 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Diverse Perspectives: A Multi-Agent Framework for Enhanced Error Detection in Knowledge Graphs
Jan 27, 2025



Knowledge graphs are widely used in industrial applications, making error detection crucial for ensuring the reliability of downstream applications. Existing error detection methods often fail to effectively leverage fine-grained subgraph information and rely solely on fixed graph structures, while also lacking transparency in their decision-making processes, which results in suboptimal detection performance. In this paper, we propose a novel Multi-Agent framework for Knowledge Graph Error Detection (MAKGED) that utilizes multiple large language models (LLMs) in a collaborative setting. By concatenating fine-grained, bidirectional subgraph embeddings with LLM-based query embeddings during training, our framework integrates these representations to produce four specialized agents. These agents utilize subgraph information from different dimensions to engage in multi-round discussions, thereby improving error detection accuracy and ensuring a transparent decision-making process. Extensive experiments on FB15K and WN18RR demonstrate that MAKGED outperforms state-of-the-art methods, enhancing the accuracy and robustness of KG evaluation. For specific industrial scenarios, our framework can facilitate the training of specialized agents using domain-specific knowledge graphs for error detection, which highlights the potential industrial application value of our framework. Our code and datasets are available at https://github.com/kse-ElEvEn/MAKGED.
Enhance Sample Efficiency and Robustness of End-to-end Urban Autonomous Driving via Semantic Masked World Model
Oct 08, 2022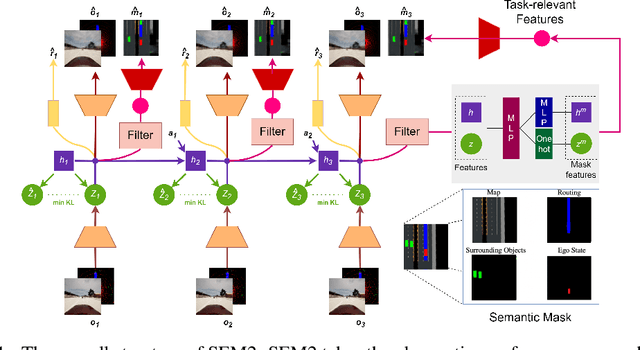

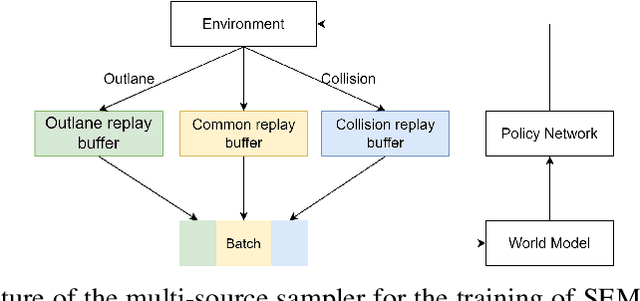
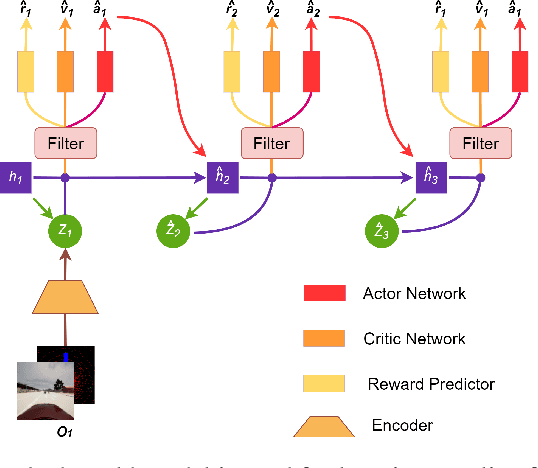
End-to-end autonomous driving provides a feasible way to automatically maximize overall driving system performance by directly mapping the raw pixels from a front-facing camera to control signals. Recent advanced methods construct a latent world model to map the high dimensional observations into compact latent space. However, the latent states embedded by the world model proposed in previous works may contain a large amount of task-irrelevant information, resulting in low sampling efficiency and poor robustness to input perturbations. Meanwhile, the training data distribution is usually unbalanced, and the learned policy is hard to cope with the corner cases during the driving process. To solve the above challenges, we present a semantic masked recurrent world model (SEM2), which introduces a latent filter to extract key task-relevant features and reconstruct a semantic mask via the filtered features, and is trained with a multi-source data sampler, which aggregates common data and multiple corner case data in a single batch, to balance the data distribution. Extensive experiments on CARLA show that our method outperforms the state-of-the-art approaches in terms of sample efficiency and robustness to input permutations.