 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Inference for Stochastic Gradient Descent Beyond Finite Variance
May 25, 2026Stochastic gradient descent (SGD) is a foundational algorithm for large-scale statistical learning and stochastic optimization. However, statistical inference based on SGD iterates remains challenging when stochastic gradients have infinite variance, as the relevant limiting distributions depend on unknown nuisance parameters. In this paper, we develop an efficient, model-agnostic methodology for constructing confidence regions from SGD trajectories that applies in both finite- and infinite-variance regimes. The procedure is based on a joint weak convergence result for the Polyak-Ruppert averaged estimator and an empirical second-moment normalizer constructed from stochastic gradients along the SGD trajectory. This joint limit yields a self-normalized statistic in which the leading tail-dependent scaling terms cancel. We then use a subsampling calibration scheme to estimate the relevant critical values, avoiding explicit estimation of tail indices, slowly varying functions, or stable-law parameters. The resulting confidence regions are straightforward to implement and are asymptotically valid under both the finite- and infinite-second-moment regimes. Simulation studies show reliable coverage in various settings, supporting the proposed method as a practical tool for uncertainty quantification in stochastic optimization.
Walk the Talk: Bridging the Reasoning-Action Gap for Thinking with Images via Multimodal Agentic Policy Optimization
Apr 08, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have incentivized models to ``think with images'' by actively invoking visual tools during multi-turn reasoning. The common Reinforcement Learning (RL) practice of relying on outcome-based rewards ignores the fact that textual plausibility often masks executive failure, meaning that models may exhibit intuitive textual reasoning while executing imprecise or irrelevant visual actions within their agentic reasoning trajectories. This reasoning-action discrepancy introduces noise that accumulates throughout the multi-turn reasoning process, severely degrading the model's multimodal reasoning capabilities and potentially leading to training collapse. In this paper, we introduce Multimodal Agentic Policy Optimization (MAPO), bridging the gap between textual reasoning and visual actions generated by models within their Multimodal Chain-of-Thought (MCoT). Specifically, MAPO mandates the model to generate explicit textual descriptions for the visual content obtained via tool usage. We then employ a novel advantage estimation that couples the semantic alignment between these descriptions and the actual observations with the task reward. Theoretical findings are provided to justify the rationale behind MAPO, which inherently reduces the variance of gradients, and extensive experiments demonstrate that our method achieves superior performance across multiple visual reasoning benchmarks.
A-SelecT: Automatic Timestep Selection for Diffusion Transformer Representation Learning
Mar 25, 2026Diffusion models have significantly reshaped the field of generative artificial intelligence and are now increasingly explored for their capacity in discriminative representation learning. Diffusion Transformer (DiT) has recently gained attention as a promising alternative to conventional U-Net-based diffusion models, demonstrating a promising avenue for downstream discriminative tasks via generative pre-training. However, its current training efficiency and representational capacity remain largely constrained due to the inadequate timestep searching and insufficient exploitation of DiT-specific feature representations. In light of this view, we introduce Automatically Selected Timestep (A-SelecT) that dynamically pinpoints DiT's most information-rich timestep from the selected transformer feature in a single run, eliminating the need for both computationally intensive exhaustive timestep searching and suboptimal discriminative feature selection. Extensive experiments on classification and segmentation benchmarks demonstrate that DiT, empowered by A-SelecT, surpasses all prior diffusion-based attempts efficiently and effectively.
On-the-Fly VLA Adaptation via Test-Time Reinforcement Learning
Jan 13, 2026Vision-Language-Action models have recently emerged as a powerful paradigm for general-purpose robot learning, enabling agents to map visual observations and natural-language instructions into executable robotic actions. Though popular, they are primarily trained via supervised fine-tuning or training-time reinforcement learning, requiring explicit fine-tuning phases, human interventions, or controlled data collection. Consequently, existing methods remain unsuitable for challenging simulated- or physical-world deployments, where robots must respond autonomously and flexibly to evolving environments. To address this limitation, we introduce a Test-Time Reinforcement Learning for VLAs (TT-VLA), a framework that enables on-the-fly policy adaptation during inference. TT-VLA formulates a dense reward mechanism that leverages step-by-step task-progress signals to refine action policies during test time while preserving the SFT/RL-trained priors, making it an effective supplement to current VLA models. Empirical results show that our approach enhances overall adaptability, stability, and task success in dynamic, previously unseen scenarios under simulated and real-world settings. We believe TT-VLA offers a principled step toward self-improving, deployment-ready VLAs.
Deep But Reliable: Advancing Multi-turn Reasoning for Thinking with Images
Dec 19, 2025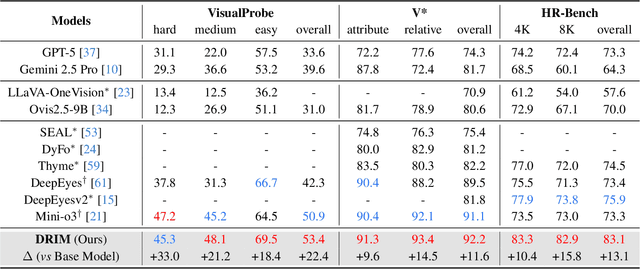
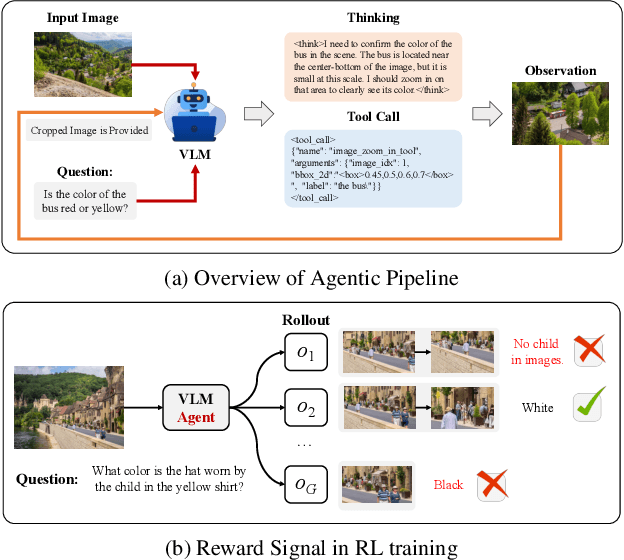
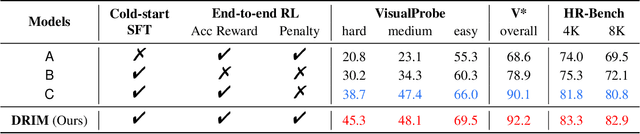
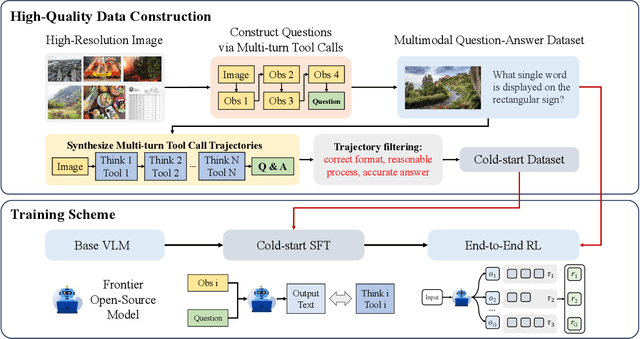
Recent advances in large Vision-Language Models (VLMs) have exhibited strong reasoning capabilities on complex visual tasks by thinking with images in their Chain-of-Thought (CoT), which is achieved by actively invoking tools to analyze visual inputs rather than merely perceiving them. However, existing models often struggle to reflect on and correct themselves when attempting incorrect reasoning trajectories. To address this limitation, we propose DRIM, a model that enables deep but reliable multi-turn reasoning when thinking with images in its multimodal CoT. Our pipeline comprises three stages: data construction, cold-start SFT and RL. Based on a high-resolution image dataset, we construct high-difficulty and verifiable visual question-answer pairs, where solving each task requires multi-turn tool calls to reach the correct answer. In the SFT stage, we collect tool trajectories as cold-start data, guiding a multi-turn reasoning pattern. In the RL stage, we introduce redundancy-penalized policy optimization, which incentivizes the model to develop a self-reflective reasoning pattern. The basic idea is to impose judgment on reasoning trajectories and penalize those that produce incorrect answers without sufficient multi-scale exploration. Extensive experiments demonstrate that DRIM achieves superior performance on visual understanding benchmarks.
Listening for "You": Enhancing Speech Image Retrieval via Target Speaker Extraction
Sep 11, 2025Image retrieval using spoken language cues has emerged as a promising direction in multimodal perception, yet leveraging speech in multi-speaker scenarios remains challenging. We propose a novel Target Speaker Speech-Image Retrieval task and a framework that learns the relationship between images and multi-speaker speech signals in the presence of a target speaker. Our method integrates pre-trained self-supervised audio encoders with vision models via target speaker-aware contrastive learning, conditioned on a Target Speaker Extraction and Retrieval module. This enables the system to extract spoken commands from the target speaker and align them with corresponding images. Experiments on SpokenCOCO2Mix and SpokenCOCO3Mix show that TSRE significantly outperforms existing methods, achieving 36.3% and 29.9% Recall@1 in 2 and 3 speaker scenarios, respectively - substantial improvements over single speaker baselines and state-of-the-art models. Our approach demonstrates potential for real-world deployment in assistive robotics and multimodal interaction systems.
Improved Analysis for Sign-based Methods with Momentum Updates
Jul 16, 2025



In this paper, we present enhanced analysis for sign-based optimization algorithms with momentum updates. Traditional sign-based methods, under the separable smoothness assumption, guarantee a convergence rate of $\mathcal{O}(T^{-1/4})$, but they either require large batch sizes or assume unimodal symmetric stochastic noise. To address these limitations, we demonstrate that signSGD with momentum can achieve the same convergence rate using constant batch sizes without additional assumptions. Our analysis, under the standard $l_2$-smoothness condition, improves upon the result of the prior momentum-based signSGD method by a factor of $\mathcal{O}(d^{1/2})$, where $d$ is the problem dimension. Furthermore, we explore sign-based methods with majority vote in distributed settings and show that the proposed momentum-based method yields convergence rates of $\mathcal{O}\left( d^{1/2}T^{-1/2} + dn^{-1/2} \right)$ and $\mathcal{O}\left( \max \{ d^{1/4}T^{-1/4}, d^{1/10}T^{-1/5} \} \right)$, which outperform the previous results of $\mathcal{O}\left( dT^{-1/4} + dn^{-1/2} \right)$ and $\mathcal{O}\left( d^{3/8}T^{-1/8} \right)$, respectively. Numerical experiments further validate the effectiveness of the proposed methods.
Discounted Online Convex Optimization: Uniform Regret Across a Continuous Interval
May 26, 2025Reflecting the greater significance of recent history over the distant past in non-stationary environments, $\lambda$-discounted regret has been introduced in online convex optimization (OCO) to gracefully forget past data as new information arrives. When the discount factor $\lambda$ is given, online gradient descent with an appropriate step size achieves an $O(1/\sqrt{1-\lambda})$ discounted regret. However, the value of $\lambda$ is often not predetermined in real-world scenarios. This gives rise to a significant open question: is it possible to develop a discounted algorithm that adapts to an unknown discount factor. In this paper, we affirmatively answer this question by providing a novel analysis to demonstrate that smoothed OGD (SOGD) achieves a uniform $O(\sqrt{\log T/1-\lambda})$ discounted regret, holding for all values of $\lambda$ across a continuous interval simultaneously. The basic idea is to maintain multiple OGD instances to handle different discount factors, and aggregate their outputs sequentially by an online prediction algorithm named as Discounted-Normal-Predictor (DNP) (Kapralov and Panigrahy,2010). Our analysis reveals that DNP can combine the decisions of two experts, even when they operate on discounted regret with different discount factors.
Cream of the Crop: Harvesting Rich, Scalable and Transferable Multi-Modal Data for Instruction Fine-Tuning
Mar 17, 2025The hypothesis that pretrained large language models (LLMs) necessitate only minimal supervision during the fine-tuning (SFT) stage (Zhou et al., 2024) has been substantiated by recent advancements in data curation and selection research. However, their stability and generalizability are compromised due to the vulnerability to experimental setups and validation protocols, falling short of surpassing random sampling (Diddee & Ippolito, 2024; Xia et al., 2024b). Built upon LLMs, multi-modal LLMs (MLLMs), combined with the sheer token volume and heightened heterogeneity of data sources, amplify both the significance and complexity of data selection. To harvest multi-modal instructional data in a robust and efficient manner, we re-define the granularity of the quality metric by decomposing it into 14 vision-language-related capabilities, and introduce multi-modal rich scorers to evaluate the capabilities of each data candidate. To promote diversity, in light of the inherent objective of the alignment stage, we take interaction style as diversity indicator and use a multi-modal rich styler to identify data instruction patterns. In doing so, our multi-modal rich scorers and styler (mmSSR) guarantee that high-scoring information is conveyed to users in diversified forms. Free from embedding-based clustering or greedy sampling, mmSSR efficiently scales to millions of data with varying budget constraints, supports customization for general or specific capability acquisition, and facilitates training-free generalization to new domains for curation. Across 10+ experimental settings, validated by 14 multi-modal benchmarks, we demonstrate consistent improvements over random sampling, baseline strategies and state-of-the-art selection methods, achieving 99.1% of full performance with only 30% of the 2.6M data.
Exploring the Adversarial Vulnerabilities of Vision-Language-Action Models in Robotics
Nov 22, 2024



Recently in robotics, Vision-Language-Action (VLA) models have emerged as a transformative approach, enabling robots to execute complex tasks by integrating visual and linguistic inputs within an end-to-end learning framework. While VLA models offer significant capabilities, they also introduce new attack surfaces, making them vulnerable to adversarial attacks. With these vulnerabilities largely unexplored, this paper systematically quantifies the robustness of VLA-based robotic systems. Recognizing the unique demands of robotic execution, our attack objectives target the inherent spatial and functional characteristics of robotic systems. In particular, we introduce an untargeted position-aware attack objective that leverages spatial foundations to destabilize robotic actions, and a targeted attack objective that manipulates the robotic trajectory. Additionally, we design an adversarial patch generation approach that places a small, colorful patch within the camera's view, effectively executing the attack in both digital and physical environments. Our evaluation reveals a marked degradation in task success rates, with up to a 100\% reduction across a suite of simulated robotic tasks, highlighting critical security gaps in current VLA architectures. By unveiling these vulnerabilities and proposing actionable evaluation metrics, this work advances both the understanding and enhancement of safety for VLA-based robotic systems, underscoring the necessity for developing robust defense strategies prior to physical-world deployments.