 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundarySqueeze: Image Segmentation as Boundary Squeezing
May 25, 2021
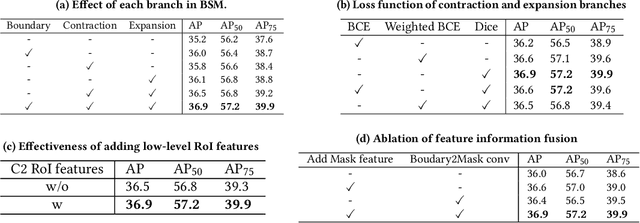

We propose a novel method for fine-grained high-quality image segmentation of both objects and scenes. Inspired by dilation and erosion from morphological image processing techniques, we treat the pixel level segmentation problems as squeezing object boundary. From this perspective, we propose \textbf{Boundary Squeeze} module: a novel and efficient module that squeezes the object boundary from both inner and outer directions which leads to precise mask representation. To generate such squeezed representation, we propose a new bidirectionally flow-based warping process and design specific loss signals to supervise the learning process. Boundary Squeeze Module can be easily applied to both instance and semantic segmentation tasks as a plug-and-play module by building on top of existing models. We show that our simple yet effective design can lead to high qualitative results on several different datasets and we also provide several different metrics on boundary to prove the effectiveness over previous work. Moreover, the proposed module is light-weighted and thus has potential for practical usage. Our method yields large gains on COCO, Cityscapes, for both instance and semantic segmentation and outperforms previous state-of-the-art PointRend in both accuracy and speed under the same setting. Code and model will be available.
Enhanced Boundary Learning for Glass-like Object Segmentation
Mar 29, 2021
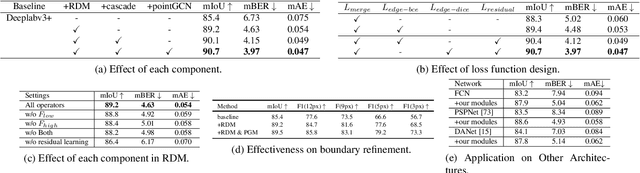
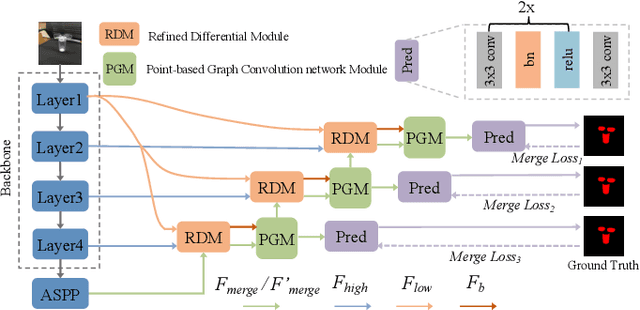
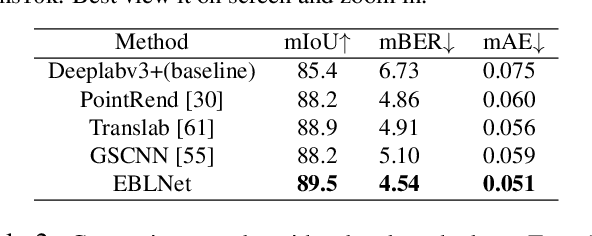
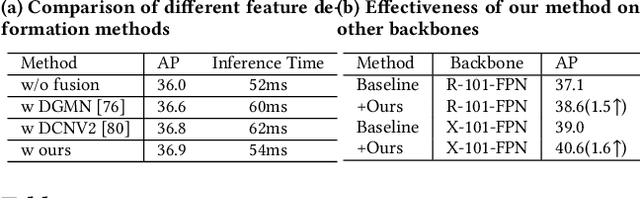
Glass-like objects such as windows, bottles, and mirrors exist widely in the real world. Sensing these objects has many applications, including robot navigation and grasping. However, this task is very challenging due to the arbitrary scenes behind glass-like objects. This paper aims to solve the glass-like object segmentation problem via enhanced boundary learning. In particular, we first propose a novel refined differential module for generating finer boundary cues. Then an edge-aware point-based graph convolution network module is proposed to model the global shape representation along the boundary. Both modules are lightweight and effective, which can be embedded into various segmentation models. Moreover, we use these two modules to design a decoder to get accurate segmentation results, especially on the boundary. Extensive experiments on three recent glass-like object segmentation datasets, including Trans10k, MSD, and GDD, show that our approach establishes new state-of-the-art performances. We also offer the generality and superiority of our approach compared with recent methods on three general segmentation datasets, including Cityscapes, BDD, and COCO Stuff. Code and models will be available at (\url{https://github.com/hehao13/EBLNet})
PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation
Mar 11, 2021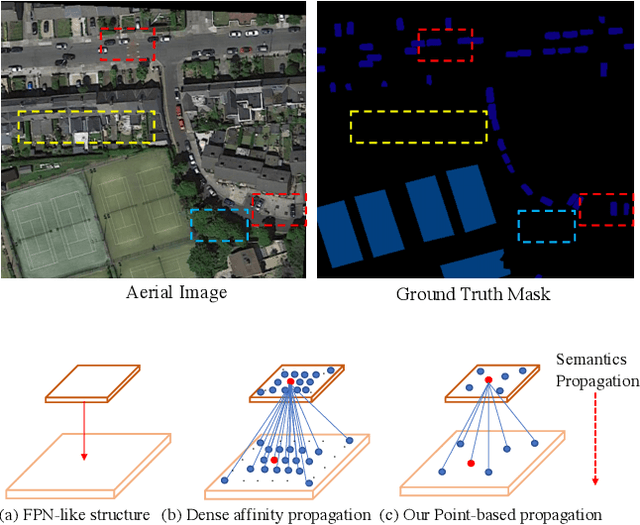
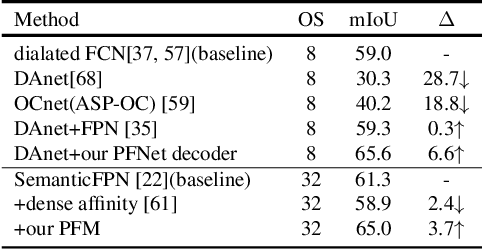
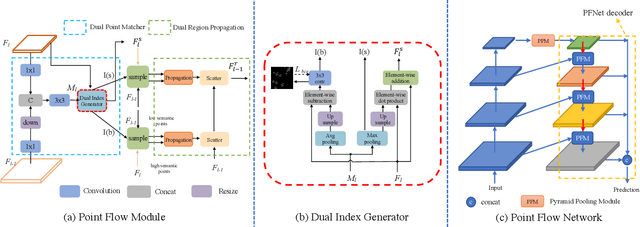
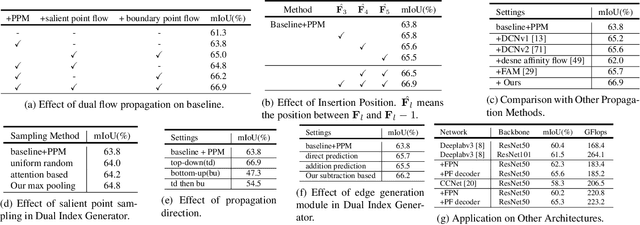
Aerial Image Segmentation is a particular semantic segmentation problem and has several challenging characteristics that general semantic segmentation does not have. There are two critical issues: The one is an extremely foreground-background imbalanced distribution, and the other is multiple small objects along with the complex background. Such problems make the recent dense affinity context modeling perform poorly even compared with baselines due to over-introduced background context. To handle these problems, we propose a point-wise affinity propagation module based on the Feature Pyramid Network (FPN) framework, named PointFlow. Rather than dense affinity learning, a sparse affinity map is generated upon selected points between the adjacent features, which reduces the noise introduced by the background while keeping efficiency. In particular, we design a dual point matcher to select points from the salient area and object boundaries, respectively. Experimental results on three different aerial segmentation datasets suggest that the proposed method is more effective and efficient than state-of-the-art general semantic segmentation methods. Especially, our methods achieve the best speed and accuracy trade-off on three aerial benchmarks. Further experiments on three general semantic segmentation datasets prove the generality of our method. Code will be provided in (https: //github.com/lxtGH/PFSegNets).
PV-RCNN++: Point-Voxel Feature Set Abstraction With Local Vector Representation for 3D Object Detection
Jan 31, 2021
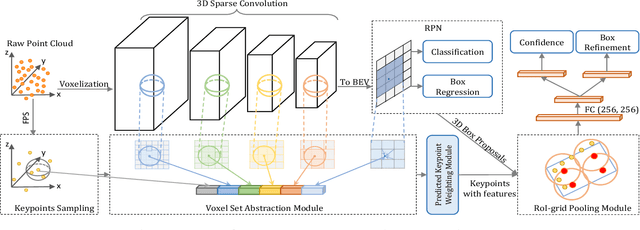
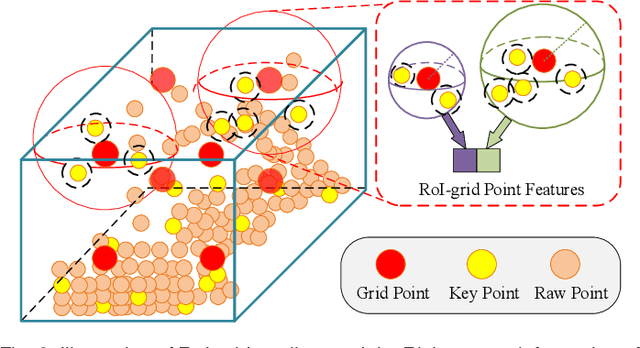

3D object detection is receiving increasing attention from both industry and academia thanks to its wide applications in various fields. In this paper, we propose the Point-Voxel Region based Convolution Neural Networks (PV-RCNNs) for accurate 3D detection from point clouds. First, we propose a novel 3D object detector, PV-RCNN-v1, which employs the voxel-to-keypoint scene encoding and keypoint-to-grid RoI feature abstraction two novel steps. These two steps deeply incorporate both 3D voxel CNN and PointNet-based set abstraction for learning discriminative point-cloud features. Second, we propose a more advanced framework, PV-RCNN-v2, for more efficient and accurate 3D detection. It consists of two major improvements, where the first one is the sectorized proposal-centric strategy for efficiently producing more representative and uniformly distributed keypoints, and the second one is the VectorPool aggregation to replace set abstraction for better aggregating local point-cloud features with much less resource consumption. With these two major modifications, our PV-RCNN-v2 runs more than twice as fast as the v1 version while still achieving better performance on the large-scale Waymo Open Dataset with 150m * 150m detection range. Extensive experiments demonstrate that our proposed PV-RCNNs significantly outperform previous state-of-the-art 3D detection methods on both the Waymo Open Dataset and the highly-competitive KITTI benchmark.
FLAVA: Find, Localize, Adjust and Verify to Annotate LiDAR-Based Point Clouds
Nov 20, 2020
Recent years have witnessed the rapid progress of perception algorithms on top of LiDAR, a widely adopted sensor for autonomous driving systems. These LiDAR-based solutions are typically data hungry, requiring a large amount of data to be labeled for training and evaluation. However, annotating this kind of data is very challenging due to the sparsity and irregularity of point clouds and more complex interaction involved in this procedure. To tackle this problem, we propose FLAVA, a systematic approach to minimizing human interaction in the annotation process. Specifically, we divide the annotation pipeline into four parts: find, localize, adjust and verify. In addition, we carefully design the UI for different stages of the annotation procedure, thus keeping the annotators to focus on the aspects that are most important to each stage. Furthermore, our system also greatly reduces the amount of interaction by introducing a light-weight yet effective mechanism to propagate the annotation results. Experimental results show that our method can remarkably accelerate the procedure and improve the annotation quality.
SelfVoxeLO: Self-supervised LiDAR Odometry with Voxel-based Deep Neural Networks
Oct 19, 2020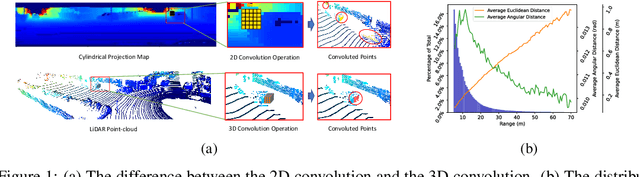
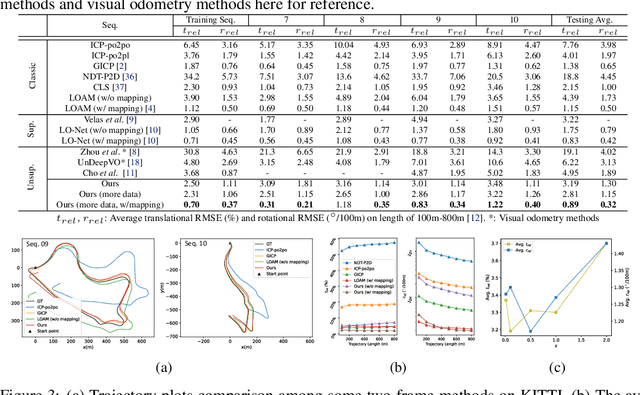
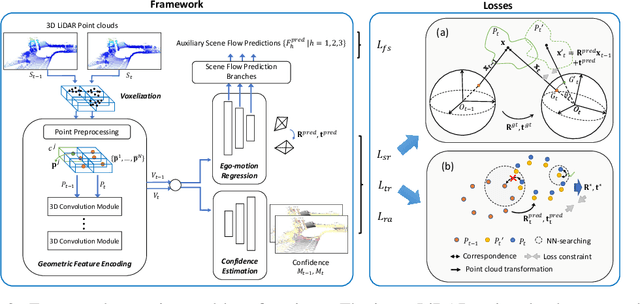
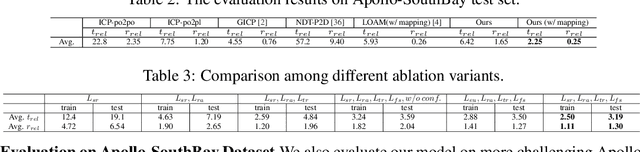
Recent learning-based LiDAR odometry methods have demonstrated their competitiveness. However, most methods still face two substantial challenges: 1) the 2D projection representation of LiDAR data cannot effectively encode 3D structures from the point clouds; 2) the needs for a large amount of labeled data for training limit the application scope of these methods. In this paper, we propose a self-supervised LiDAR odometry method, dubbed SelfVoxeLO, to tackle these two difficulties. Specifically, we propose a 3D convolution network to process the raw LiDAR data directly, which extracts features that better encode the 3D geometric patterns. To suit our network to self-supervised learning, we design several novel loss functions that utilize the inherent properties of LiDAR point clouds. Moreover, an uncertainty-aware mechanism is incorporated in the loss functions to alleviate the interference of moving objects/noises. We evaluate our method's performances on two large-scale datasets, i.e., KITTI and Apollo-SouthBay. Our method outperforms state-of-the-art unsupervised methods by 27%/32% in terms of translational/rotational errors on the KITTI dataset and also performs well on the Apollo-SouthBay dataset. By including more unlabelled training data, our method can further improve performance comparable to the supervised methods.
Understanding the wiring evolution in differentiable neural architecture search
Sep 07, 2020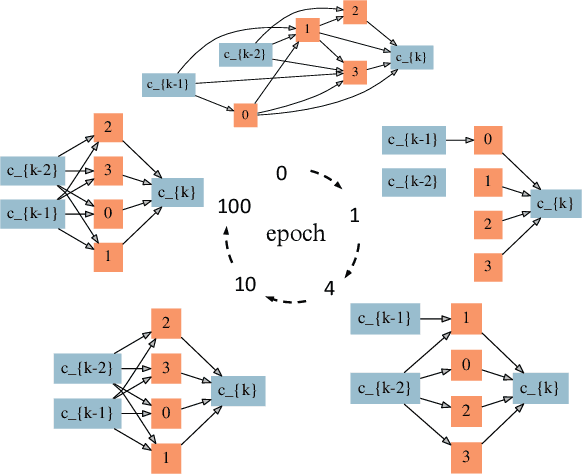
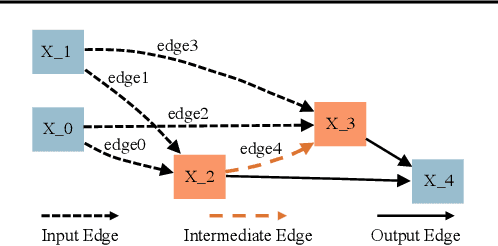
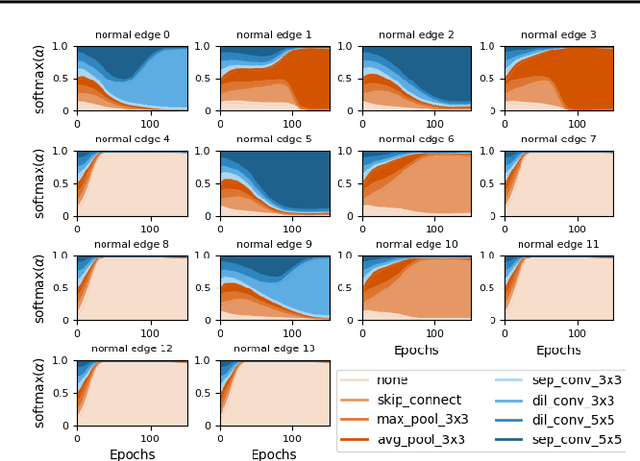
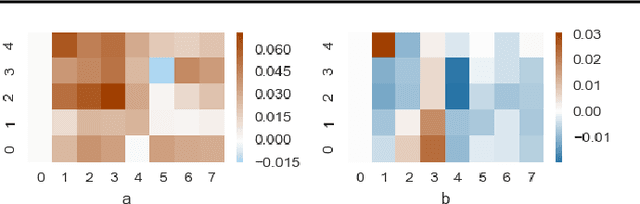
Controversy exists on whether differentiable neural architecture search methods discover wiring topology effectively. To understand how wiring topology evolves, we study the underlying mechanism of several existing differentiable NAS frameworks. Our investigation is motivated by three observed searching patterns of differentiable NAS: 1) they search by growing instead of pruning; 2) wider networks are more preferred than deeper ones; 3) no edges are selected in bi-level optimization. To anatomize these phenomena, we propose a unified view on searching algorithms of existing frameworks, transferring the global optimization to local cost minimization. Based on this reformulation, we conduct empirical and theoretical analyses, revealing implicit inductive biases in the cost's assignment mechanism and evolution dynamics that cause the observed phenomena. These biases indicate strong discrimination towards certain topologies. To this end, we pose questions that future differentiable methods for neural wiring discovery need to confront, hoping to evoke a discussion and rethinking on how much bias has been enforced implicitly in existing NAS methods.
Channel-wise Alignment for Adaptive Object Detection
Sep 07, 2020
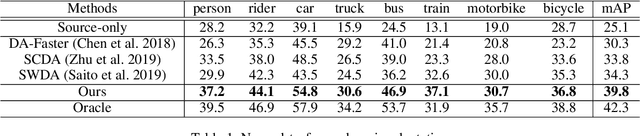
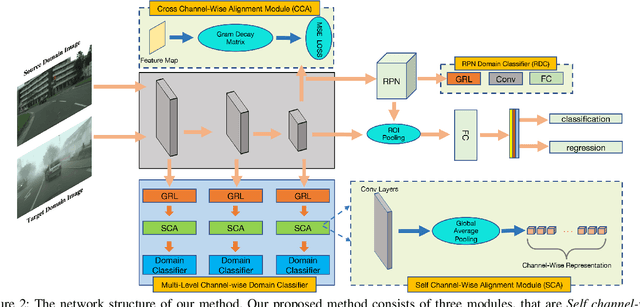
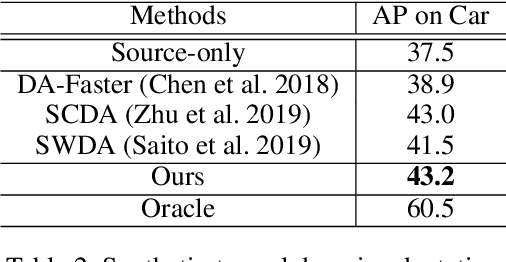
Generic object detection has been immensely promoted by the development of deep convolutional neural networks in the past decade. However, in the domain shift circumstance, the changes in weather, illumination, etc., often cause domain gap, and thus performance drops substantially when detecting objects from one domain to another. Existing methods on this task usually draw attention on the high-level alignment based on the whole image or object of interest, which naturally, cannot fully utilize the fine-grained channel information. In this paper, we realize adaptation from a thoroughly different perspective, i.e., channel-wise alignment. Motivated by the finding that each channel focuses on a specific pattern (e.g., on special semantic regions, such as car), we aim to align the distribution of source and target domain on the channel level, which is finer for integration between discrepant domains. Our method mainly consists of self channel-wise and cross channel-wise alignment. These two parts explore the inner-relation and cross-relation of attention regions implicitly from the view of channels. Further more, we also propose a RPN domain classifier module to obtain a domain-invariant RPN network. Extensive experiments show that the proposed method performs notably better than existing methods with about 5% improvement under various domain-shift settings. Experiments on different task (e.g. instance segmentation) also demonstrate its good scalability.
Improving Semantic Segmentation via Decoupled Body and Edge Supervision
Aug 18, 2020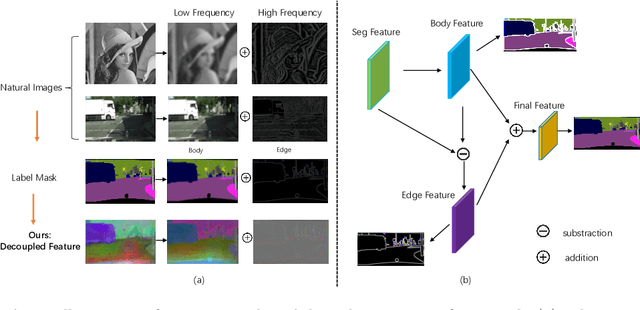
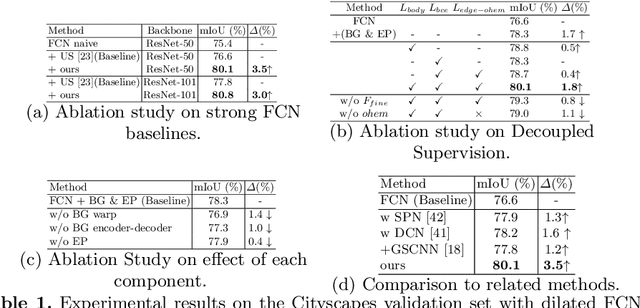
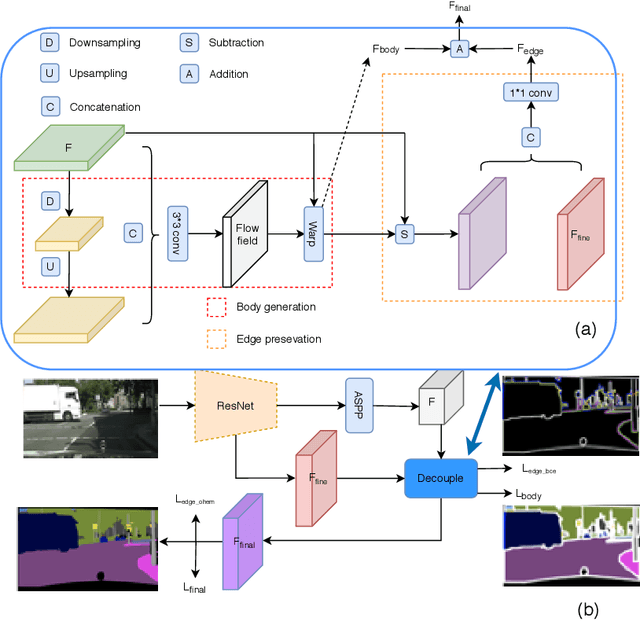

Existing semantic segmentation approaches either aim to improve the object's inner consistency by modeling the global context, or refine objects detail along their boundaries by multi-scale feature fusion. In this paper, a new paradigm for semantic segmentation is proposed. Our insight is that appealing performance of semantic segmentation requires \textit{explicitly} modeling the object \textit{body} and \textit{edge}, which correspond to the high and low frequency of the image. To do so, we first warp the image feature by learning a flow field to make the object part more consistent. The resulting body feature and the residual edge feature are further optimized under decoupled supervision by explicitly sampling different parts (body or edge) pixels. We show that the proposed framework with various baselines or backbone networks leads to better object inner consistency and object boundaries. Extensive experiments on four major road scene semantic segmentation benchmarks including \textit{Cityscapes}, \textit{CamVid}, \textit{KIITI} and \textit{BDD} show that our proposed approach establishes new state of the art while retaining high efficiency in inference. In particular, we achieve 83.7 mIoU \% on Cityscape with only fine-annotated data. Code and models are made available to foster any further research (\url{https://github.com/lxtGH/DecoupleSegNets}).
TSIT: A Simple and Versatile Framework for Image-to-Image Translation
Jul 25, 2020
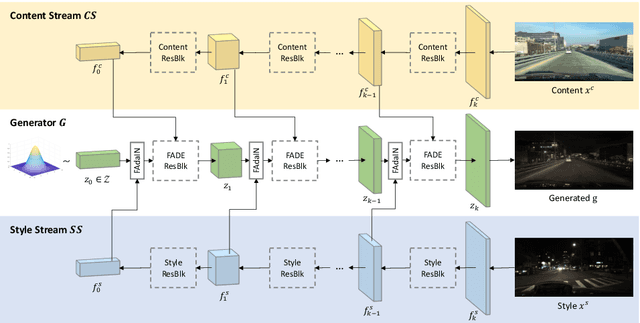
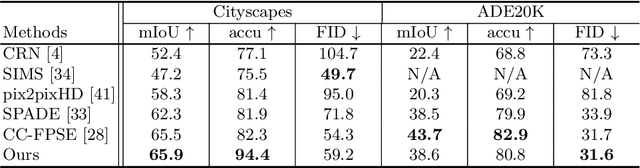
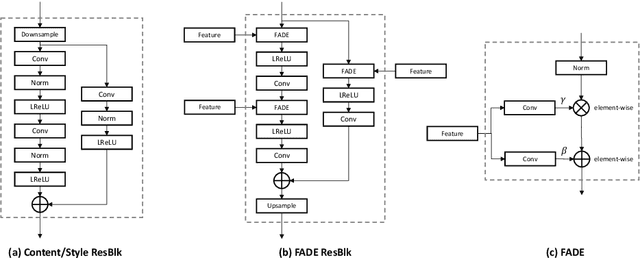
We introduce a simple and versatile framework for image-to-image translation. We unearth the importance of normalization layers, and provide a carefully designed two-stream generative model with newly proposed feature transformations in a coarse-to-fine fashion. This allows multi-scale semantic structure information and style representation to be effectively captured and fused by the network, permitting our method to scale to various tasks in both unsupervised and supervised settings. No additional constraints (e.g., cycle consistency) are needed, contributing to a very clean and simple method. Multi-modal image synthesis with arbitrary style control is made possible. A systematic study compares the proposed method with several state-of-the-art task-specific baselines, verifying its effectiveness in both perceptual quality and quantitative evaluations.