 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Yet Challenging to Detect: Robust In-the-Wild TTS through EMA and Dual-Scoring Prompt Selection -- Submission for WildSpoof 2026 TTS Track
May 22, 2026In this technical report, we describe our submission for the WildSpoof Challenge TTS Track: Text-to-Speech with In-the-Wild Data. We introduce F5-TTS-DPS, a model built upon the F5-TTS architecture. Our approach integrates Exponential Moving Average (EMA) into supervised fine-tuning to stabilize training and improve generalization. To enhance synthesis fidelity, we leverage large language models (LLMs) and large audio language models (LALMs) for dual-scoring prompt selection, filtering reference audio and text prompts to ensure quality while addressing alignment issues in noisy datasets. Experimental evaluation demonstrates that F5-TTS-DPS achieves strong performance with UTMOS of 3.20 and speaker similarity of 0.51 on the development set. More importantly, our model achieves the best a-DCF scores of 0.1582, 0.5233, and 0.2562 across three advanced SASV systems among all submissions, indicating our synthesized speech is the most difficult to detect and exhibits the highest degree of naturalness and authenticity. Combined with competitive WER performance, these results validate the effectiveness of our approach in generating natural-sounding speech with strong spoofing capabilities.
EnvSSLAM-FFN: Lightweight Layer-Fused System for ESDD 2026 Challenge
Dec 23, 2025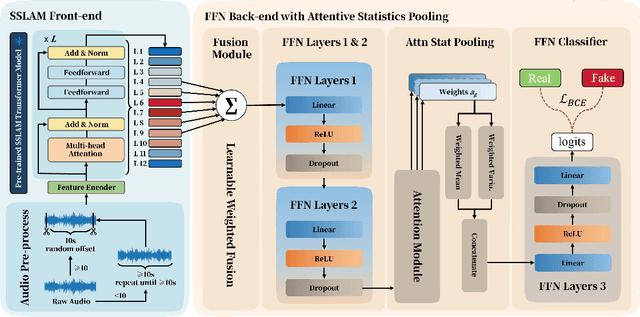
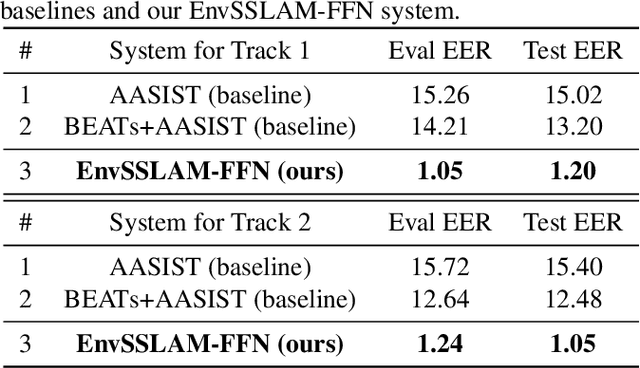
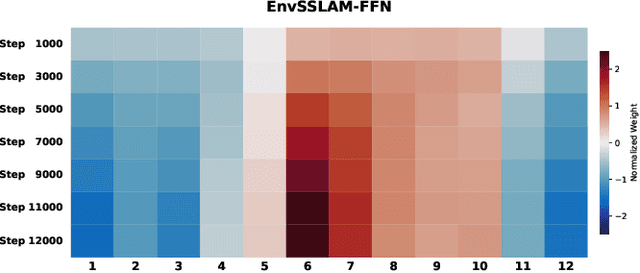
Recent advances in generative audio models have enabled high-fidelity environmental sound synthesis, raising serious concerns for audio security. The ESDD 2026 Challenge therefore addresses environmental sound deepfake detection under unseen generators (Track 1) and black-box low-resource detection (Track 2) conditions. We propose EnvSSLAM-FFN, which integrates a frozen SSLAM self-supervised encoder with a lightweight FFN back-end. To effectively capture spoofing artifacts under severe data imbalance, we fuse intermediate SSLAM representations from layers 4-9 and adopt a class-weighted training objective. Experimental results show that the proposed system consistently outperforms the official baselines on both tracks, achieving Test Equal Error Rates (EERs) of 1.20% and 1.05%, respectively.