 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOASIS: Open Agent Social Interaction Simulations with One Million Agents
Nov 26, 2024



There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
OASIS: Open Agents Social Interaction Simulations on One Million Agents
Nov 21, 2024There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
GLDesigner: Leveraging Multi-Modal LLMs as Designer for Enhanced Aesthetic Text Glyph Layouts
Nov 18, 2024



Text logo design heavily relies on the creativity and expertise of professional designers, in which arranging element layouts is one of the most important procedures. However, few attention has been paid to this specific task which needs to take precise textural details and user constraints into consideration, but only on the broader tasks such as document/poster layout generation. In this paper, we propose a VLM-based framework that generates content-aware text logo layouts by integrating multi-modal inputs with user constraints, supporting a more flexible and stable layout design in real-world applications. We introduce two model techniques to reduce the computation for processing multiple glyph images simultaneously, while does not face performance degradation. To support instruction-tuning of out model, we construct two extensive text logo datasets, which are 5x more larger than the existing public dataset. Except for the geometric annotations (e.g. text masks and character recognition), we also compliment with comprehensive layout descriptions in natural language format, for more effective training to have reasoning ability when dealing with complex layouts and custom user constraints. Experimental studies demonstrate the effectiveness of our proposed model and datasets, when comparing with previous methods in various benchmarks to evaluate geometric aesthetics and human preferences. The code and datasets will be publicly available.
LLMs Can Evolve Continually on Modality for X-Modal Reasoning
Oct 26, 2024Multimodal Large Language Models (MLLMs) have gained significant attention due to their impressive capabilities in multimodal understanding. However, existing methods rely heavily on extensive modal-specific pretraining and joint-modal tuning, leading to significant computational burdens when expanding to new modalities. In this paper, we propose PathWeave, a flexible and scalable framework with modal-Path sWitching and ExpAnsion abilities that enables MLLMs to continually EVolve on modalities for $\mathbb{X}$-modal reasoning. We leverage the concept of Continual Learning and develop an incremental training strategy atop pre-trained MLLMs, enabling their expansion to new modalities using uni-modal data, without executing joint-modal pretraining. In detail, a novel Adapter-in-Adapter (AnA) framework is introduced, in which uni-modal and cross-modal adapters are seamlessly integrated to facilitate efficient modality alignment and collaboration. Additionally, an MoE-based gating module is applied between two types of adapters to further enhance the multimodal interaction. To investigate the proposed method, we establish a challenging benchmark called Continual Learning of Modality (MCL), which consists of high-quality QA data from five distinct modalities: image, video, audio, depth and point cloud. Extensive experiments demonstrate the effectiveness of the proposed AnA framework on learning plasticity and memory stability during continual learning. Furthermore, PathWeave performs comparably to state-of-the-art MLLMs while concurrently reducing parameter training burdens by 98.73%. Our code locates at https://github.com/JiazuoYu/PathWeave
GSSF: Generalized Structural Sparse Function for Deep Cross-modal Metric Learning
Oct 20, 2024Cross-modal metric learning is a prominent research topic that bridges the semantic heterogeneity between vision and language. Existing methods frequently utilize simple cosine or complex distance metrics to transform the pairwise features into a similarity score, which suffers from an inadequate or inefficient capability for distance measurements. Consequently, we propose a Generalized Structural Sparse Function to dynamically capture thorough and powerful relationships across modalities for pair-wise similarity learning while remaining concise but efficient. Specifically, the distance metric delicately encapsulates two formats of diagonal and block-diagonal terms, automatically distinguishing and highlighting the cross-channel relevancy and dependency inside a structured and organized topology. Hence, it thereby empowers itself to adapt to the optimal matching patterns between the paired features and reaches a sweet spot between model complexity and capability. Extensive experiments on cross-modal and two extra uni-modal retrieval tasks (image-text retrieval, person re-identification, fine-grained image retrieval) have validated its superiority and flexibility over various popular retrieval frameworks. More importantly, we further discover that it can be seamlessly incorporated into multiple application scenarios, and demonstrates promising prospects from Attention Mechanism to Knowledge Distillation in a plug-and-play manner. Our code is publicly available at: https://github.com/Paranioar/GSSF.
Adversarial Training: A Survey
Oct 19, 2024



Adversarial training (AT) refers to integrating adversarial examples -- inputs altered with imperceptible perturbations that can significantly impact model predictions -- into the training process. Recent studies have demonstrated the effectiveness of AT in improving the robustness of deep neural networks against diverse adversarial attacks. However, a comprehensive overview of these developments is still missing. This survey addresses this gap by reviewing a broad range of recent and representative studies. Specifically, we first describe the implementation procedures and practical applications of AT, followed by a comprehensive review of AT techniques from three perspectives: data enhancement, network design, and training configurations. Lastly, we discuss common challenges in AT and propose several promising directions for future research.
High-Precision Dichotomous Image Segmentation via Probing Diffusion Capacity
Oct 14, 2024



In the realm of high-resolution (HR), fine-grained image segmentation, the primary challenge is balancing broad contextual awareness with the precision required for detailed object delineation, capturing intricate details and the finest edges of objects. Diffusion models, trained on vast datasets comprising billions of image-text pairs, such as SD V2.1, have revolutionized text-to-image synthesis by delivering exceptional quality, fine detail resolution, and strong contextual awareness, making them an attractive solution for high-resolution image segmentation. To this end, we propose DiffDIS, a diffusion-driven segmentation model that taps into the potential of the pre-trained U-Net within diffusion models, specifically designed for high-resolution, fine-grained object segmentation. By leveraging the robust generalization capabilities and rich, versatile image representation prior of the SD models, coupled with a task-specific stable one-step denoising approach, we significantly reduce the inference time while preserving high-fidelity, detailed generation. Additionally, we introduce an auxiliary edge generation task to not only enhance the preservation of fine details of the object boundaries, but reconcile the probabilistic nature of diffusion with the deterministic demands of segmentation. With these refined strategies in place, DiffDIS serves as a rapid object mask generation model, specifically optimized for generating detailed binary maps at high resolutions, while demonstrating impressive accuracy and swift processing. Experiments on the DIS5K dataset demonstrate the superiority of DiffDIS, achieving state-of-the-art results through a streamlined inference process. Our code will be made publicly available.
Underwater Object Detection in the Era of Artificial Intelligence: Current, Challenge, and Future
Oct 08, 2024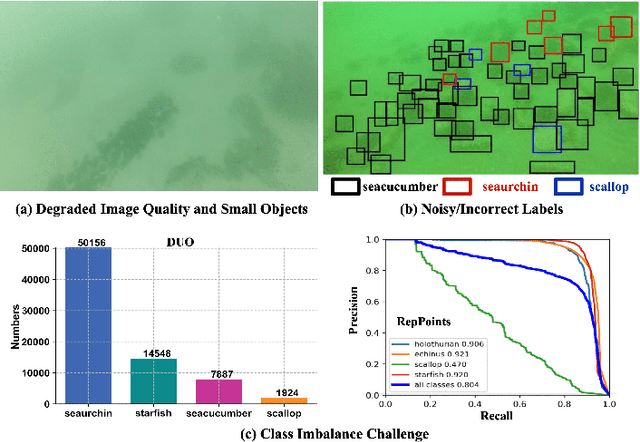

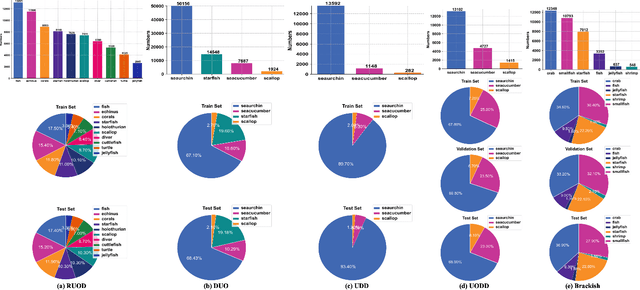
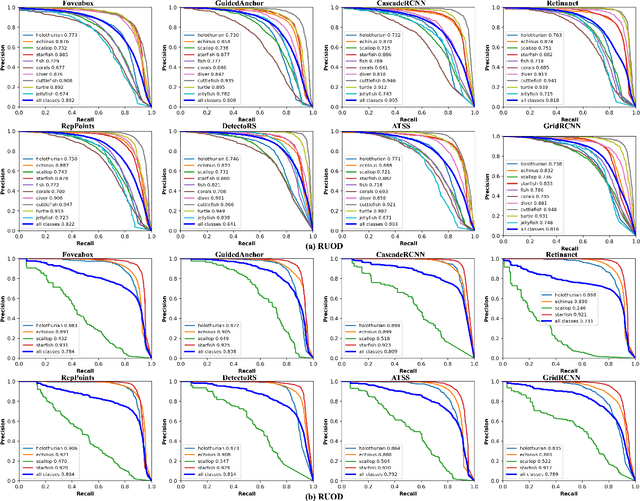
Underwater object detection (UOD), aiming to identify and localise the objects in underwater images or videos, presents significant challenges due to the optical distortion, water turbidity, and changing illumination in underwater scenes. In recent years, artificial intelligence (AI) based methods, especially deep learning methods, have shown promising performance in UOD. To further facilitate future advancements, we comprehensively study AI-based UOD. In this survey, we first categorise existing algorithms into traditional machine learning-based methods and deep learning-based methods, and summarise them by considering learning strategy, experimental dataset, utilised features or frameworks, and learning stage. Next, we discuss the potential challenges and suggest possible solutions and new directions. We also perform both quantitative and qualitative evaluations of mainstream algorithms across multiple benchmark datasets by considering the diverse and biased experimental setups. Finally, we introduce two off-the-shelf detection analysis tools, Diagnosis and TIDE, which well-examine the effects of object characteristics and various types of errors on detectors. These tools help identify the strengths and weaknesses of detectors, providing insigts for further improvement. The source codes, trained models, utilised datasets, detection results, and detection analysis tools are public available at \url{https://github.com/LongChenCV/UODReview}, and will be regularly updated.
High-Performance Few-Shot Segmentation with Foundation Models: An Empirical Study
Sep 10, 2024Existing few-shot segmentation (FSS) methods mainly focus on designing novel support-query matching and self-matching mechanisms to exploit implicit knowledge in pre-trained backbones. However, the performance of these methods is often constrained by models pre-trained on classification tasks. The exploration of what types of pre-trained models can provide more beneficial implicit knowledge for FSS remains limited. In this paper, inspired by the representation consistency of foundational computer vision models, we develop a FSS framework based on foundation models. To be specific, we propose a simple approach to extract implicit knowledge from foundation models to construct coarse correspondence and introduce a lightweight decoder to refine coarse correspondence for fine-grained segmentation. We systematically summarize the performance of various foundation models on FSS and discover that the implicit knowledge within some of these models is more beneficial for FSS than models pre-trained on classification tasks. Extensive experiments on two widely used datasets demonstrate the effectiveness of our approach in leveraging the implicit knowledge of foundation models. Notably, the combination of DINOv2 and DFN exceeds previous state-of-the-art methods by 17.5% on COCO-20i. Code is available at https://github.com/DUT-CSJ/FoundationFSS.
CNN-Transformer Rectified Collaborative Learning for Medical Image Segmentation
Aug 27, 2024



Automatic and precise medical image segmentation (MIS) is of vital importance for clinical diagnosis and analysis. Current MIS methods mainly rely on the convolutional neural network (CNN) or self-attention mechanism (Transformer) for feature modeling. However, CNN-based methods suffer from the inaccurate localization owing to the limited global dependency while Transformer-based methods always present the coarse boundary for the lack of local emphasis. Although some CNN-Transformer hybrid methods are designed to synthesize the complementary local and global information for better performance, the combination of CNN and Transformer introduces numerous parameters and increases the computation cost. To this end, this paper proposes a CNN-Transformer rectified collaborative learning (CTRCL) framework to learn stronger CNN-based and Transformer-based models for MIS tasks via the bi-directional knowledge transfer between them. Specifically, we propose a rectified logit-wise collaborative learning (RLCL) strategy which introduces the ground truth to adaptively select and rectify the wrong regions in student soft labels for accurate knowledge transfer in the logit space. We also propose a class-aware feature-wise collaborative learning (CFCL) strategy to achieve effective knowledge transfer between CNN-based and Transformer-based models in the feature space by granting their intermediate features the similar capability of category perception. Extensive experiments on three popular MIS benchmarks demonstrate that our CTRCL outperforms most state-of-the-art collaborative learning methods under different evaluation metrics.