 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Representation Denoising for Robust Multi-view 3D Reconstruction
May 25, 2026Multi-view 3D reconstruction has achieved remarkable progress with the advent of feed-forward 3D reconstruction models. However, these models are typically trained and evaluated under ideal, degradation-free imaging conditions, whereas real-world observations often contain degradations that differ significantly from such settings. Improving robustness for multi-view 3D reconstruction under degraded conditions therefore remains an important challenge. We present Geometry-Aware Representation Denoising (GARD), a novel framework that performs diffusion-based multi-view restoration directly in the feature space of a feed-forward 3D reconstruction model. This design exploits the geometry-aware feature representations of the 3D reconstructor to effectively recover accurate scene geometry. Furthermore, by employing an additional RGB image decoder, the refined representations can also be used to restore high-quality RGB images, thereby enabling the simultaneous recovery of 3D scene geometry and high-quality imagery. Comprehensive experiments on the Depth Anything 3 (DA3) benchmark demonstrate the effectiveness of the proposed GARD framework.
DA-Flow: Degradation-Aware Optical Flow Estimation with Diffusion Models
Mar 24, 2026Optical flow models trained on high-quality data often degrade severely when confronted with real-world corruptions such as blur, noise, and compression artifacts. To overcome this limitation, we formulate Degradation-Aware Optical Flow, a new task targeting accurate dense correspondence estimation from real-world corrupted videos. Our key insight is that the intermediate representations of image restoration diffusion models are inherently corruption-aware but lack temporal awareness. To address this limitation, we lift the model to attend across adjacent frames via full spatio-temporal attention, and empirically demonstrate that the resulting features exhibit zero-shot correspondence capabilities. Based on this finding, we present DA-Flow, a hybrid architecture that fuses these diffusion features with convolutional features within an iterative refinement framework. DA-Flow substantially outperforms existing optical flow methods under severe degradation across multiple benchmarks.
Repurposing Video Diffusion Transformers for Robust Point Tracking
Dec 23, 2025Point tracking aims to localize corresponding points across video frames, serving as a fundamental task for 4D reconstruction, robotics, and video editing. Existing methods commonly rely on shallow convolutional backbones such as ResNet that process frames independently, lacking temporal coherence and producing unreliable matching costs under challenging conditions. Through systematic analysis, we find that video Diffusion Transformers (DiTs), pre-trained on large-scale real-world videos with spatio-temporal attention, inherently exhibit strong point tracking capability and robustly handle dynamic motions and frequent occlusions. We propose DiTracker, which adapts video DiTs through: (1) query-key attention matching, (2) lightweight LoRA tuning, and (3) cost fusion with a ResNet backbone. Despite training with 8 times smaller batch size, DiTracker achieves state-of-the-art performance on challenging ITTO benchmark and matches or outperforms state-of-the-art models on TAP-Vid benchmarks. Our work validates video DiT features as an effective and efficient foundation for point tracking.
Unified Diffusion Transformer for High-fidelity Text-Aware Image Restoration
Dec 09, 2025Text-Aware Image Restoration (TAIR) aims to recover high-quality images from low-quality inputs containing degraded textual content. While diffusion models provide strong generative priors for general image restoration, they often produce text hallucinations in text-centric tasks due to the absence of explicit linguistic knowledge. To address this, we propose UniT, a unified text restoration framework that integrates a Diffusion Transformer (DiT), a Vision-Language Model (VLM), and a Text Spotting Module (TSM) in an iterative fashion for high-fidelity text restoration. In UniT, the VLM extracts textual content from degraded images to provide explicit textual guidance. Simultaneously, the TSM, trained on diffusion features, generates intermediate OCR predictions at each denoising step, enabling the VLM to iteratively refine its guidance during the denoising process. Finally, the DiT backbone, leveraging its strong representational power, exploit these cues to recover fine-grained textual content while effectively suppressing text hallucinations. Experiments on the SA-Text and Real-Text benchmarks demonstrate that UniT faithfully reconstructs degraded text, substantially reduces hallucinations, and achieves state-of-the-art end-to-end F1-score performance in TAIR task.
Fine-Grained Perturbation Guidance via Attention Head Selection
Jun 12, 2025Recent guidance methods in diffusion models steer reverse sampling by perturbing the model to construct an implicit weak model and guide generation away from it. Among these approaches, attention perturbation has demonstrated strong empirical performance in unconditional scenarios where classifier-free guidance is not applicable. However, existing attention perturbation methods lack principled approaches for determining where perturbations should be applied, particularly in Diffusion Transformer (DiT) architectures where quality-relevant computations are distributed across layers. In this paper, we investigate the granularity of attention perturbations, ranging from the layer level down to individual attention heads, and discover that specific heads govern distinct visual concepts such as structure, style, and texture quality. Building on this insight, we propose "HeadHunter", a systematic framework for iteratively selecting attention heads that align with user-centric objectives, enabling fine-grained control over generation quality and visual attributes. In addition, we introduce SoftPAG, which linearly interpolates each selected head's attention map toward an identity matrix, providing a continuous knob to tune perturbation strength and suppress artifacts. Our approach not only mitigates the oversmoothing issues of existing layer-level perturbation but also enables targeted manipulation of specific visual styles through compositional head selection. We validate our method on modern large-scale DiT-based text-to-image models including Stable Diffusion 3 and FLUX.1, demonstrating superior performance in both general quality enhancement and style-specific guidance. Our work provides the first head-level analysis of attention perturbation in diffusion models, uncovering interpretable specialization within attention layers and enabling practical design of effective perturbation strategies.
Text-Aware Image Restoration with Diffusion Models
Jun 11, 2025

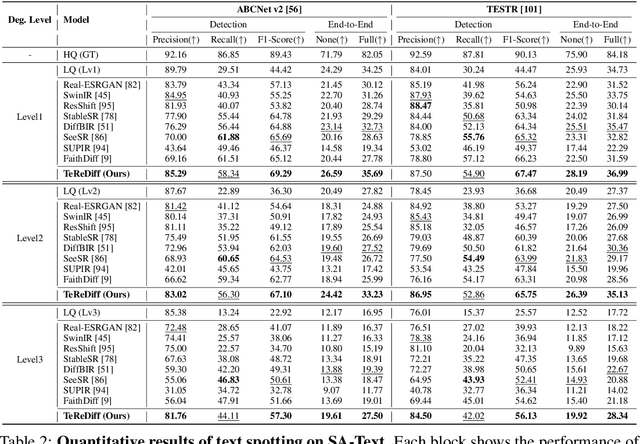

Image restoration aims to recover degraded images. However, existing diffusion-based restoration methods, despite great success in natural image restoration, often struggle to faithfully reconstruct textual regions in degraded images. Those methods frequently generate plausible but incorrect text-like patterns, a phenomenon we refer to as text-image hallucination. In this paper, we introduce Text-Aware Image Restoration (TAIR), a novel restoration task that requires the simultaneous recovery of visual contents and textual fidelity. To tackle this task, we present SA-Text, a large-scale benchmark of 100K high-quality scene images densely annotated with diverse and complex text instances. Furthermore, we propose a multi-task diffusion framework, called TeReDiff, that integrates internal features from diffusion models into a text-spotting module, enabling both components to benefit from joint training. This allows for the extraction of rich text representations, which are utilized as prompts in subsequent denoising steps. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art restoration methods, achieving significant gains in text recognition accuracy. See our project page: https://cvlab-kaist.github.io/TAIR/
A Noise is Worth Diffusion Guidance
Dec 05, 2024
Diffusion models excel in generating high-quality images. However, current diffusion models struggle to produce reliable images without guidance methods, such as classifier-free guidance (CFG). Are guidance methods truly necessary? Observing that noise obtained via diffusion inversion can reconstruct high-quality images without guidance, we focus on the initial noise of the denoising pipeline. By mapping Gaussian noise to `guidance-free noise', we uncover that small low-magnitude low-frequency components significantly enhance the denoising process, removing the need for guidance and thus improving both inference throughput and memory. Expanding on this, we propose \ours, a novel method that replaces guidance methods with a single refinement of the initial noise. This refined noise enables high-quality image generation without guidance, within the same diffusion pipeline. Our noise-refining model leverages efficient noise-space learning, achieving rapid convergence and strong performance with just 50K text-image pairs. We validate its effectiveness across diverse metrics and analyze how refined noise can eliminate the need for guidance. See our project page: https://cvlab-kaist.github.io/NoiseRefine/.
Self-Rectifying Diffusion Sampling with Perturbed-Attention Guidance
Mar 26, 2024



Recent studies have demonstrated that diffusion models are capable of generating high-quality samples, but their quality heavily depends on sampling guidance techniques, such as classifier guidance (CG) and classifier-free guidance (CFG). These techniques are often not applicable in unconditional generation or in various downstream tasks such as image restoration. In this paper, we propose a novel sampling guidance, called Perturbed-Attention Guidance (PAG), which improves diffusion sample quality across both unconditional and conditional settings, achieving this without requiring additional training or the integration of external modules. PAG is designed to progressively enhance the structure of samples throughout the denoising process. It involves generating intermediate samples with degraded structure by substituting selected self-attention maps in diffusion U-Net with an identity matrix, by considering the self-attention mechanisms' ability to capture structural information, and guiding the denoising process away from these degraded samples. In both ADM and Stable Diffusion, PAG surprisingly improves sample quality in conditional and even unconditional scenarios. Moreover, PAG significantly improves the baseline performance in various downstream tasks where existing guidances such as CG or CFG cannot be fully utilized, including ControlNet with empty prompts and image restoration such as inpainting and deblurring.