 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Code Sketches
Jun 18, 2021

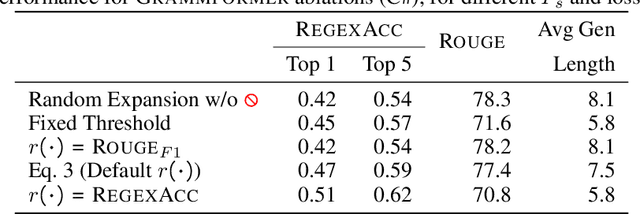
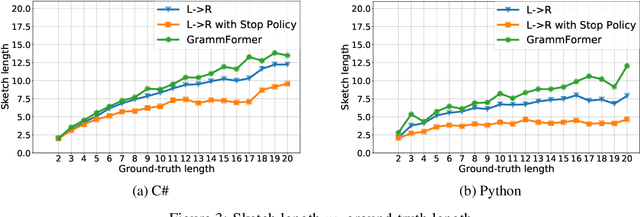
Traditional generative models are limited to predicting sequences of terminal tokens. However, ambiguities in the generation task may lead to incorrect outputs. Towards addressing this, we introduce Grammformers, transformer-based grammar-guided models that learn (without explicit supervision) to generate sketches -- sequences of tokens with holes. Through reinforcement learning, Grammformers learn to introduce holes avoiding the generation of incorrect tokens where there is ambiguity in the target task. We train Grammformers for statement-level source code completion, i.e., the generation of code snippets given an ambiguous user intent, such as a partial code context. We evaluate Grammformers on code completion for C# and Python and show that it generates 10-50% more accurate sketches compared to traditional generative models and 37-50% longer sketches compared to sketch-generating baselines trained with similar techniques.
Fast and Accurate Single-Image Depth Estimation on Mobile Devices, Mobile AI 2021 Challenge: Report
May 17, 2021


Depth estimation is an important computer vision problem with many practical applications to mobile devices. While many solutions have been proposed for this task, they are usually very computationally expensive and thus are not applicable for on-device inference. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based depth estimation solutions that can demonstrate a nearly real-time performance on smartphones and IoT platforms. For this, the participants were provided with a new large-scale dataset containing RGB-depth image pairs obtained with a dedicated stereo ZED camera producing high-resolution depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the popular Raspberry Pi 4 platform with a mobile ARM-based Broadcom chipset. The proposed solutions can generate VGA resolution depth maps at up to 10 FPS on the Raspberry Pi 4 while achieving high fidelity results, and are compatible with any Android or Linux-based mobile devices. A detailed description of all models developed in the challenge is provided in this paper.
AR-LSAT: Investigating Analytical Reasoning of Text
Apr 15, 2021



Analytical reasoning is an essential and challenging task that requires a system to analyze a scenario involving a set of particular circumstances and perform reasoning over it to make conclusions. In this paper, we study the challenge of analytical reasoning of text and introduce a new dataset consisting of questions from the Law School Admission Test from 1991 to 2016. We analyze what knowledge understanding and reasoning abilities are required to do well on this task. Furthermore, to address this reasoning challenge, we design two different baselines: (1) a Transformer-based method which leverages the state-of-the-art pre-trained language models and (2) Analytical Reasoning Machine (ARM), a logical-level reasoning framework extracting symbolic knowledge (e.g, participants, facts, logical functions) to deduce legitimate solutions. In our experiments, we find that the Transformer-based models struggle to solve this task as their performance is close to random guess and ARM achieves better performance by leveraging symbolic knowledge and interpretable reasoning steps. Results show that both methods still lag far behind human performance, which leave further space for future research.
REST: Relational Event-driven Stock Trend Forecasting
Feb 19, 2021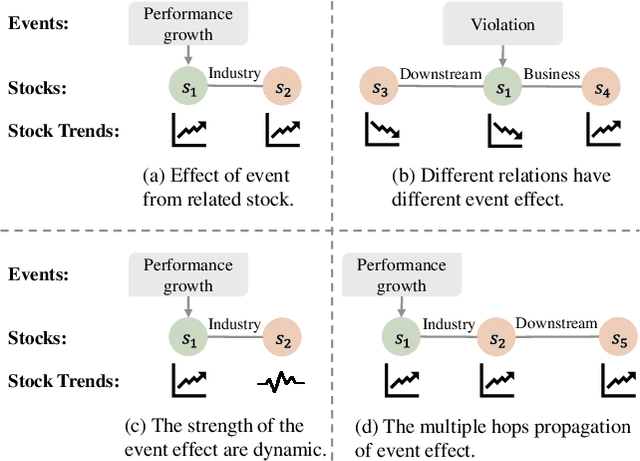

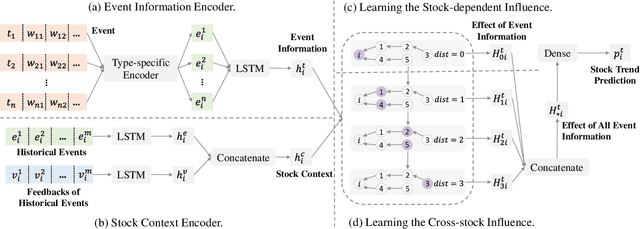
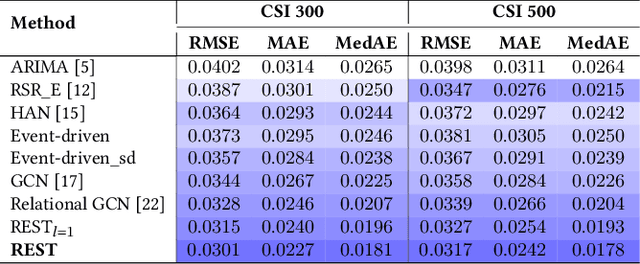
Stock trend forecasting, aiming at predicting the stock future trends, is crucial for investors to seek maximized profits from the stock market. Many event-driven methods utilized the events extracted from news, social media, and discussion board to forecast the stock trend in recent years. However, existing event-driven methods have two main shortcomings: 1) overlooking the influence of event information differentiated by the stock-dependent properties; 2) neglecting the effect of event information from other related stocks. In this paper, we propose a relational event-driven stock trend forecasting (REST) framework, which can address the shortcoming of existing methods. To remedy the first shortcoming, we propose to model the stock context and learn the effect of event information on the stocks under different contexts. To address the second shortcoming, we construct a stock graph and design a new propagation layer to propagate the effect of event information from related stocks. The experimental studies on the real-world data demonstrate the efficiency of our REST framework. The results of investment simulation show that our framework can achieve a higher return of investment than baselines.
Neural Deepfake Detection with Factual Structure of Text
Oct 15, 2020
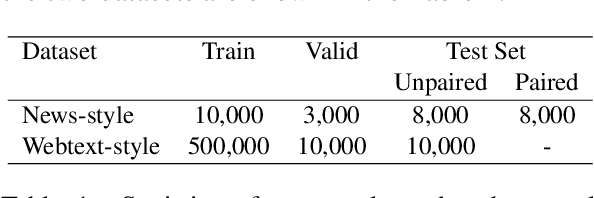
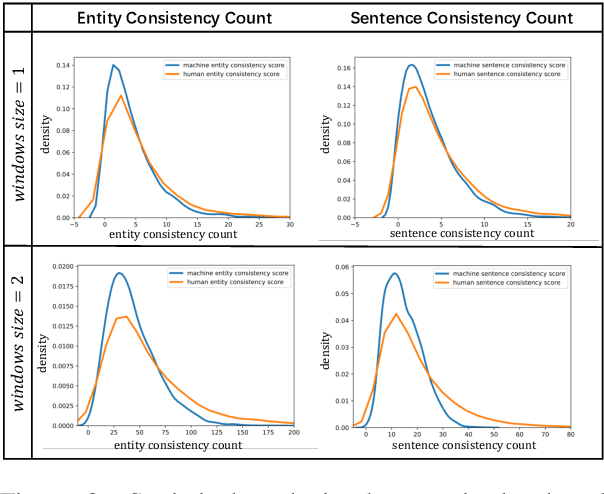
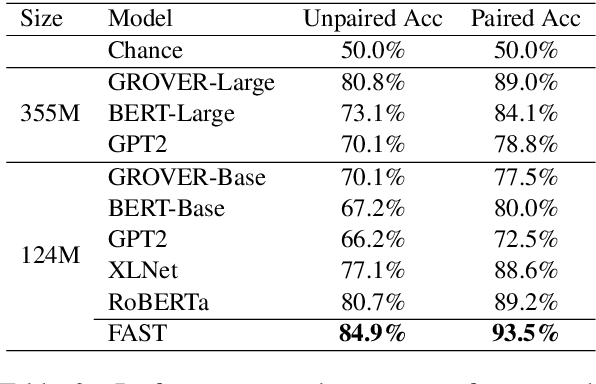
Deepfake detection, the task of automatically discriminating machine-generated text, is increasingly critical with recent advances in natural language generative models. Existing approaches to deepfake detection typically represent documents with coarse-grained representations. However, they struggle to capture factual structures of documents, which is a discriminative factor between machine-generated and human-written text according to our statistical analysis. To address this, we propose a graph-based model that utilizes the factual structure of a document for deepfake detection of text. Our approach represents the factual structure of a given document as an entity graph, which is further utilized to learn sentence representations with a graph neural network. Sentence representations are then composed to a document representation for making predictions, where consistent relations between neighboring sentences are sequentially modeled. Results of experiments on two public deepfake datasets show that our approach significantly improves strong base models built with RoBERTa. Model analysis further indicates that our model can distinguish the difference in the factual structure between machine-generated text and human-written text.
GraphCodeBERT: Pre-training Code Representations with Data Flow
Sep 29, 2020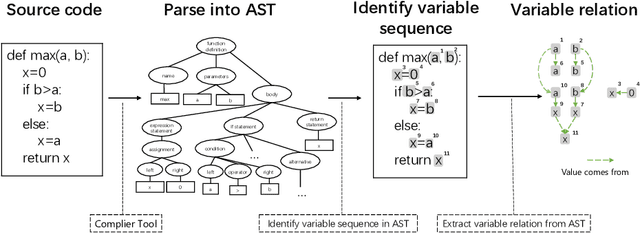
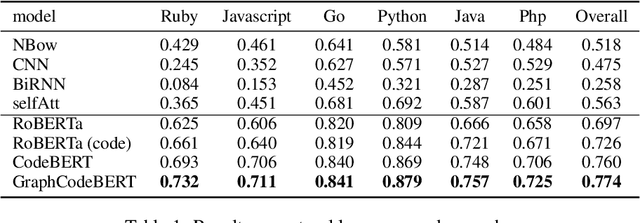
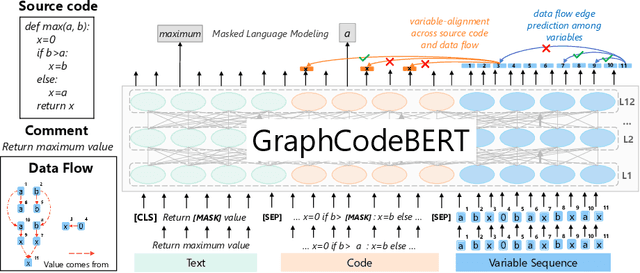
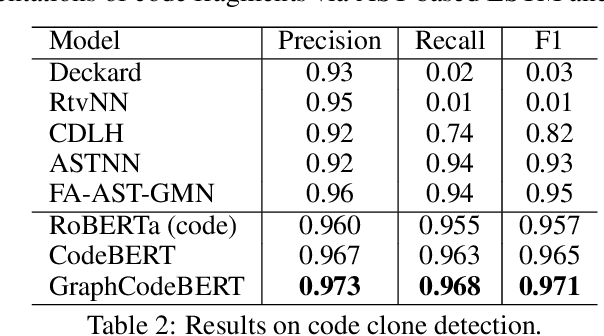
Pre-trained models for programming language have achieved dramatic empirical improvements on a variety of code-related tasks such as code search, code completion, code summarization, etc. However, existing pre-trained models regard a code snippet as a sequence of tokens, while ignoring the inherent structure of code, which provides crucial code semantics and would enhance the code understanding process. We present GraphCodeBERT, a pre-trained model for programming language that considers the inherent structure of code. Instead of taking syntactic-level structure of code like abstract syntax tree (AST), we use data flow in the pre-training stage, which is a semantic-level structure of code that encodes the relation of "where-the-value-comes-from" between variables. Such a semantic-level structure is neat and does not bring an unnecessarily deep hierarchy of AST, the property of which makes the model more efficient. We develop GraphCodeBERT based on Transformer. In addition to using the task of masked language modeling, we introduce two structure-aware pre-training tasks. One is to predict code structure edges, and the other is to align representations between source code and code structure. We implement the model in an efficient way with a graph-guided masked attention function to incorporate the code structure. We evaluate our model on four tasks, including code search, clone detection, code translation, and code refinement. Results show that code structure and newly introduced pre-training tasks can improve GraphCodeBERT and achieves state-of-the-art performance on the four downstream tasks. We further show that the model prefers structure-level attentions over token-level attentions in the task of code search.
Membership Inference with Privately Augmented Data Endorses the Benign while Suppresses the Adversary
Jul 21, 2020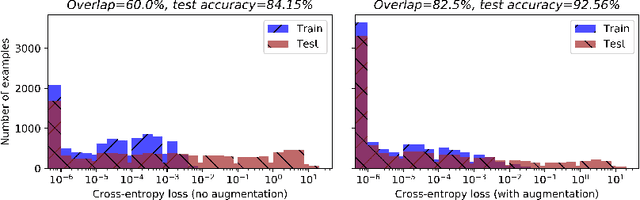
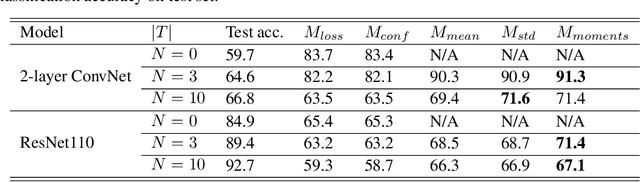
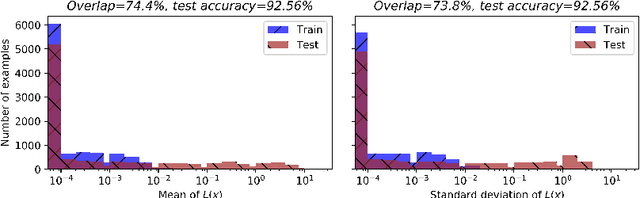

Membership inference (MI) in machine learning decides whether a given example is in target model's training set. It can be used in two ways: adversaries use it to steal private membership information while legitimate users can use it to verify whether their data has been forgotten by a trained model. Therefore, MI is a double-edged sword to privacy preserving machine learning. In this paper, we propose using private augmented data to sharpen its good side while passivate its bad side. To sharpen the good side, we exploit the data augmentation used in training to boost the accuracy of membership inference. Specifically, we compose a set of augmented instances for each sample and then the membership inference is formulated as a set classification problem, i.e., classifying a set of augmented data points instead of one point. We design permutation invariant features based on the losses of augmented instances. Our approach significantly improves the MI accuracy over existing algorithms. To passivate the bad side, we apply different data augmentation methods to each legitimate user and keep the augmented data as secret. We show that the malicious adversaries cannot benefit from our algorithms if being ignorant of the augmented data used in training. Extensive experiments demonstrate the superior efficacy of our algorithms. Our source code is available at anonymous GitHub page \url{https://github.com/AnonymousDLMA/MI_with_DA}.
Evidence-Aware Inferential Text Generation with Vector Quantised Variational AutoEncoder
Jun 15, 2020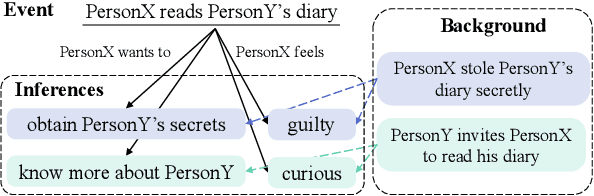
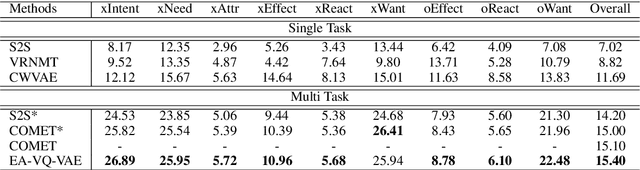
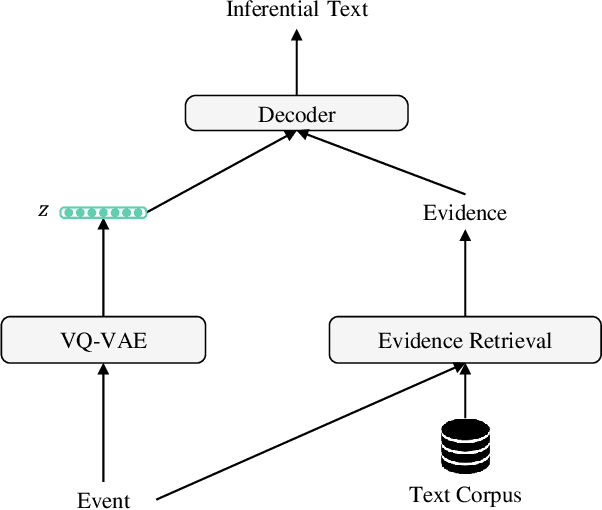
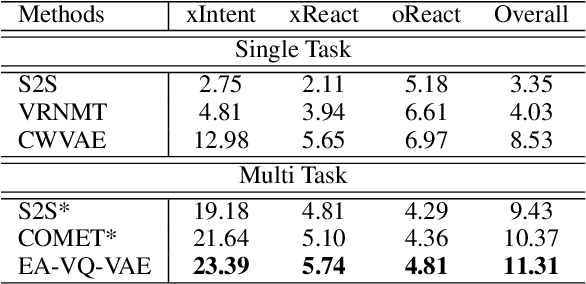
Generating inferential texts about an event in different perspectives requires reasoning over different contexts that the event occurs. Existing works usually ignore the context that is not explicitly provided, resulting in a context-independent semantic representation that struggles to support the generation. To address this, we propose an approach that automatically finds evidence for an event from a large text corpus, and leverages the evidence to guide the generation of inferential texts. Our approach works in an encoder-decoder manner and is equipped with a Vector Quantised-Variational Autoencoder, where the encoder outputs representations from a distribution over discrete variables. Such discrete representations enable automatically selecting relevant evidence, which not only facilitates evidence-aware generation, but also provides a natural way to uncover rationales behind the generation. Our approach provides state-of-the-art performance on both Event2Mind and ATOMIC datasets. More importantly, we find that with discrete representations, our model selectively uses evidence to generate different inferential texts.
SEEK: Segmented Embedding of Knowledge Graphs
May 02, 2020
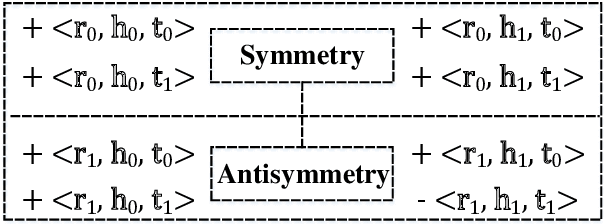
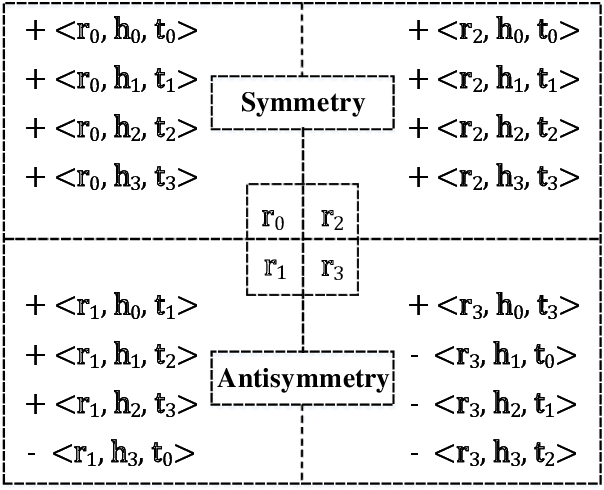
In recent years, knowledge graph embedding becomes a pretty hot research topic of artificial intelligence and plays increasingly vital roles in various downstream applications, such as recommendation and question answering. However, existing methods for knowledge graph embedding can not make a proper trade-off between the model complexity and the model expressiveness, which makes them still far from satisfactory. To mitigate this problem, we propose a lightweight modeling framework that can achieve highly competitive relational expressiveness without increasing the model complexity. Our framework focuses on the design of scoring functions and highlights two critical characteristics: 1) facilitating sufficient feature interactions; 2) preserving both symmetry and antisymmetry properties of relations. It is noteworthy that owing to the general and elegant design of scoring functions, our framework can incorporate many famous existing methods as special cases. Moreover, extensive experiments on public benchmarks demonstrate the efficiency and effectiveness of our framework. Source codes and data can be found at \url{https://github.com/Wentao-Xu/SEEK}.
LogicalFactChecker: Leveraging Logical Operations for Fact Checking with Graph Module Network
Apr 28, 2020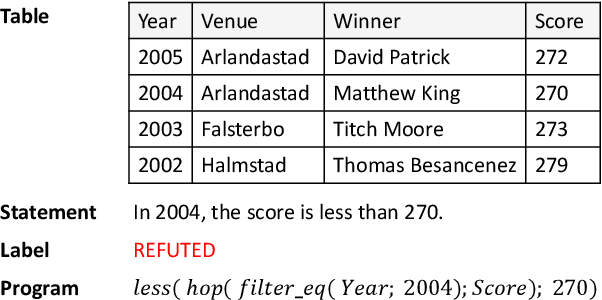
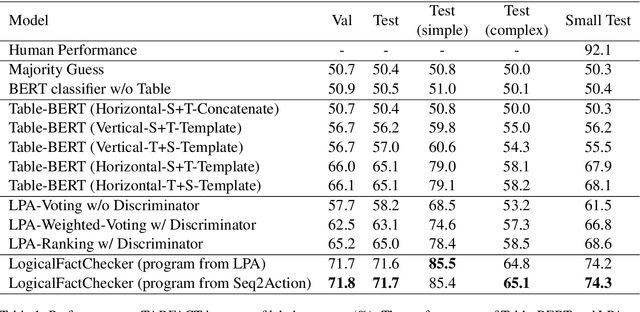
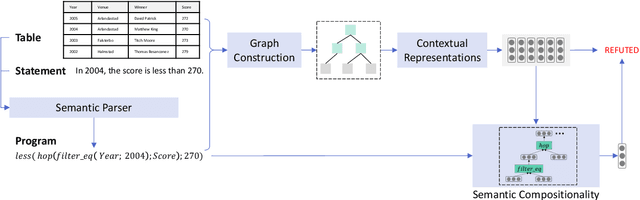
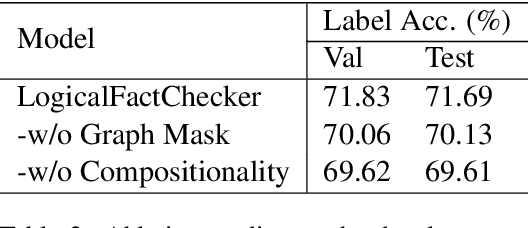
Verifying the correctness of a textual statement requires not only semantic reasoning about the meaning of words, but also symbolic reasoning about logical operations like count, superlative, aggregation, etc. In this work, we propose LogicalFactChecker, a neural network approach capable of leveraging logical operations for fact checking. It achieves the state-of-the-art performance on TABFACT, a large-scale, benchmark dataset built for verifying a textual statement with semi-structured tables. This is achieved by a graph module network built upon the Transformer-based architecture. With a textual statement and a table as the input, LogicalFactChecker automatically derives a program (a.k.a. logical form) of the statement in a semantic parsing manner. A heterogeneous graph is then constructed to capture not only the structures of the table and the program, but also the connections between inputs with different modalities. Such a graph reveals the related contexts of each word in the statement, the table and the program. The graph is used to obtain graph-enhanced contextual representations of words in Transformer-based architecture. After that, a program-driven module network is further introduced to exploit the hierarchical structure of the program, where semantic compositionality is dynamically modeled along the program structure with a set of function-specific modules. Ablation experiments suggest that both the heterogeneous graph and the module network are important to obtain strong results.