 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFVP: Fourier Visual Prompting for Source-Free Unsupervised Domain Adaptation of Medical Image Segmentation
Apr 26, 2023Medical image segmentation methods normally perform poorly when there is a domain shift between training and testing data. Unsupervised Domain Adaptation (UDA) addresses the domain shift problem by training the model using both labeled data from the source domain and unlabeled data from the target domain. Source-Free UDA (SFUDA) was recently proposed for UDA without requiring the source data during the adaptation, due to data privacy or data transmission issues, which normally adapts the pre-trained deep model in the testing stage. However, in real clinical scenarios of medical image segmentation, the trained model is normally frozen in the testing stage. In this paper, we propose Fourier Visual Prompting (FVP) for SFUDA of medical image segmentation. Inspired by prompting learning in natural language processing, FVP steers the frozen pre-trained model to perform well in the target domain by adding a visual prompt to the input target data. In FVP, the visual prompt is parameterized using only a small amount of low-frequency learnable parameters in the input frequency space, and is learned by minimizing the segmentation loss between the predicted segmentation of the prompted target image and reliable pseudo segmentation label of the target image under the frozen model. To our knowledge, FVP is the first work to apply visual prompts to SFUDA for medical image segmentation. The proposed FVP is validated using three public datasets, and experiments demonstrate that FVP yields better segmentation results, compared with various existing methods.
HPN: Personalized Federated Hyperparameter Optimization
Apr 11, 2023



Numerous research studies in the field of federated learning (FL) have attempted to use personalization to address the heterogeneity among clients, one of FL's most crucial and challenging problems. However, existing works predominantly focus on tailoring models. Yet, due to the heterogeneity of clients, they may each require different choices of hyperparameters, which have not been studied so far. We pinpoint two challenges of personalized federated hyperparameter optimization (pFedHPO): handling the exponentially increased search space and characterizing each client without compromising its data privacy. To overcome them, we propose learning a \textsc{H}yper\textsc{P}arameter \textsc{N}etwork (HPN) fed with client encoding to decide personalized hyperparameters. The client encoding is calculated with a random projection-based procedure to protect each client's privacy. Besides, we design a novel mechanism to debias the low-fidelity function evaluation samples for learning HPN. We conduct extensive experiments on FL tasks from various domains, demonstrating the superiority of HPN.
$\rm A^2Q$: Aggregation-Aware Quantization for Graph Neural Networks
Feb 01, 2023



As graph data size increases, the vast latency and memory consumption during inference pose a significant challenge to the real-world deployment of Graph Neural Networks (GNNs). While quantization is a powerful approach to reducing GNNs complexity, most previous works on GNNs quantization fail to exploit the unique characteristics of GNNs, suffering from severe accuracy degradation. Through an in-depth analysis of the topology of GNNs, we observe that the topology of the graph leads to significant differences between nodes, and most of the nodes in a graph appear to have a small aggregation value. Motivated by this, in this paper, we propose the Aggregation-Aware mixed-precision Quantization ($\rm A^2Q$) for GNNs, where an appropriate bitwidth is automatically learned and assigned to each node in the graph. To mitigate the vanishing gradient problem caused by sparse connections between nodes, we propose a Local Gradient method to serve the quantization error of the node features as the supervision during training. We also develop a Nearest Neighbor Strategy to deal with the generalization on unseen graphs. Extensive experiments on eight public node-level and graph-level datasets demonstrate the generality and robustness of our proposed method. Compared to the FP32 models, our method can achieve up to a 18.6x (i.e., 1.70bit) compression ratio with negligible accuracy degradation. Morever, compared to the state-of-the-art quantization method, our method can achieve up to 11.4\% and 9.5\% accuracy improvements on the node-level and graph-level tasks, respectively, and up to 2x speedup on a dedicated hardware accelerator.
DATE: Dual Assignment for End-to-End Fully Convolutional Object Detection
Nov 25, 2022



Fully convolutional detectors discard the one-to-many assignment and adopt a one-to-one assigning strategy to achieve end-to-end detection but suffer from the slow convergence issue. In this paper, we revisit these two assignment methods and find that bringing one-to-many assignment back to end-to-end fully convolutional detectors helps with model convergence. Based on this observation, we propose {\em \textbf{D}ual \textbf{A}ssignment} for end-to-end fully convolutional de\textbf{TE}ction (DATE). Our method constructs two branches with one-to-many and one-to-one assignment during training and speeds up the convergence of the one-to-one assignment branch by providing more supervision signals. DATE only uses the branch with the one-to-one matching strategy for model inference, which doesn't bring inference overhead. Experimental results show that Dual Assignment gives nontrivial improvements and speeds up model convergence upon OneNet and DeFCN. Code: https://github.com/YiqunChen1999/date.
GLIF: A Unified Gated Leaky Integrate-and-Fire Neuron for Spiking Neural Networks
Nov 03, 2022



Spiking Neural Networks (SNNs) have been studied over decades to incorporate their biological plausibility and leverage their promising energy efficiency. Throughout existing SNNs, the leaky integrate-and-fire (LIF) model is commonly adopted to formulate the spiking neuron and evolves into numerous variants with different biological features. However, most LIF-based neurons support only single biological feature in different neuronal behaviors, limiting their expressiveness and neuronal dynamic diversity. In this paper, we propose GLIF, a unified spiking neuron, to fuse different bio-features in different neuronal behaviors, enlarging the representation space of spiking neurons. In GLIF, gating factors, which are exploited to determine the proportion of the fused bio-features, are learnable during training. Combining all learnable membrane-related parameters, our method can make spiking neurons different and constantly changing, thus increasing the heterogeneity and adaptivity of spiking neurons. Extensive experiments on a variety of datasets demonstrate that our method obtains superior performance compared with other SNNs by simply changing their neuronal formulations to GLIF. In particular, we train a spiking ResNet-19 with GLIF and achieve $77.35\%$ top-1 accuracy with six time steps on CIFAR-100, which has advanced the state-of-the-art. Codes are available at \url{https://github.com/Ikarosy/Gated-LIF}.
Reversed Image Signal Processing and RAW Reconstruction. AIM 2022 Challenge Report
Oct 20, 2022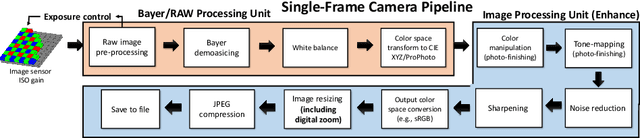
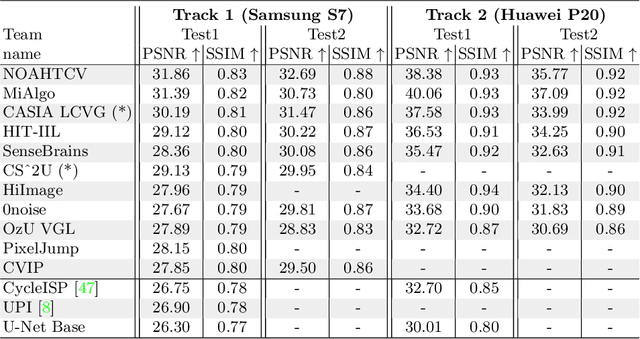
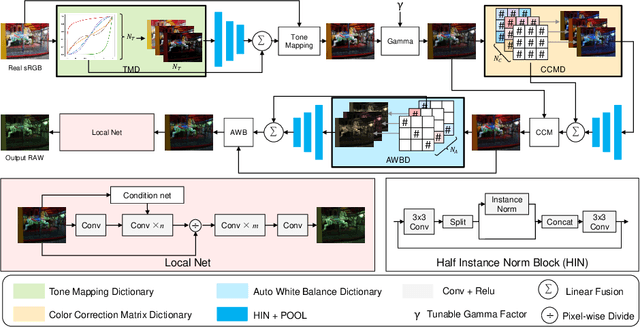
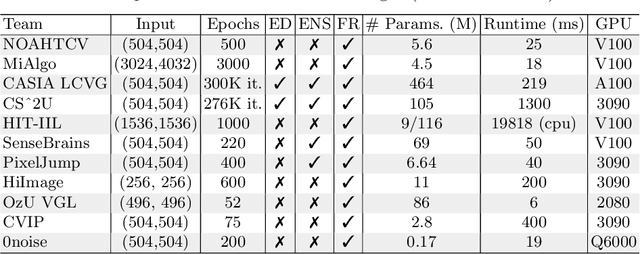
Cameras capture sensor RAW images and transform them into pleasant RGB images, suitable for the human eyes, using their integrated Image Signal Processor (ISP). Numerous low-level vision tasks operate in the RAW domain (e.g. image denoising, white balance) due to its linear relationship with the scene irradiance, wide-range of information at 12bits, and sensor designs. Despite this, RAW image datasets are scarce and more expensive to collect than the already large and public RGB datasets. This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. The proposed methods and benchmark establish the state-of-the-art for this low-level vision inverse problem, and generating realistic raw sensor readings can potentially benefit other tasks such as denoising and super-resolution.
AIM 2022 Challenge on Instagram Filter Removal: Methods and Results
Oct 17, 2022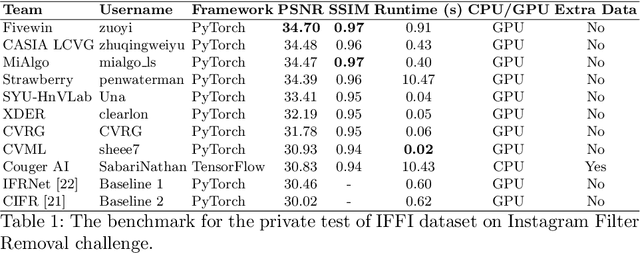

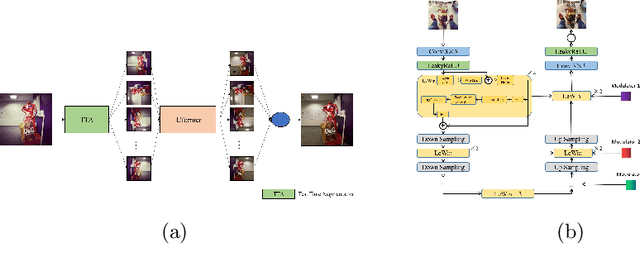
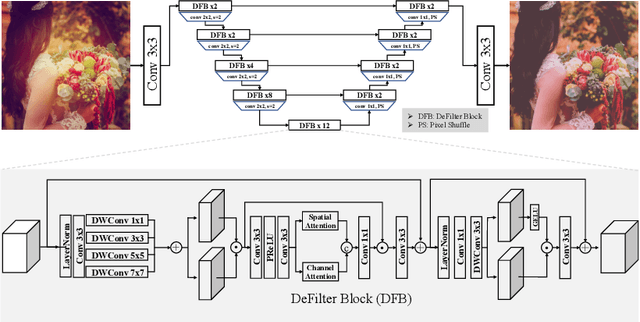
This paper introduces the methods and the results of AIM 2022 challenge on Instagram Filter Removal. Social media filters transform the images by consecutive non-linear operations, and the feature maps of the original content may be interpolated into a different domain. This reduces the overall performance of the recent deep learning strategies. The main goal of this challenge is to produce realistic and visually plausible images where the impact of the filters applied is mitigated while preserving the content. The proposed solutions are ranked in terms of the PSNR value with respect to the original images. There are two prior studies on this task as the baseline, and a total of 9 teams have competed in the final phase of the challenge. The comparison of qualitative results of the proposed solutions and the benchmark for the challenge are presented in this report.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022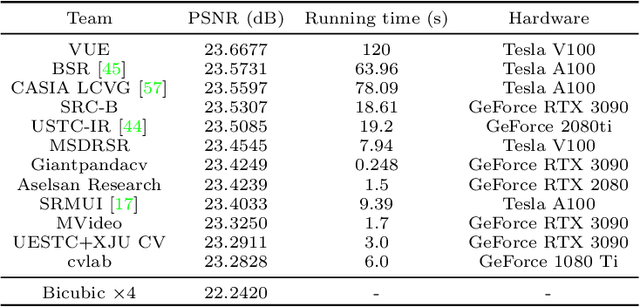
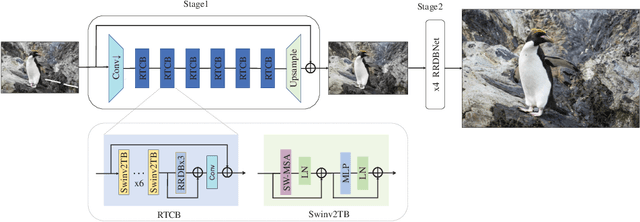

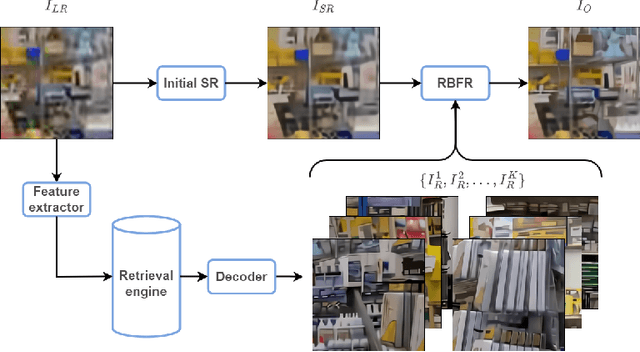
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
PalQuant: Accelerating High-precision Networks on Low-precision Accelerators
Aug 03, 2022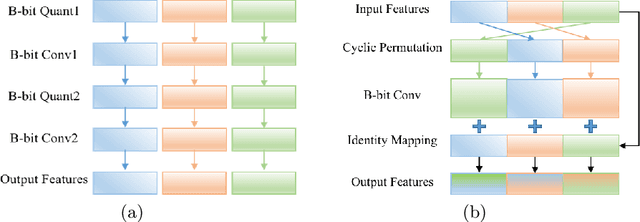
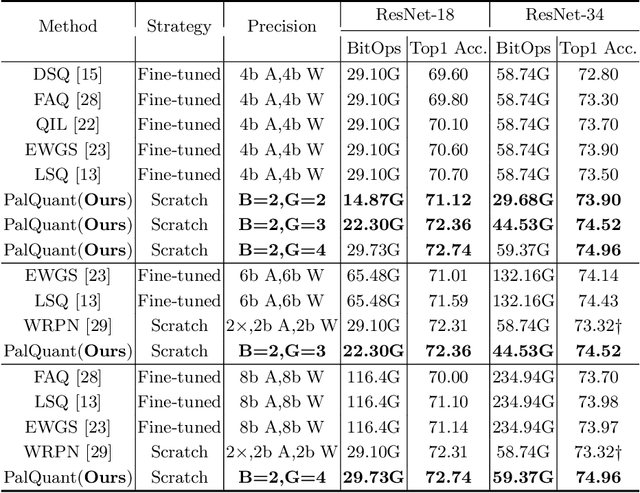
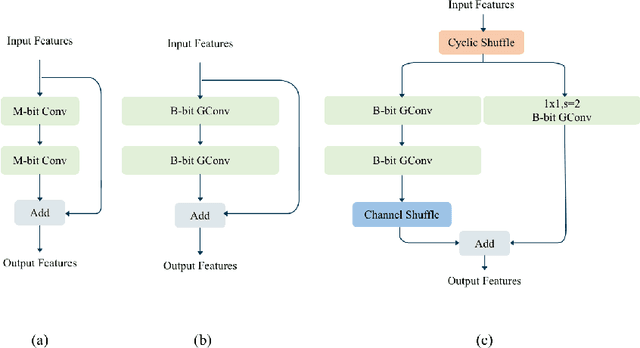
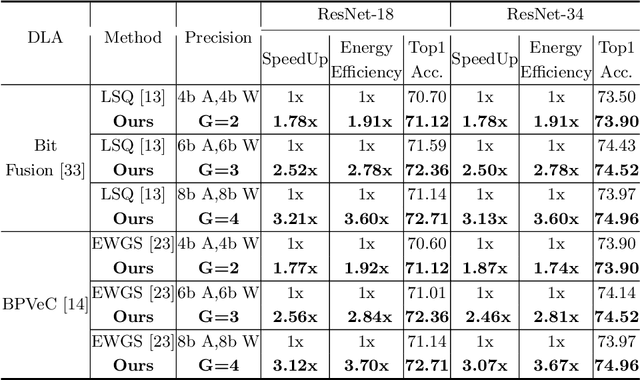
Recently low-precision deep learning accelerators (DLAs) have become popular due to their advantages in chip area and energy consumption, yet the low-precision quantized models on these DLAs bring in severe accuracy degradation. One way to achieve both high accuracy and efficient inference is to deploy high-precision neural networks on low-precision DLAs, which is rarely studied. In this paper, we propose the PArallel Low-precision Quantization (PalQuant) method that approximates high-precision computations via learning parallel low-precision representations from scratch. In addition, we present a novel cyclic shuffle module to boost the cross-group information communication between parallel low-precision groups. Extensive experiments demonstrate that PalQuant has superior performance to state-of-the-art quantization methods in both accuracy and inference speed, e.g., for ResNet-18 network quantization, PalQuant can obtain 0.52\% higher accuracy and 1.78$\times$ speedup simultaneously over their 4-bit counter-part on a state-of-the-art 2-bit accelerator. Code is available at \url{https://github.com/huqinghao/PalQuant}.
PKD: General Distillation Framework for Object Detectors via Pearson Correlation Coefficient
Jul 05, 2022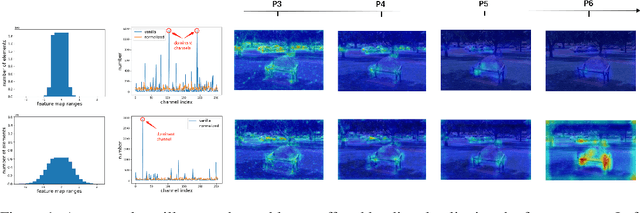
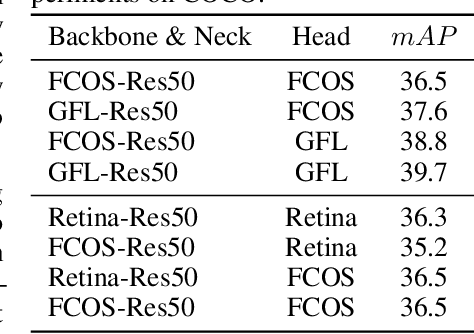
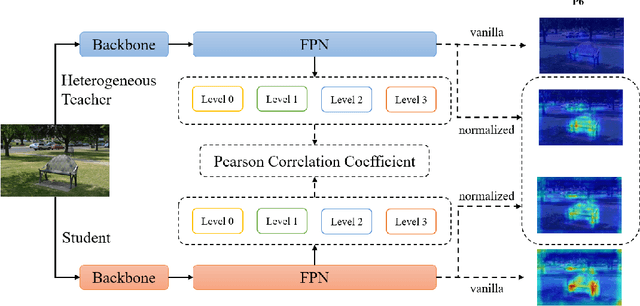
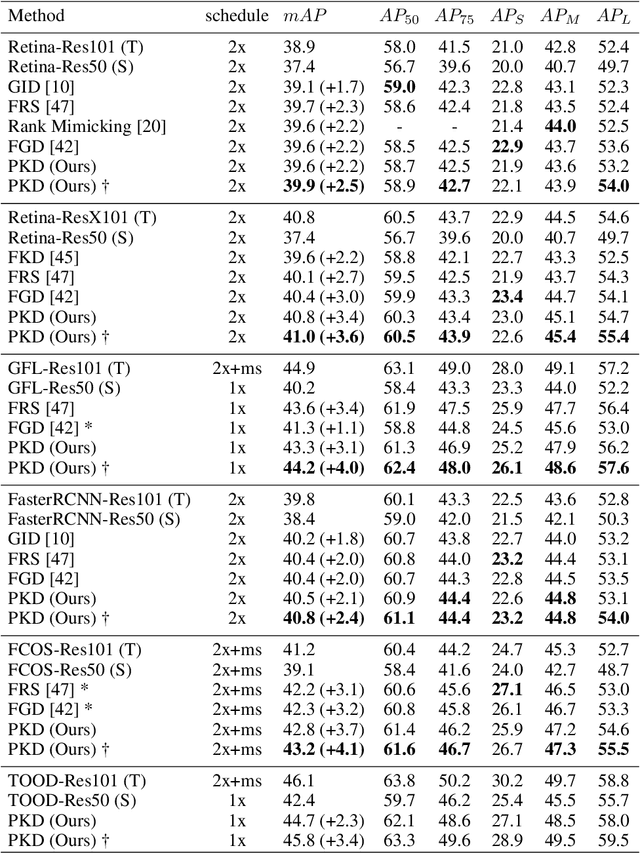
Knowledge distillation(KD) is a widely-used technique to train compact models in object detection. However, there is still a lack of study on how to distill between heterogeneous detectors. In this paper, we empirically find that better FPN features from a heterogeneous teacher detector can help the student although their detection heads and label assignments are different. However, directly aligning the feature maps to distill detectors suffers from two problems. First, the difference in feature magnitude between the teacher and the student could enforce overly strict constraints on the student. Second, the FPN stages and channels with large feature magnitude from the teacher model could dominate the gradient of distillation loss, which will overwhelm the effects of other features in KD and introduce much noise. To address the above issues, we propose to imitate features with Pearson Correlation Coefficient to focus on the relational information from the teacher and relax constraints on the magnitude of the features. Our method consistently outperforms the existing detection KD methods and works for both homogeneous and heterogeneous student-teacher pairs. Furthermore, it converges faster. With a powerful MaskRCNN-Swin detector as the teacher, ResNet-50 based RetinaNet and FCOS achieve 41.5% and 43.9% mAP on COCO2017, which are 4.1\% and 4.8\% higher than the baseline, respectively.