 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety at One Shot: Patching Fine-Tuned LLMs with A Single Instance
Jan 06, 2026Fine-tuning safety-aligned large language models (LLMs) can substantially compromise their safety. Previous approaches require many safety samples or calibration sets, which not only incur significant computational overhead during realignment but also lead to noticeable degradation in model utility. Contrary to this belief, we show that safety alignment can be fully recovered with only a single safety example, without sacrificing utility and at minimal cost. Remarkably, this recovery is effective regardless of the number of harmful examples used in fine-tuning or the size of the underlying model, and convergence is achieved within just a few epochs. Furthermore, we uncover the low-rank structure of the safety gradient, which explains why such efficient correction is possible. We validate our findings across five safety-aligned LLMs and multiple datasets, demonstrating the generality of our approach.
OmniAgent: Audio-Guided Active Perception Agent for Omnimodal Audio-Video Understanding
Dec 29, 2025Omnimodal large language models have made significant strides in unifying audio and visual modalities; however, they often lack the fine-grained cross-modal understanding and have difficulty with multimodal alignment. To address these limitations, we introduce OmniAgent, a fully audio-guided active perception agent that dynamically orchestrates specialized tools to achieve more fine-grained audio-visual reasoning. Unlike previous works that rely on rigid, static workflows and dense frame-captioning, this paper demonstrates a paradigm shift from passive response generation to active multimodal inquiry. OmniAgent employs dynamic planning to autonomously orchestrate tool invocation on demand, strategically concentrating perceptual attention on task-relevant cues. Central to our approach is a novel coarse-to-fine audio-guided perception paradigm, which leverages audio cues to localize temporal events and guide subsequent reasoning. Extensive empirical evaluations on three audio-video understanding benchmarks demonstrate that OmniAgent achieves state-of-the-art performance, surpassing leading open-source and proprietary models by substantial margins of 10% - 20% accuracy.
EnvSSLAM-FFN: Lightweight Layer-Fused System for ESDD 2026 Challenge
Dec 23, 2025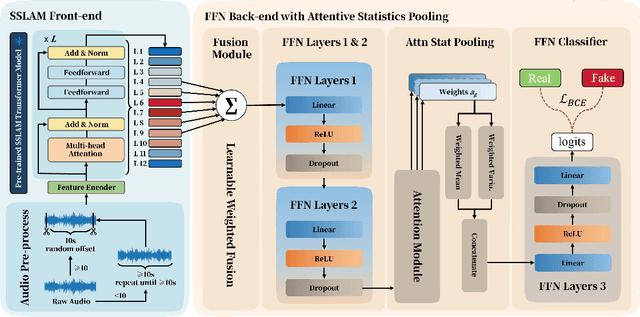
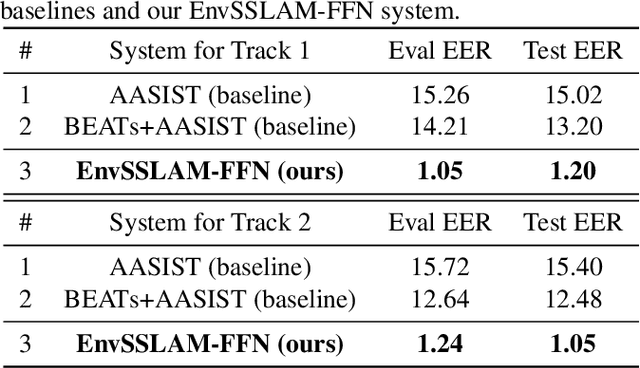
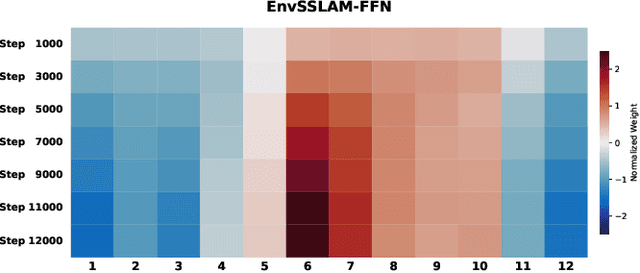
Recent advances in generative audio models have enabled high-fidelity environmental sound synthesis, raising serious concerns for audio security. The ESDD 2026 Challenge therefore addresses environmental sound deepfake detection under unseen generators (Track 1) and black-box low-resource detection (Track 2) conditions. We propose EnvSSLAM-FFN, which integrates a frozen SSLAM self-supervised encoder with a lightweight FFN back-end. To effectively capture spoofing artifacts under severe data imbalance, we fuse intermediate SSLAM representations from layers 4-9 and adopt a class-weighted training objective. Experimental results show that the proposed system consistently outperforms the official baselines on both tracks, achieving Test Equal Error Rates (EERs) of 1.20% and 1.05%, respectively.
StreamingAssistant: Efficient Visual Token Pruning for Accelerating Online Video Understanding
Dec 14, 2025Online video understanding is essential for applications like public surveillance and AI glasses. However, applying Multimodal Large Language Models (MLLMs) to this domain is challenging due to the large number of video frames, resulting in high GPU memory usage and computational latency. To address these challenges, we propose token pruning as a means to reduce context length while retaining critical information. Specifically, we introduce a novel redundancy metric, Maximum Similarity to Spatially Adjacent Video Tokens (MSSAVT), which accounts for both token similarity and spatial position. To mitigate the bidirectional dependency between pruning and redundancy, we further design a masked pruning strategy that ensures only mutually unadjacent tokens are pruned. We also integrate an existing temporal redundancy-based pruning method to eliminate temporal redundancy of the video modality. Experimental results on multiple online and offline video understanding benchmarks demonstrate that our method significantly improves the accuracy (i.e., by 4\% at most) while incurring a negligible pruning latency (i.e., less than 1ms). Our full implementation will be made publicly available.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
GeoPurify: A Data-Efficient Geometric Distillation Framework for Open-Vocabulary 3D Segmentation
Oct 02, 2025



Recent attempts to transfer features from 2D Vision-Language Models (VLMs) to 3D semantic segmentation expose a persistent trade-off. Directly projecting 2D features into 3D yields noisy and fragmented predictions, whereas enforcing geometric coherence necessitates costly training pipelines and large-scale annotated 3D data. We argue that this limitation stems from the dominant segmentation-and-matching paradigm, which fails to reconcile 2D semantics with 3D geometric structure. The geometric cues are not eliminated during the 2D-to-3D transfer but remain latent within the noisy and view-aggregated features. To exploit this property, we propose GeoPurify that applies a small Student Affinity Network to purify 2D VLM-generated 3D point features using geometric priors distilled from a 3D self-supervised teacher model. During inference, we devise a Geometry-Guided Pooling module to further denoise the point cloud and ensure the semantic and structural consistency. Benefiting from latent geometric information and the learned affinity network, GeoPurify effectively mitigates the trade-off and achieves superior data efficiency. Extensive experiments on major 3D benchmarks demonstrate that GeoPurify achieves or surpasses state-of-the-art performance while utilizing only about 1.5% of the training data. Our codes and checkpoints are available at [https://github.com/tj12323/GeoPurify](https://github.com/tj12323/GeoPurify).
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Auto-Connect: Connectivity-Preserving RigFormer with Direct Preference Optimization
Jun 13, 2025



We introduce Auto-Connect, a novel approach for automatic rigging that explicitly preserves skeletal connectivity through a connectivity-preserving tokenization scheme. Unlike previous methods that predict bone positions represented as two joints or first predict points before determining connectivity, our method employs special tokens to define endpoints for each joint's children and for each hierarchical layer, effectively automating connectivity relationships. This approach significantly enhances topological accuracy by integrating connectivity information directly into the prediction framework. To further guarantee high-quality topology, we implement a topology-aware reward function that quantifies topological correctness, which is then utilized in a post-training phase through reward-guided Direct Preference Optimization. Additionally, we incorporate implicit geodesic features for latent top-k bone selection, which substantially improves skinning quality. By leveraging geodesic distance information within the model's latent space, our approach intelligently determines the most influential bones for each vertex, effectively mitigating common skinning artifacts. This combination of connectivity-preserving tokenization, reward-guided fine-tuning, and geodesic-aware bone selection enables our model to consistently generate more anatomically plausible skeletal structures with superior deformation properties.
Occlusion-Aware 3D Hand-Object Pose Estimation with Masked AutoEncoders
Jun 12, 2025Hand-object pose estimation from monocular RGB images remains a significant challenge mainly due to the severe occlusions inherent in hand-object interactions. Existing methods do not sufficiently explore global structural perception and reasoning, which limits their effectiveness in handling occluded hand-object interactions. To address this challenge, we propose an occlusion-aware hand-object pose estimation method based on masked autoencoders, termed as HOMAE. Specifically, we propose a target-focused masking strategy that imposes structured occlusion on regions of hand-object interaction, encouraging the model to learn context-aware features and reason about the occluded structures. We further integrate multi-scale features extracted from the decoder to predict a signed distance field (SDF), capturing both global context and fine-grained geometry. To enhance geometric perception, we combine the implicit SDF with an explicit point cloud derived from the SDF, leveraging the complementary strengths of both representations. This fusion enables more robust handling of occluded regions by combining the global context from the SDF with the precise local geometry provided by the point cloud. Extensive experiments on challenging DexYCB and HO3Dv2 benchmarks demonstrate that HOMAE achieves state-of-the-art performance in hand-object pose estimation. We will release our code and model.