 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoReMi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment
Jul 01, 2023



Large language models encode a vast amount of semantic knowledge and possess remarkable understanding and reasoning capabilities. Previous research has explored how to ground language models in robotic tasks to ensure that the sequences generated by the language model are both logically correct and practically executable. However, low-level execution may deviate from the high-level plan due to environmental perturbations or imperfect controller design. In this paper, we propose DoReMi, a novel language model grounding framework that enables immediate Detection and Recovery from Misalignments between plan and execution. Specifically, during low-level skill execution, we use a vision question answering (VQA) model to regularly detect plan-execution misalignments. If certain misalignment occurs, our method will call the language model to re-plan in order to recover from misalignments. Experiments on various complex tasks including robot arms and humanoid robots demonstrate that our method can lead to higher task success rates and shorter task completion times. Videos of DoReMi are available at https://sites.google.com/view/doremi-paper.
Decentralized Motor Skill Learning for Complex Robotic Systems
Jun 30, 2023Reinforcement learning (RL) has achieved remarkable success in complex robotic systems (eg. quadruped locomotion). In previous works, the RL-based controller was typically implemented as a single neural network with concatenated observation input. However, the corresponding learned policy is highly task-specific. Since all motors are controlled in a centralized way, out-of-distribution local observations can impact global motors through the single coupled neural network policy. In contrast, animals and humans can control their limbs separately. Inspired by this biological phenomenon, we propose a Decentralized motor skill (DEMOS) learning algorithm to automatically discover motor groups that can be decoupled from each other while preserving essential connections and then learn a decentralized motor control policy. Our method improves the robustness and generalization of the policy without sacrificing performance. Experiments on quadruped and humanoid robots demonstrate that the learned policy is robust against local motor malfunctions and can be transferred to new tasks.
Asking Before Action: Gather Information in Embodied Decision Making with Language Models
May 25, 2023With strong capabilities of reasoning and a generic understanding of the world, Large Language Models (LLMs) have shown great potential in building versatile embodied decision making agents capable of performing diverse tasks. However, when deployed to unfamiliar environments, we show that LLM agents face challenges in efficiently gathering necessary information, leading to suboptimal performance. On the other hand, in unfamiliar scenarios, human individuals often seek additional information from their peers before taking action, leveraging external knowledge to avoid unnecessary trial and error. Building upon this intuition, we propose \textit{Asking Before Action} (ABA), a method that empowers the agent to proactively query external sources for pertinent information using natural language during their interactions in the environment. In this way, the agent is able to enhance its efficiency and performance by mitigating wasteful steps and circumventing the difficulties associated with exploration in unfamiliar environments. We empirically evaluate our method on an embodied decision making benchmark, ALFWorld, and demonstrate that despite modest modifications in prompts, our method exceeds baseline LLM agents by more than $40$%. Further experiments on two variants of ALFWorld illustrate that by imitation learning, ABA effectively retains and reuses queried and known information in subsequent tasks, mitigating the need for repetitive inquiries. Both qualitative and quantitative results exhibit remarkable performance on tasks that previous methods struggle to solve.
AMP in the wild: Learning robust, agile, natural legged locomotion skills
Apr 21, 2023



The successful transfer of a learned controller from simulation to the real world for a legged robot requires not only the ability to identify the system, but also accurate estimation of the robot's state. In this paper, we propose a novel algorithm that can infer not only information about the parameters of the dynamic system, but also estimate important information about the robot's state from previous observations. We integrate our algorithm with Adversarial Motion Priors and achieve a robust, agile, and natural gait in both simulation and on a Unitree A1 quadruped robot in the real world. Empirical results demonstrate that our proposed algorithm enables traversing challenging terrains with lower power consumption compared to the baselines. Both qualitative and quantitative results are presented in this paper.
An Adaptive Deep RL Method for Non-Stationary Environments with Piecewise Stable Context
Dec 24, 2022One of the key challenges in deploying RL to real-world applications is to adapt to variations of unknown environment contexts, such as changing terrains in robotic tasks and fluctuated bandwidth in congestion control. Existing works on adaptation to unknown environment contexts either assume the contexts are the same for the whole episode or assume the context variables are Markovian. However, in many real-world applications, the environment context usually stays stable for a stochastic period and then changes in an abrupt and unpredictable manner within an episode, resulting in a segment structure, which existing works fail to address. To leverage the segment structure of piecewise stable context in real-world applications, in this paper, we propose a \textit{\textbf{Se}gmented \textbf{C}ontext \textbf{B}elief \textbf{A}ugmented \textbf{D}eep~(SeCBAD)} RL method. Our method can jointly infer the belief distribution over latent context with the posterior over segment length and perform more accurate belief context inference with observed data within the current context segment. The inferred belief context can be leveraged to augment the state, leading to a policy that can adapt to abrupt variations in context. We demonstrate empirically that SeCBAD can infer context segment length accurately and outperform existing methods on a toy grid world environment and Mujuco tasks with piecewise-stable context.
Reinforcement learning with Demonstrations from Mismatched Task under Sparse Reward
Dec 03, 2022



Reinforcement learning often suffer from the sparse reward issue in real-world robotics problems. Learning from demonstration (LfD) is an effective way to eliminate this problem, which leverages collected expert data to aid online learning. Prior works often assume that the learning agent and the expert aim to accomplish the same task, which requires collecting new data for every new task. In this paper, we consider the case where the target task is mismatched from but similar with that of the expert. Such setting can be challenging and we found existing LfD methods can not effectively guide learning in mismatched new tasks with sparse rewards. We propose conservative reward shaping from demonstration (CRSfD), which shapes the sparse rewards using estimated expert value function. To accelerate learning processes, CRSfD guides the agent to conservatively explore around demonstrations. Experimental results of robot manipulation tasks show that our approach outperforms baseline LfD methods when transferring demonstrations collected in a single task to other different but similar tasks.
Safe Model-Based Reinforcement Learning with an Uncertainty-Aware Reachability Certificate
Oct 14, 2022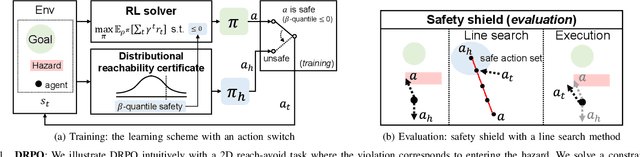
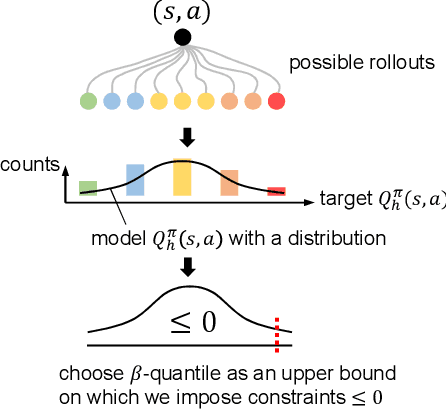
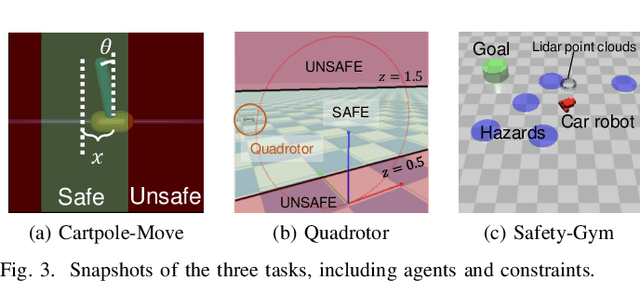
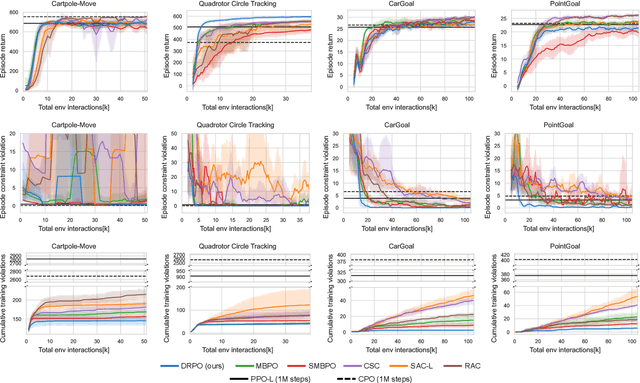
Safe reinforcement learning (RL) that solves constraint-satisfactory policies provides a promising way to the broader safety-critical applications of RL in real-world problems such as robotics. Among all safe RL approaches, model-based methods reduce training time violations further due to their high sample efficiency. However, lacking safety robustness against the model uncertainties remains an issue in safe model-based RL, especially in training time safety. In this paper, we propose a distributional reachability certificate (DRC) and its Bellman equation to address model uncertainties and characterize robust persistently safe states. Furthermore, we build a safe RL framework to resolve constraints required by the DRC and its corresponding shield policy. We also devise a line search method to maintain safety and reach higher returns simultaneously while leveraging the shield policy. Comprehensive experiments on classical benchmarks such as constrained tracking and navigation indicate that the proposed algorithm achieves comparable returns with much fewer constraint violations during training.
Decomposed Mutual Information Optimization for Generalized Context in Meta-Reinforcement Learning
Oct 09, 2022
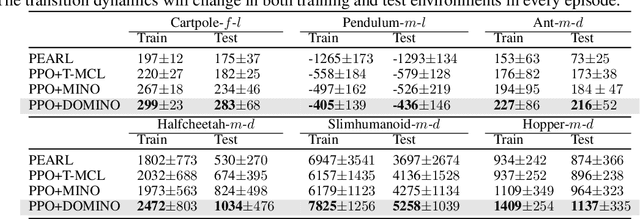
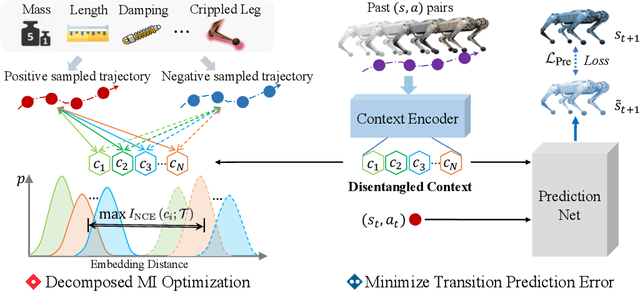
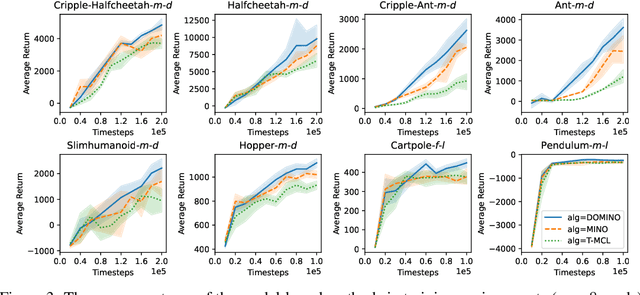
Adapting to the changes in transition dynamics is essential in robotic applications. By learning a conditional policy with a compact context, context-aware meta-reinforcement learning provides a flexible way to adjust behavior according to dynamics changes. However, in real-world applications, the agent may encounter complex dynamics changes. Multiple confounders can influence the transition dynamics, making it challenging to infer accurate context for decision-making. This paper addresses such a challenge by Decomposed Mutual INformation Optimization (DOMINO) for context learning, which explicitly learns a disentangled context to maximize the mutual information between the context and historical trajectories, while minimizing the state transition prediction error. Our theoretical analysis shows that DOMINO can overcome the underestimation of the mutual information caused by multi-confounded challenges via learning disentangled context and reduce the demand for the number of samples collected in various environments. Extensive experiments show that the context learned by DOMINO benefits both model-based and model-free reinforcement learning algorithms for dynamics generalization in terms of sample efficiency and performance in unseen environments.
Enhance Sample Efficiency and Robustness of End-to-end Urban Autonomous Driving via Semantic Masked World Model
Oct 08, 2022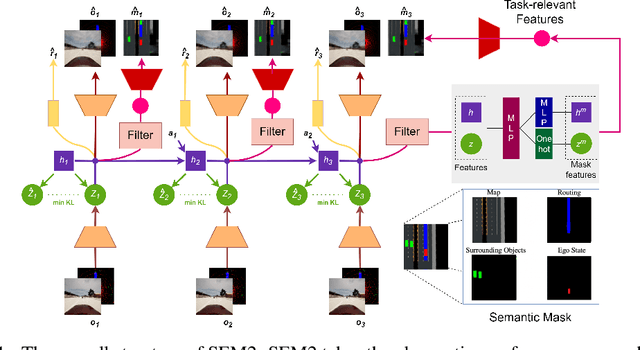

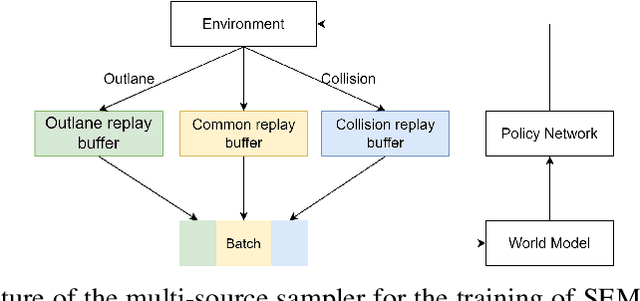
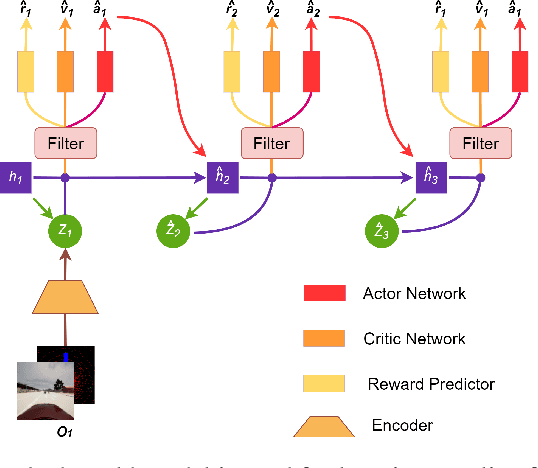
End-to-end autonomous driving provides a feasible way to automatically maximize overall driving system performance by directly mapping the raw pixels from a front-facing camera to control signals. Recent advanced methods construct a latent world model to map the high dimensional observations into compact latent space. However, the latent states embedded by the world model proposed in previous works may contain a large amount of task-irrelevant information, resulting in low sampling efficiency and poor robustness to input perturbations. Meanwhile, the training data distribution is usually unbalanced, and the learned policy is hard to cope with the corner cases during the driving process. To solve the above challenges, we present a semantic masked recurrent world model (SEM2), which introduces a latent filter to extract key task-relevant features and reconstruct a semantic mask via the filtered features, and is trained with a multi-source data sampler, which aggregates common data and multiple corner case data in a single batch, to balance the data distribution. Extensive experiments on CARLA show that our method outperforms the state-of-the-art approaches in terms of sample efficiency and robustness to input permutations.
Zero-Shot Policy Transfer with Disentangled Task Representation of Meta-Reinforcement Learning
Oct 01, 2022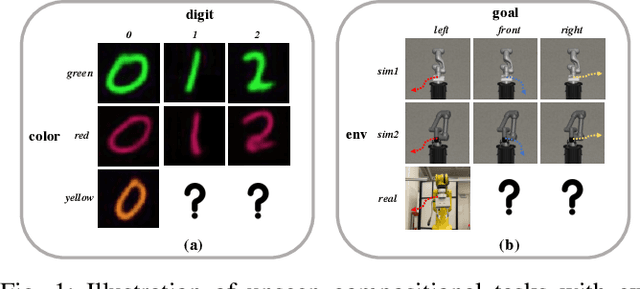
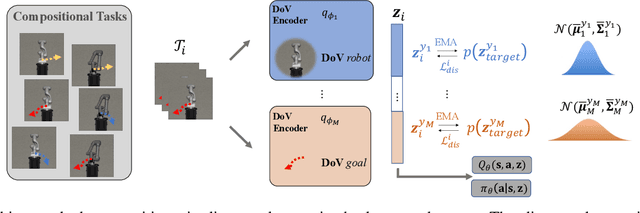
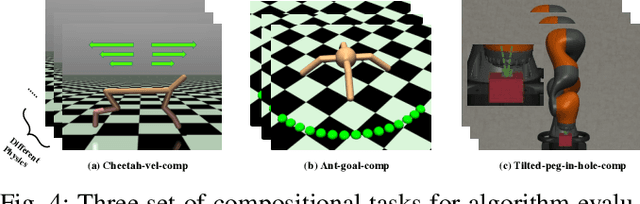
Humans are capable of abstracting various tasks as different combinations of multiple attributes. This perspective of compositionality is vital for human rapid learning and adaption since previous experiences from related tasks can be combined to generalize across novel compositional settings. In this work, we aim to achieve zero-shot policy generalization of Reinforcement Learning (RL) agents by leveraging the task compositionality. Our proposed method is a meta- RL algorithm with disentangled task representation, explicitly encoding different aspects of the tasks. Policy generalization is then performed by inferring unseen compositional task representations via the obtained disentanglement without extra exploration. The evaluation is conducted on three simulated tasks and a challenging real-world robotic insertion task. Experimental results demonstrate that our proposed method achieves policy generalization to unseen compositional tasks in a zero-shot manner.