 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRynnBrain: Open Embodied Foundation Models
Feb 13, 2026Despite rapid progress in multimodal foundation models, embodied intelligence community still lacks a unified, physically grounded foundation model that integrates perception, reasoning, and planning within real-world spatial-temporal dynamics. We introduce RynnBrain, an open-source spatiotemporal foundation model for embodied intelligence. RynnBrain strengthens four core capabilities in a unified framework: comprehensive egocentric understanding, diverse spatiotemporal localization, physically grounded reasoning, and physics-aware planning. The RynnBrain family comprises three foundation model scales (2B, 8B, and 30B-A3B MoE) and four post-trained variants tailored for downstream embodied tasks (i.e., RynnBrain-Nav, RynnBrain-Plan, and RynnBrain-VLA) or complex spatial reasoning tasks (i.e., RynnBrain-CoP). In terms of extensive evaluations on 20 embodied benchmarks and 8 general vision understanding benchmarks, our RynnBrain foundation models largely outperform existing embodied foundation models by a significant margin. The post-trained model suite further substantiates two key potentials of the RynnBrain foundation model: (i) enabling physically grounded reasoning and planning, and (ii) serving as a strong pretrained backbone that can be efficiently adapted to diverse embodied tasks.
FastVMT: Eliminating Redundancy in Video Motion Transfer
Feb 05, 2026Video motion transfer aims to synthesize videos by generating visual content according to a text prompt while transferring the motion pattern observed in a reference video. Recent methods predominantly use the Diffusion Transformer (DiT) architecture. To achieve satisfactory runtime, several methods attempt to accelerate the computations in the DiT, but fail to address structural sources of inefficiency. In this work, we identify and remove two types of computational redundancy in earlier work: motion redundancy arises because the generic DiT architecture does not reflect the fact that frame-to-frame motion is small and smooth; gradient redundancy occurs if one ignores that gradients change slowly along the diffusion trajectory. To mitigate motion redundancy, we mask the corresponding attention layers to a local neighborhood such that interaction weights are not computed unnecessarily distant image regions. To exploit gradient redundancy, we design an optimization scheme that reuses gradients from previous diffusion steps and skips unwarranted gradient computations. On average, FastVMT achieves a 3.43x speedup without degrading the visual fidelity or the temporal consistency of the generated videos.
Frequency-aware Adaptive Contrastive Learning for Sequential Recommendation
Jan 22, 2026In this paper, we revisited the role of data augmentation in contrastive learning for sequential recommendation, revealing its inherent bias against low-frequency items and sparse user behaviors. To address this limitation, we proposed FACL, a frequency-aware adaptive contrastive learning framework that introduces micro-level adaptive perturbation to protect the integrity of rare items, as well as macro-level reweighting to amplify the influence of sparse and rare-interaction sequences during training. Comprehensive experiments on five public benchmark datasets demonstrated that FACL consistently outperforms state-of-the-art data augmentation and model augmentation-based methods, achieving up to 3.8% improvement in recommendation accuracy. Moreover, fine-grained analyses confirm that FACL significantly alleviates the performance drop on low-frequency items and users, highlighting its robust intent-preserving ability and its superior applicability to real-world, long-tail recommendation scenarios.
RynnEC: Bringing MLLMs into Embodied World
Aug 19, 2025We introduce RynnEC, a video multimodal large language model designed for embodied cognition. Built upon a general-purpose vision-language foundation model, RynnEC incorporates a region encoder and a mask decoder, enabling flexible region-level video interaction. Despite its compact architecture, RynnEC achieves state-of-the-art performance in object property understanding, object segmentation, and spatial reasoning. Conceptually, it offers a region-centric video paradigm for the brain of embodied agents, providing fine-grained perception of the physical world and enabling more precise interactions. To mitigate the scarcity of annotated 3D datasets, we propose an egocentric video based pipeline for generating embodied cognition data. Furthermore, we introduce RynnEC-Bench, a region-centered benchmark for evaluating embodied cognitive capabilities. We anticipate that RynnEC will advance the development of general-purpose cognitive cores for embodied agents and facilitate generalization across diverse embodied tasks. The code, model checkpoints, and benchmark are available at: https://github.com/alibaba-damo-academy/RynnEC
A Framework for Elastic Adaptation of User Multiple Intents in Sequential Recommendation
Apr 30, 2025Recently, substantial research has been conducted on sequential recommendation, with the objective of forecasting the subsequent item by leveraging a user's historical sequence of interacted items. Prior studies employ both capsule networks and self-attention techniques to effectively capture diverse underlying intents within a user's interaction sequence, thereby achieving the most advanced performance in sequential recommendation. However, users could potentially form novel intents from fresh interactions as the lengths of user interaction sequences grow. Consequently, models need to be continually updated or even extended to adeptly encompass these emerging user intents, referred as incremental multi-intent sequential recommendation. % We refer to this problem as incremental multi-intent sequential recommendation, which has not yet been well investigated in the existing literature. In this paper, we propose an effective Incremental learning framework for user Multi-intent Adaptation in sequential recommendation called IMA, which augments the traditional fine-tuning strategy with the existing-intents retainer, new-intents detector, and projection-based intents trimmer to adaptively expand the model to accommodate user's new intents and prevent it from forgetting user's existing intents. Furthermore, we upgrade the IMA into an Elastic Multi-intent Adaptation (EMA) framework which can elastically remove inactive intents and compress user intent vectors under memory space limit. Extensive experiments on real-world datasets verify the effectiveness of the proposed IMA and EMA on incremental multi-intent sequential recommendation, compared with various baselines.
Benchmarking Multimodal Mathematical Reasoning with Explicit Visual Dependency
Apr 29, 2025Recent advancements in Large Vision-Language Models (LVLMs) have significantly enhanced their ability to integrate visual and linguistic information, achieving near-human proficiency in tasks like object recognition, captioning, and visual question answering. However, current benchmarks typically focus on knowledge-centric evaluations that assess domain-specific expertise, often neglecting the core ability to reason about fundamental mathematical elements and visual concepts. We identify a gap in evaluating elementary-level math problems, which rely on explicit visual dependencies-requiring models to discern, integrate, and reason across multiple images while incorporating commonsense knowledge, all of which are crucial for advancing toward broader AGI capabilities. To address this gap, we introduce VCBENCH, a comprehensive benchmark for multimodal mathematical reasoning with explicit visual dependencies. VCBENCH includes 1,720 problems across six cognitive domains, featuring 6,697 images (averaging 3.9 per question) to ensure multi-image reasoning. We evaluate 26 state-of-the-art LVLMs on VCBENCH, revealing substantial performance disparities, with even the top models unable to exceed 50% accuracy. Our findings highlight the ongoing challenges in visual-mathematical integration and suggest avenues for future LVLM advancements.
Feature Staleness Aware Incremental Learning for CTR Prediction
Apr 29, 2025



Click-through Rate (CTR) prediction in real-world recommender systems often deals with billions of user interactions every day. To improve the training efficiency, it is common to update the CTR prediction model incrementally using the new incremental data and a subset of historical data. However, the feature embeddings of a CTR prediction model often get stale when the corresponding features do not appear in current incremental data. In the next period, the model would have a performance degradation on samples containing stale features, which we call the feature staleness problem. To mitigate this problem, we propose a Feature Staleness Aware Incremental Learning method for CTR prediction (FeSAIL) which adaptively replays samples containing stale features. We first introduce a staleness aware sampling algorithm (SAS) to sample a fixed number of stale samples with high sampling efficiency. We then introduce a staleness aware regularization mechanism (SAR) for a fine-grained control of the feature embedding updating. We instantiate FeSAIL with a general deep learning-based CTR prediction model and the experimental results demonstrate FeSAIL outperforms various state-of-the-art methods on four benchmark datasets.
Relative Contrastive Learning for Sequential Recommendation with Similarity-based Positive Pair Selection
Apr 27, 2025Contrastive Learning (CL) enhances the training of sequential recommendation (SR) models through informative self-supervision signals. Existing methods often rely on data augmentation strategies to create positive samples and promote representation invariance. Some strategies such as item reordering and item substitution may inadvertently alter user intent. Supervised Contrastive Learning (SCL) based methods find an alternative to augmentation-based CL methods by selecting same-target sequences (interaction sequences with the same target item) to form positive samples. However, SCL-based methods suffer from the scarcity of same-target sequences and consequently lack enough signals for contrastive learning. In this work, we propose to use similar sequences (with different target items) as additional positive samples and introduce a Relative Contrastive Learning (RCL) framework for sequential recommendation. RCL comprises a dual-tiered positive sample selection module and a relative contrastive learning module. The former module selects same-target sequences as strong positive samples and selects similar sequences as weak positive samples. The latter module employs a weighted relative contrastive loss, ensuring that each sequence is represented closer to its strong positive samples than its weak positive samples. We apply RCL on two mainstream deep learning-based SR models, and our empirical results reveal that RCL can achieve 4.88% improvement averagely than the state-of-the-art SR methods on five public datasets and one private dataset.
Fault Tolerant Free Gait and Footstep Planning for Hexapod Robot Based on Monte-Carlo Tree
Jun 16, 2020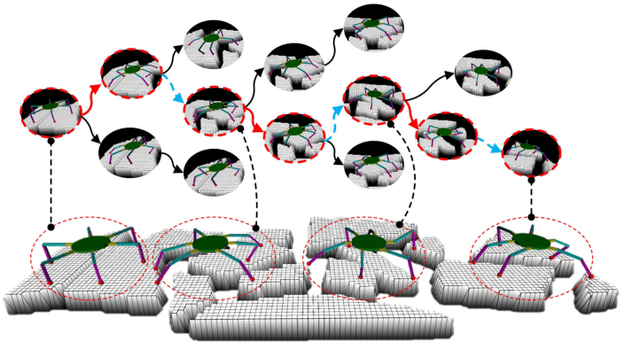
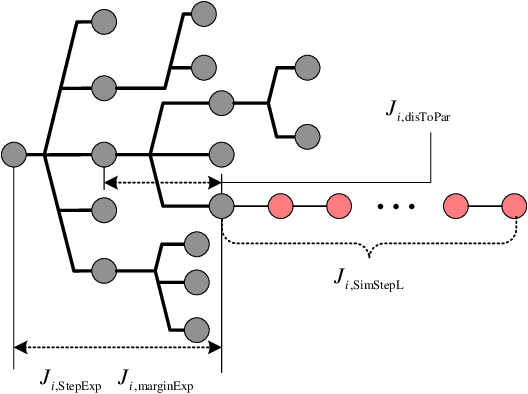
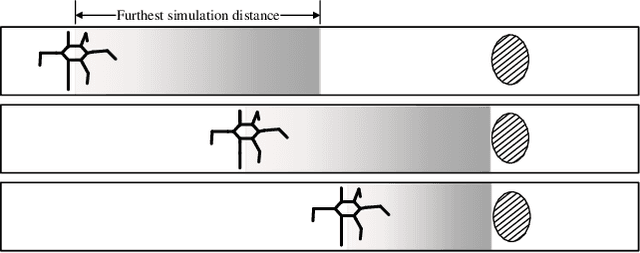

Legged robots can pass through complex field environments by selecting gaits and discrete footholds carefully. Traditional methods plan gait and foothold separately and treat them as the single-step optimal process. However, such processing causes its poor passability in a sparse foothold environment. This paper novelly proposes a coordinative planning method for hexapod robots that regards the planning of gait and foothold as a sequence optimization problem with the consideration of dealing with the harshness of the environment as leg fault. The Monte Carlo tree search algorithm(MCTS) is used to optimize the entire sequence. Two methods, FastMCTS, and SlidingMCTS are proposed to solve some defeats of the standard MCTS applicating in the field of legged robot planning. The proposed planning algorithm combines the fault-tolerant gait method to improve the passability of the algorithm. Finally, compared with other planning methods, experiments on terrains with different densities of footholds and artificially-designed challenging terrain are carried out to verify our methods. All results show that the proposed method dramatically improves the hexapod robot's ability to pass through sparse footholds environment.