 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Representation Denoising for Robust Multi-view 3D Reconstruction
May 25, 2026Multi-view 3D reconstruction has achieved remarkable progress with the advent of feed-forward 3D reconstruction models. However, these models are typically trained and evaluated under ideal, degradation-free imaging conditions, whereas real-world observations often contain degradations that differ significantly from such settings. Improving robustness for multi-view 3D reconstruction under degraded conditions therefore remains an important challenge. We present Geometry-Aware Representation Denoising (GARD), a novel framework that performs diffusion-based multi-view restoration directly in the feature space of a feed-forward 3D reconstruction model. This design exploits the geometry-aware feature representations of the 3D reconstructor to effectively recover accurate scene geometry. Furthermore, by employing an additional RGB image decoder, the refined representations can also be used to restore high-quality RGB images, thereby enabling the simultaneous recovery of 3D scene geometry and high-quality imagery. Comprehensive experiments on the Depth Anything 3 (DA3) benchmark demonstrate the effectiveness of the proposed GARD framework.
On the limits and opportunities of AI reviewers: Reviewing the reviews of Nature-family papers with 45 expert scientists
May 20, 2026With the advancement of AI capabilities, AI reviewers are beginning to be deployed in scientific peer review, yet their capability and credibility remain in question: many scientists simply view them as probabilistic systems without the expertise to evaluate research, while other researchers are more optimistic about their readiness without concrete evidence. Understanding what AI reviewers do well, where they fall short, and what challenges remain is essential. However, existing evaluations of AI reviewers have focused on whether their verdicts match human verdicts (e.g., score alignment, acceptance prediction), which is insufficient to characterize their capabilities and limits. In this paper, we close this gap through a large-scale expert annotation study, in which 45 domain scientists in Physical, Biological, and Health Sciences spent 469 hours rating 2,960 individual criticisms (each targeting one specific aspect of a paper) from human-written and AI-generated reviews of 82 Nature-family papers on correctness, significance, and sufficiency of evidence. On a composite of all three dimensions, a reviewing agent powered by GPT-5.2 scores above each paper's top-rated human reviewer (60.0% vs. 48.2%, p = 0.009), while all three AI reviewers (including Gemini 3.0 Pro and Claude Opus 4.5) exceed the lowest-rated human across every dimension. AI reviewers' accurate criticisms are also more often rated significant and well-evidenced, and surface a distinct 26% of issues no human raises. However, AI reviewers overlap far more than humans do (21% vs. 3% for cross-reviewer pairs), and exhibit 16 recurring weaknesses humans do not share, such as limited subfield knowledge, lack of long context management over multiple files, and overly critical stance on minor issues. Overall, our results position current AI reviewers as complements to, not substitutes for, human reviewers.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
Unified Diffusion Transformer for High-fidelity Text-Aware Image Restoration
Dec 09, 2025Text-Aware Image Restoration (TAIR) aims to recover high-quality images from low-quality inputs containing degraded textual content. While diffusion models provide strong generative priors for general image restoration, they often produce text hallucinations in text-centric tasks due to the absence of explicit linguistic knowledge. To address this, we propose UniT, a unified text restoration framework that integrates a Diffusion Transformer (DiT), a Vision-Language Model (VLM), and a Text Spotting Module (TSM) in an iterative fashion for high-fidelity text restoration. In UniT, the VLM extracts textual content from degraded images to provide explicit textual guidance. Simultaneously, the TSM, trained on diffusion features, generates intermediate OCR predictions at each denoising step, enabling the VLM to iteratively refine its guidance during the denoising process. Finally, the DiT backbone, leveraging its strong representational power, exploit these cues to recover fine-grained textual content while effectively suppressing text hallucinations. Experiments on the SA-Text and Real-Text benchmarks demonstrate that UniT faithfully reconstructs degraded text, substantially reduces hallucinations, and achieves state-of-the-art end-to-end F1-score performance in TAIR task.
Text-Aware Image Restoration with Diffusion Models
Jun 11, 2025

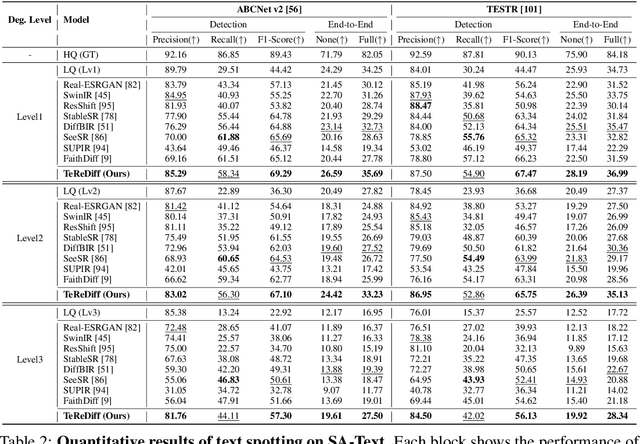

Image restoration aims to recover degraded images. However, existing diffusion-based restoration methods, despite great success in natural image restoration, often struggle to faithfully reconstruct textual regions in degraded images. Those methods frequently generate plausible but incorrect text-like patterns, a phenomenon we refer to as text-image hallucination. In this paper, we introduce Text-Aware Image Restoration (TAIR), a novel restoration task that requires the simultaneous recovery of visual contents and textual fidelity. To tackle this task, we present SA-Text, a large-scale benchmark of 100K high-quality scene images densely annotated with diverse and complex text instances. Furthermore, we propose a multi-task diffusion framework, called TeReDiff, that integrates internal features from diffusion models into a text-spotting module, enabling both components to benefit from joint training. This allows for the extraction of rich text representations, which are utilized as prompts in subsequent denoising steps. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art restoration methods, achieving significant gains in text recognition accuracy. See our project page: https://cvlab-kaist.github.io/TAIR/
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
MoDiTalker: Motion-Disentangled Diffusion Model for High-Fidelity Talking Head Generation
Mar 28, 2024



Conventional GAN-based models for talking head generation often suffer from limited quality and unstable training. Recent approaches based on diffusion models aimed to address these limitations and improve fidelity. However, they still face challenges, including extensive sampling times and difficulties in maintaining temporal consistency due to the high stochasticity of diffusion models. To overcome these challenges, we propose a novel motion-disentangled diffusion model for high-quality talking head generation, dubbed MoDiTalker. We introduce the two modules: audio-to-motion (AToM), designed to generate a synchronized lip motion from audio, and motion-to-video (MToV), designed to produce high-quality head video following the generated motion. AToM excels in capturing subtle lip movements by leveraging an audio attention mechanism. In addition, MToV enhances temporal consistency by leveraging an efficient tri-plane representation. Our experiments conducted on standard benchmarks demonstrate that our model achieves superior performance compared to existing models. We also provide comprehensive ablation studies and user study results.
Hybrid Video Diffusion Models with 2D Triplane and 3D Wavelet Representation
Feb 21, 2024



Generating high-quality videos that synthesize desired realistic content is a challenging task due to their intricate high-dimensionality and complexity of videos. Several recent diffusion-based methods have shown comparable performance by compressing videos to a lower-dimensional latent space, using traditional video autoencoder architecture. However, such method that employ standard frame-wise 2D and 3D convolution fail to fully exploit the spatio-temporal nature of videos. To address this issue, we propose a novel hybrid video diffusion model, called HVDM, which can capture spatio-temporal dependencies more effectively. The HVDM is trained by a hybrid video autoencoder which extracts a disentangled representation of the video including: (i) a global context information captured by a 2D projected latent (ii) a local volume information captured by 3D convolutions with wavelet decomposition (iii) a frequency information for improving the video reconstruction. Based on this disentangled representation, our hybrid autoencoder provide a more comprehensive video latent enriching the generated videos with fine structures and details. Experiments on video generation benchamarks (UCF101, SkyTimelapse, and TaiChi) demonstrate that the proposed approach achieves state-of-the-art video generation quality, showing a wide range of video applications (e.g., long video generation, image-to-video, and video dynamics control).
Towards Flexible Inductive Bias via Progressive Reparameterization Scheduling
Oct 04, 2022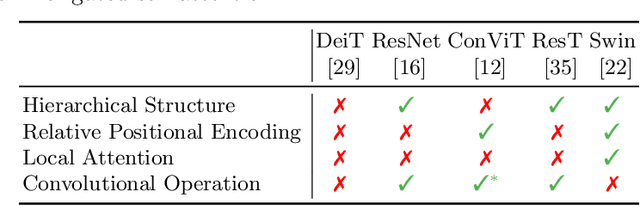
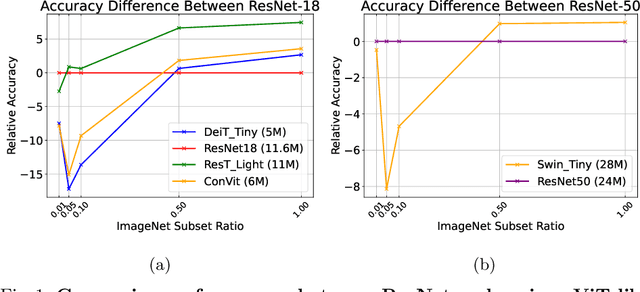
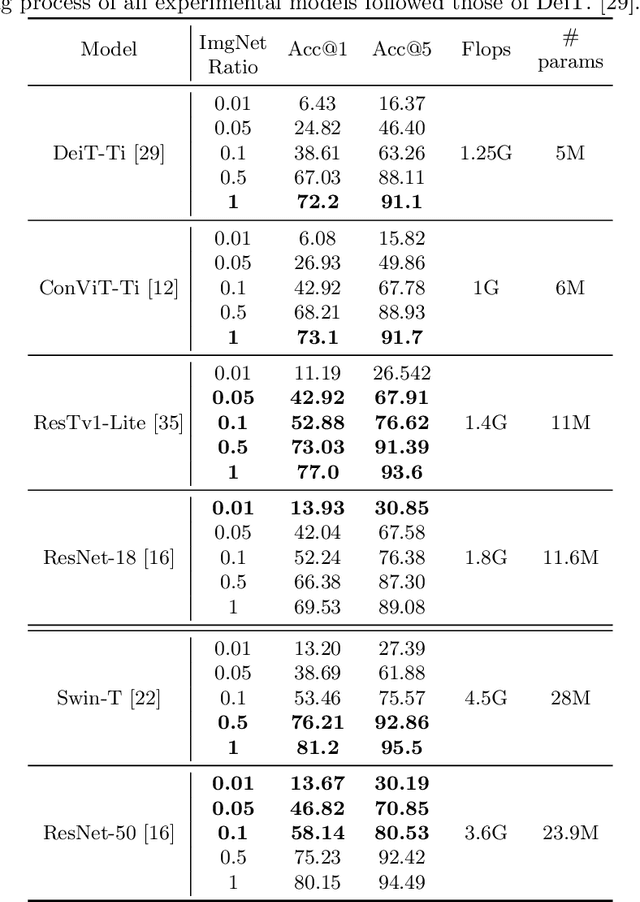
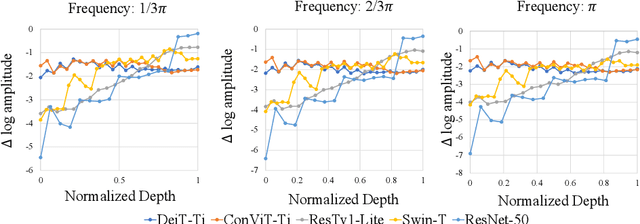
There are two de facto standard architectures in recent computer vision: Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). Strong inductive biases of convolutions help the model learn sample effectively, but such strong biases also limit the upper bound of CNNs when sufficient data are available. On the contrary, ViT is inferior to CNNs for small data but superior for sufficient data. Recent approaches attempt to combine the strengths of these two architectures. However, we show these approaches overlook that the optimal inductive bias also changes according to the target data scale changes by comparing various models' accuracy on subsets of sampled ImageNet at different ratios. In addition, through Fourier analysis of feature maps, the model's response patterns according to signal frequency changes, we observe which inductive bias is advantageous for each data scale. The more convolution-like inductive bias is included in the model, the smaller the data scale is required where the ViT-like model outperforms the ResNet performance. To obtain a model with flexible inductive bias on the data scale, we show reparameterization can interpolate inductive bias between convolution and self-attention. By adjusting the number of epochs the model stays in the convolution, we show that reparameterization from convolution to self-attention interpolates the Fourier analysis pattern between CNNs and ViTs. Adapting these findings, we propose Progressive Reparameterization Scheduling (PRS), in which reparameterization adjusts the required amount of convolution-like or self-attention-like inductive bias per layer. For small-scale datasets, our PRS performs reparameterization from convolution to self-attention linearly faster at the late stage layer. PRS outperformed previous studies on the small-scale dataset, e.g., CIFAR-100.
LANIT: Language-Driven Image-to-Image Translation for Unlabeled Data
Aug 31, 2022
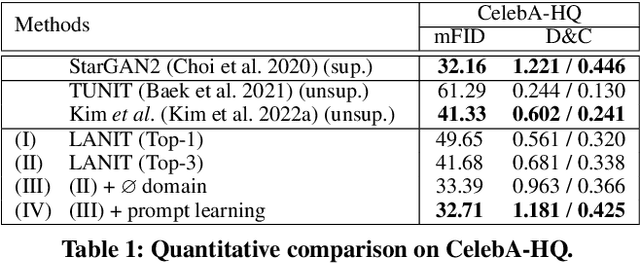
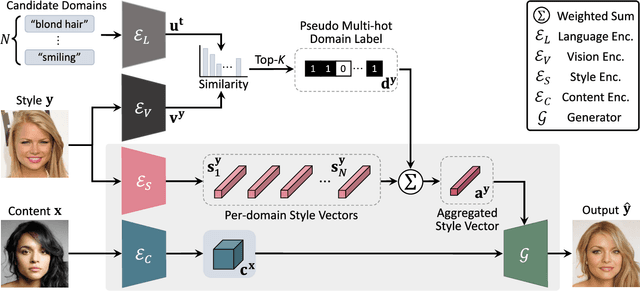
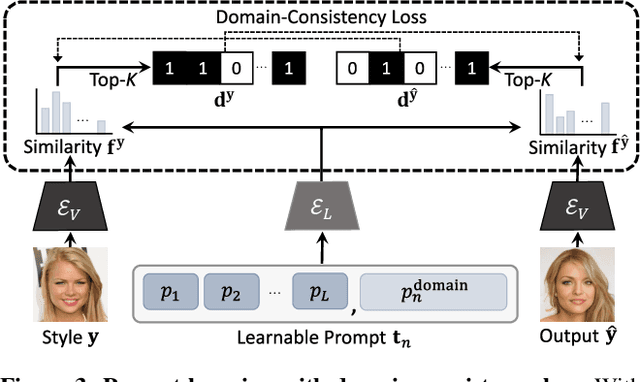
Existing techniques for image-to-image translation commonly have suffered from two critical problems: heavy reliance on per-sample domain annotation and/or inability of handling multiple attributes per image. Recent methods adopt clustering approaches to easily provide per-sample annotations in an unsupervised manner. However, they cannot account for the real-world setting; one sample may have multiple attributes. In addition, the semantics of the clusters are not easily coupled to human understanding. To overcome these, we present a LANguage-driven Image-to-image Translation model, dubbed LANIT. We leverage easy-to-obtain candidate domain annotations given in texts for a dataset and jointly optimize them during training. The target style is specified by aggregating multi-domain style vectors according to the multi-hot domain assignments. As the initial candidate domain texts might be inaccurate, we set the candidate domain texts to be learnable and jointly fine-tune them during training. Furthermore, we introduce a slack domain to cover samples that are not covered by the candidate domains. Experiments on several standard benchmarks demonstrate that LANIT achieves comparable or superior performance to the existing model.