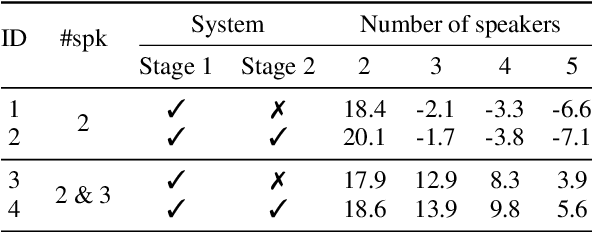
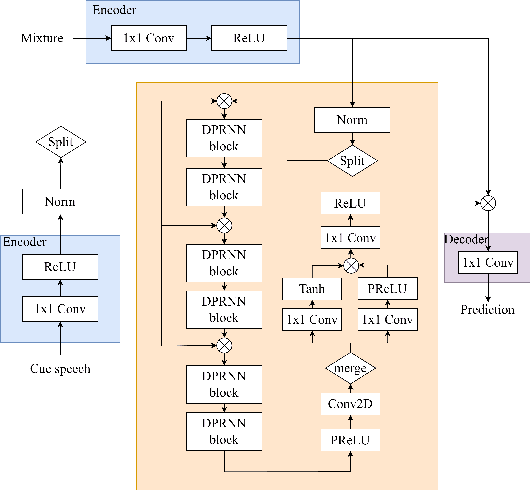
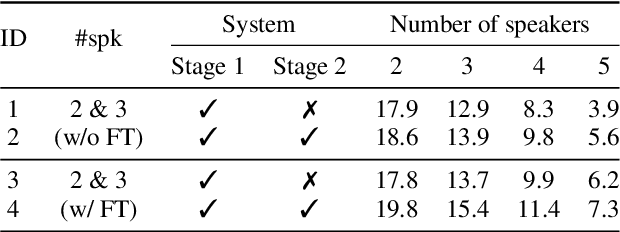
The vast majority of speech separation methods assume that the number of speakers is known in advance, hence they are specific to the number of speakers. By contrast, a more realistic and challenging task is to separate a mixture in which the number of speakers is unknown. This paper formulates the speech separation with the unknown number of speakers as a multi-pass source extraction problem and proposes a coarse-to-fine recursive speech separation method. This method comprises two stages, namely, recursive cue extraction and target speaker extraction. The recursive cue extraction stage determines how many computational iterations need to be performed and outputs a coarse cue speech by monitoring statistics in the mixture. As the number of recursive iterations increases, the accumulation of distortion eventually comes into the extracted speech and reminder. Therefore, in the second stage, we use a target speaker extraction network to extract a fine speech based on the coarse target cue and the original distortionless mixture. Experiments show that the proposed method archived state-of-the-art performance on the WSJ0 dataset with a different number of speakers. Furthermore, it generalizes well to an unseen large number of speakers.
An Edge Information and Mask Shrinking Based Image Inpainting Approach
Jun 11, 2020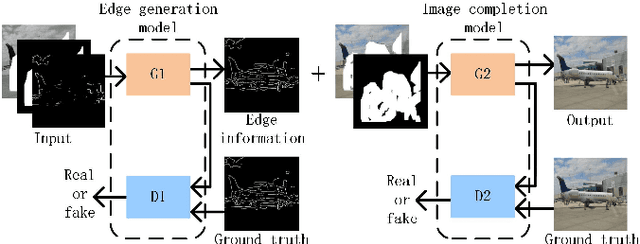
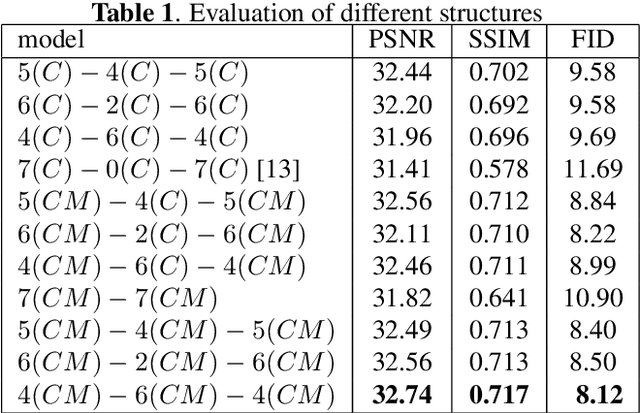
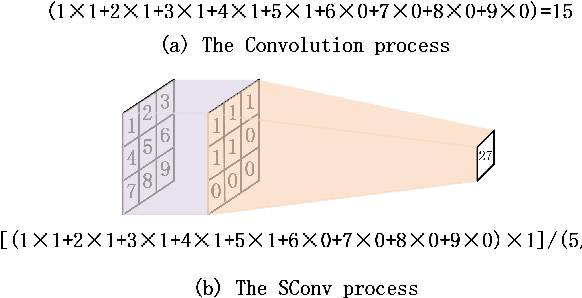
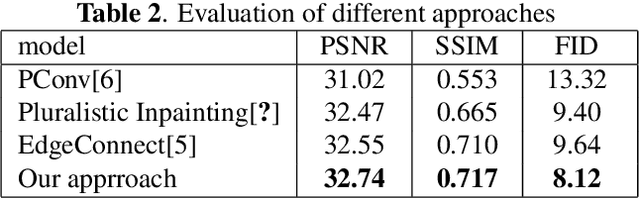
In the image inpainting task, the ability to repair both high-frequency and low-frequency information in the missing regions has a substantial influence on the quality of the restored image. However, existing inpainting methods usually fail to consider both high-frequency and low-frequency information simultaneously. To solve this problem, this paper proposes edge information and mask shrinking based image inpainting approach, which consists of two models. The first model is an edge generation model used to generate complete edge information from the damaged image, and the second model is an image completion model used to fix the missing regions with the generated edge information and the valid contents of the damaged image. The mask shrinking strategy is employed in the image completion model to track the areas to be repaired. The proposed approach is evaluated qualitatively and quantitatively on the dataset Places2. The result shows our approach outperforms state-of-the-art methods.
SNR-based teachers-student technique for speech enhancement
May 29, 2020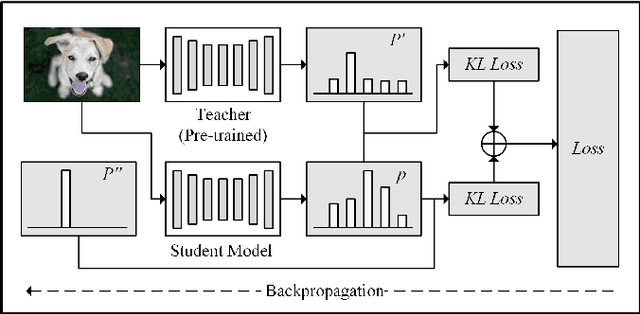
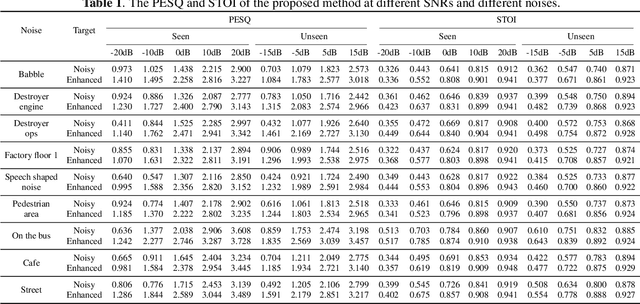
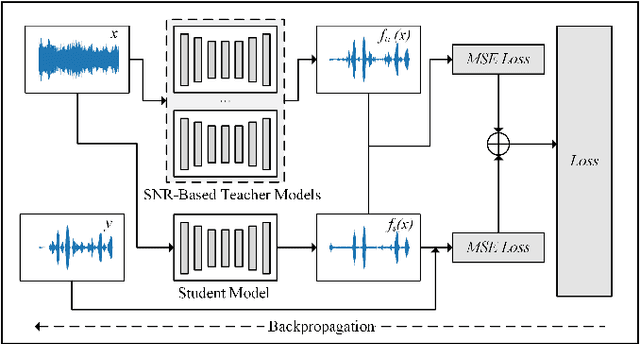
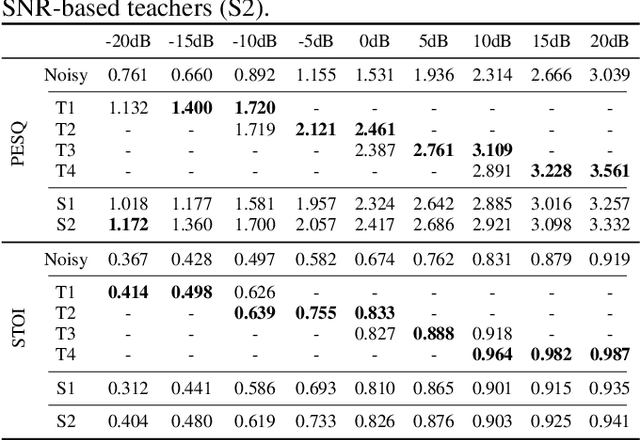
It is very challenging for speech enhancement methods to achieves robust performance under both high signal-to-noise ratio (SNR) and low SNR simultaneously. In this paper, we propose a method that integrates an SNR-based teachers-student technique and time-domain U-Net to deal with this problem. Specifically, this method consists of multiple teacher models and a student model. We first train the teacher models under multiple small-range SNRs that do not coincide with each other so that they can perform speech enhancement well within the specific SNR range. Then, we choose different teacher models to supervise the training of the student model according to the SNR of the training data. Eventually, the student model can perform speech enhancement under both high SNR and low SNR. To evaluate the proposed method, we constructed a dataset with an SNR ranging from -20dB to 20dB based on the public dataset. We experimentally analyzed the effectiveness of the SNR-based teachers-student technique and compared the proposed method with several state-of-the-art methods.