 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Likelihood Voting with Self-Knowledge Distillation for Weakly Supervised Object Detection
Apr 14, 2022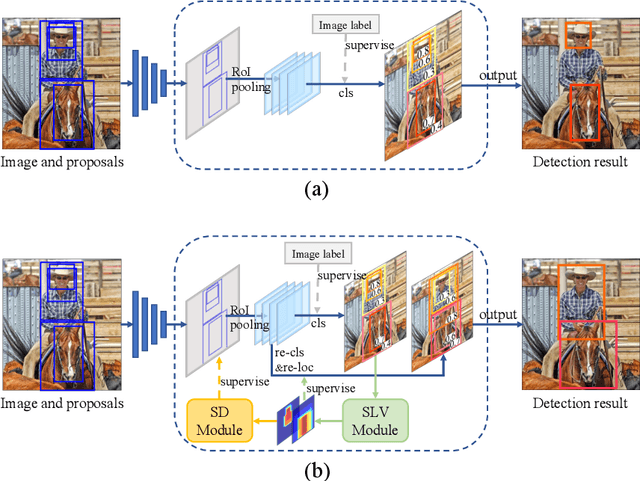
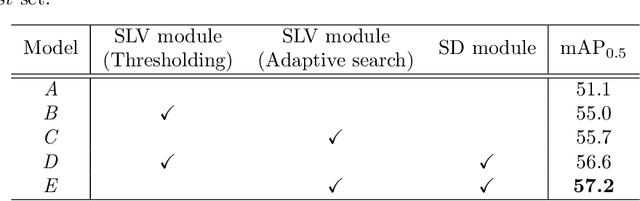
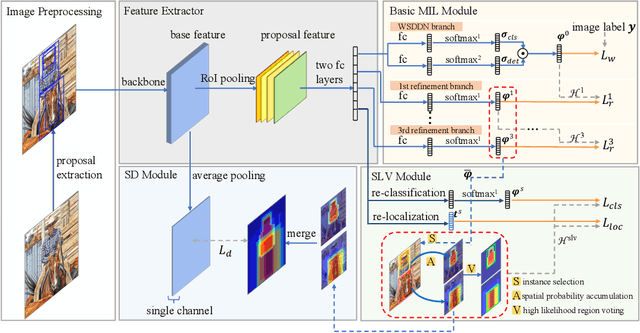

Weakly supervised object detection (WSOD), which is an effective way to train an object detection model using only image-level annotations, has attracted considerable attention from researchers. However, most of the existing methods, which are based on multiple instance learning (MIL), tend to localize instances to the discriminative parts of salient objects instead of the entire content of all objects. In this paper, we propose a WSOD framework called the Spatial Likelihood Voting with Self-knowledge Distillation Network (SLV-SD Net). In this framework, we introduce a spatial likelihood voting (SLV) module to converge region proposal localization without bounding box annotations. Specifically, in every iteration during training, all the region proposals in a given image act as voters voting for the likelihood of each category in the spatial dimensions. After dilating the alignment on the area with large likelihood values, the voting results are regularized as bounding boxes, which are then used for the final classification and localization. Based on SLV, we further propose a self-knowledge distillation (SD) module to refine the feature representations of the given image. The likelihood maps generated by the SLV module are used to supervise the feature learning of the backbone network, encouraging the network to attend to wider and more diverse areas of the image. Extensive experiments on the PASCAL VOC 2007/2012 and MS-COCO datasets demonstrate the excellent performance of SLV-SD Net. In addition, SLV-SD Net produces new state-of-the-art results on these benchmarks.
* arXiv admin note: text overlap with arXiv:2006.12884
Dynamic Supervisor for Cross-dataset Object Detection
Apr 01, 2022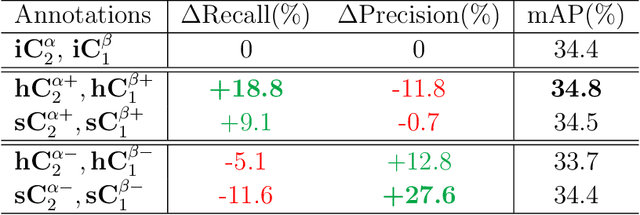
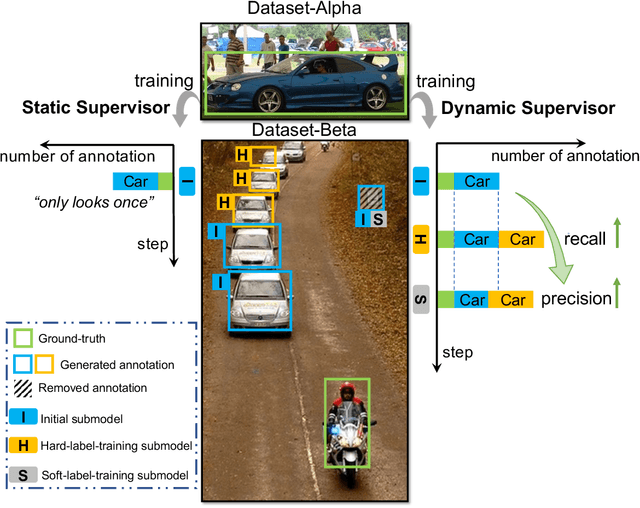

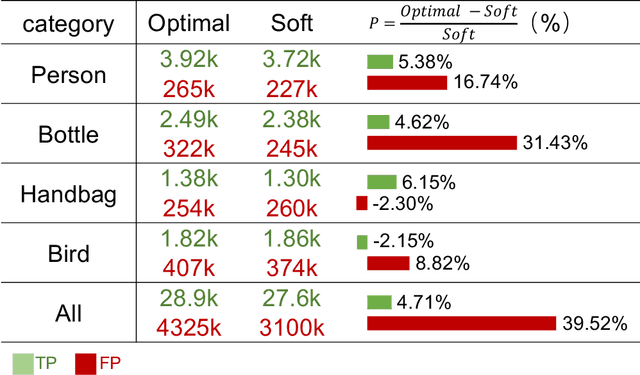
The application of cross-dataset training in object detection tasks is complicated because the inconsistency in the category range across datasets transforms fully supervised learning into semi-supervised learning. To address this problem, recent studies focus on the generation of high-quality missing annotations. In this study, we first point out that it is not enough to generate high-quality annotations using a single model, which only looks once for annotations. Through detailed experimental analyses, we further conclude that hard-label training is conducive to generating high-recall annotations, while soft-label training tends to obtain high-precision annotations. Inspired by the aspects mentioned above, we propose a dynamic supervisor framework that updates the annotations multiple times through multiple-updated submodels trained using hard and soft labels. In the final generated annotations, both recall and precision improve significantly through the integration of hard-label training with soft-label training. Extensive experiments conducted on various dataset combination settings support our analyses and demonstrate the superior performance of the proposed dynamic supervisor.
Attention-guided Temporal Coherent Video Object Matting
May 24, 2021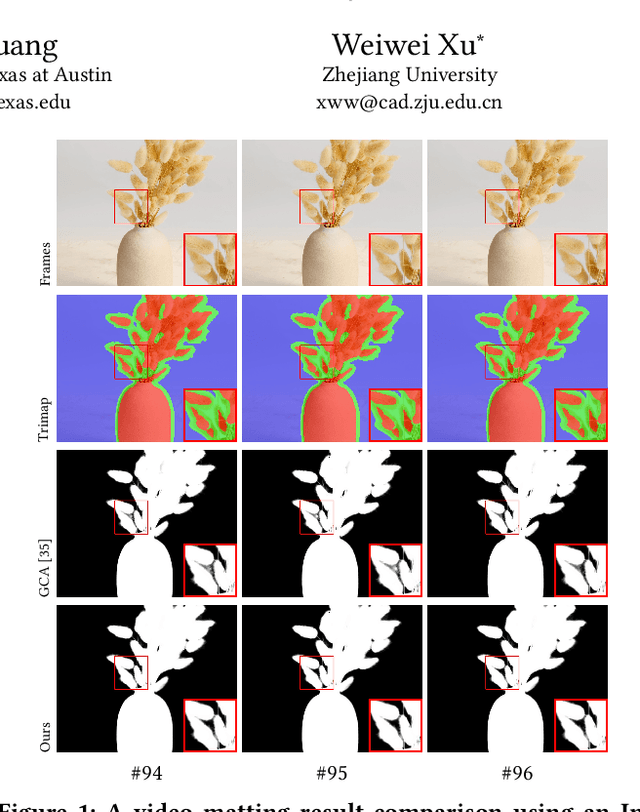
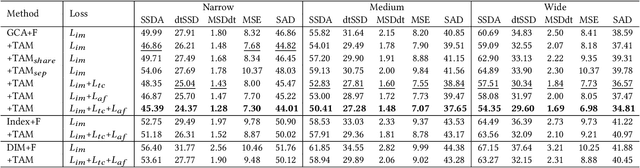
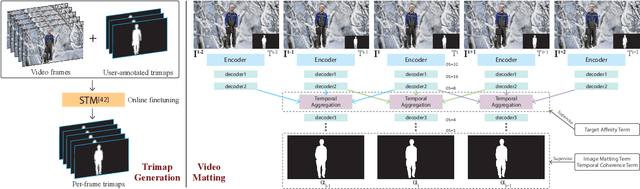
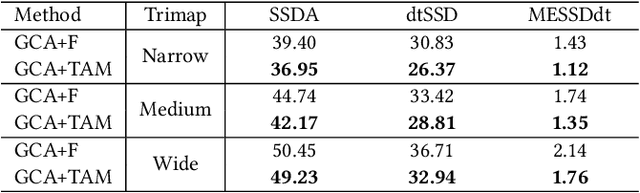
This paper proposes a novel deep learning-based video object matting method that can achieve temporally coherent matting results. Its key component is an attention-based temporal aggregation module that maximizes image matting networks' strength for video matting networks. This module computes temporal correlations for pixels adjacent to each other along the time axis in feature space to be robust against motion noises. We also design a novel loss term to train the attention weights, which drastically boosts the video matting performance. Besides, we show how to effectively solve the trimap generation problem by fine-tuning a state-of-the-art video object segmentation network with a sparse set of user-annotated keyframes. To facilitate video matting and trimap generation networks' training, we construct a large-scale video matting dataset with 80 training and 28 validation foreground video clips with ground-truth alpha mattes. Experimental results show that our method can generate high-quality alpha mattes for various videos featuring appearance change, occlusion, and fast motion. Our code and dataset can be found at https://github.com/yunkezhang/TCVOM
Learning to Generate Content-Aware Dynamic Detectors
Dec 08, 2020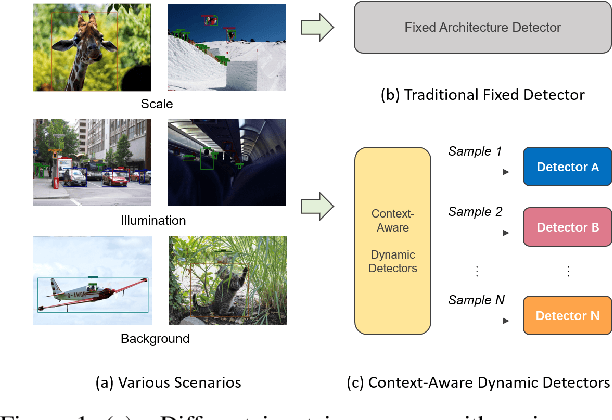
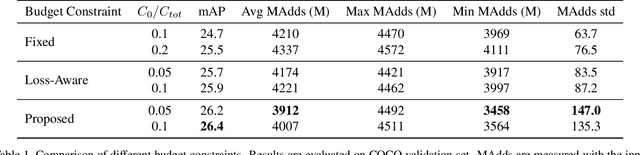
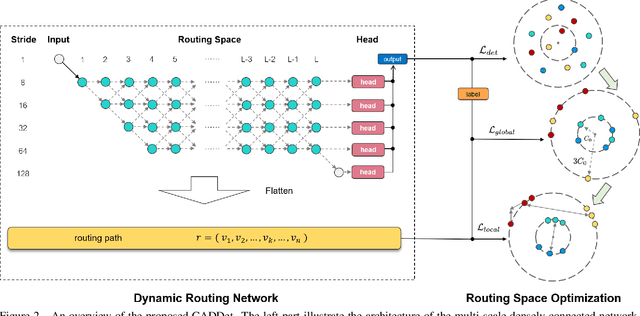
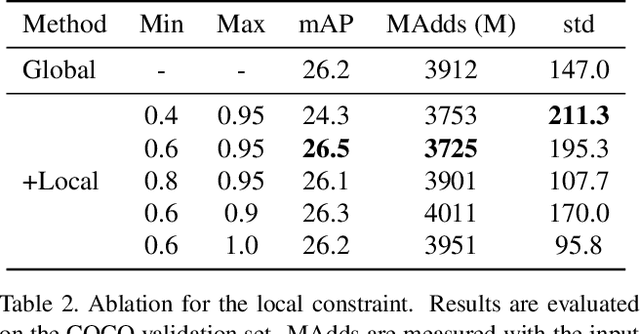
Model efficiency is crucial for object detection. Mostprevious works rely on either hand-crafted design or auto-search methods to obtain a static architecture, regardless ofthe difference of inputs. In this paper, we introduce a newperspective of designing efficient detectors, which is automatically generating sample-adaptive model architectureon the fly. The proposed method is named content-aware dynamic detectors (CADDet). It first applies a multi-scale densely connected network with dynamic routing as the supernet. Furthermore, we introduce a course-to-fine strat-egy tailored for object detection to guide the learning of dynamic routing, which contains two metrics: 1) dynamic global budget constraint assigns data-dependent expectedbudgets for individual samples; 2) local path similarity regularization aims to generate more diverse routing paths. With these, our method achieves higher computational efficiency while maintaining good performance. To the best of our knowledge, our CADDet is the first work to introduce dynamic routing mechanism in object detection. Experiments on MS-COCO dataset demonstrate that CADDet achieves 1.8 higher mAP with 10% fewer FLOPs compared with vanilla routing strategy. Compared with the models based upon similar building blocks, CADDet achieves a 42% FLOPs reduction with a competitive mAP.
CIMON: Towards High-quality Hash Codes
Nov 05, 2020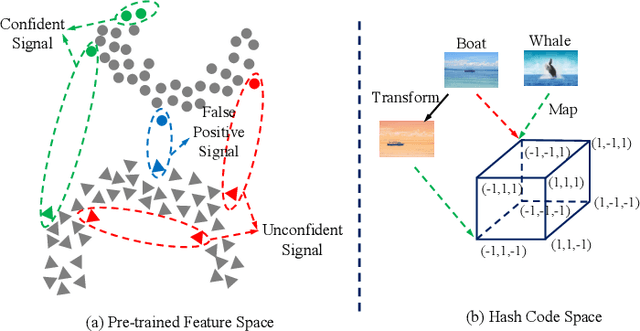
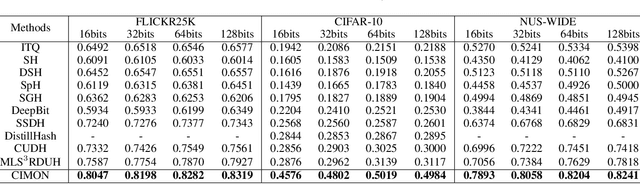
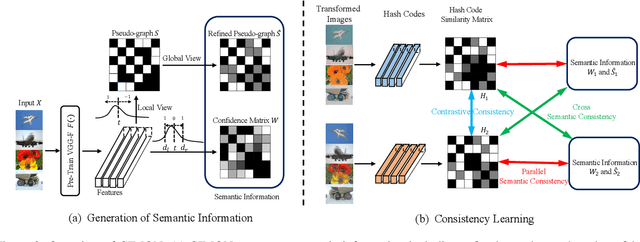
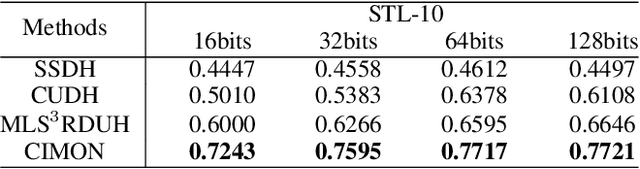
Recently, hashing is widely-used in approximate nearest neighbor search for its storage and computational efficiency. Due to the lack of labeled data in practice, many studies focus on unsupervised hashing. Most of the unsupervised hashing methods learn to map images into semantic similarity-preserving hash codes by constructing local semantic similarity structure from the pre-trained model as guiding information, i.e., treating each point pair similar if their distance is small in feature space. However, due to the inefficient representation ability of the pre-trained model, many false positives and negatives in local semantic similarity will be introduced and lead to error propagation during hash code learning. Moreover, most of hashing methods ignore the basic characteristics of hash codes such as collisions, which will cause instability of hash codes to disturbance. In this paper, we propose a new method named Comprehensive sImilarity Mining and cOnsistency learNing (CIMON). First, we use global constraint learning and similarity statistical distribution to obtain reliable and smooth guidance. Second, image augmentation and consistency learning will be introduced to explore both semantic and contrastive consistency to derive robust hash codes with fewer collisions. Extensive experiments on several benchmark datasets show that the proposed method consistently outperforms a wide range of state-of-the-art methods in both retrieval performance and robustness.
SLV: Spatial Likelihood Voting for Weakly Supervised Object Detection
Jun 23, 2020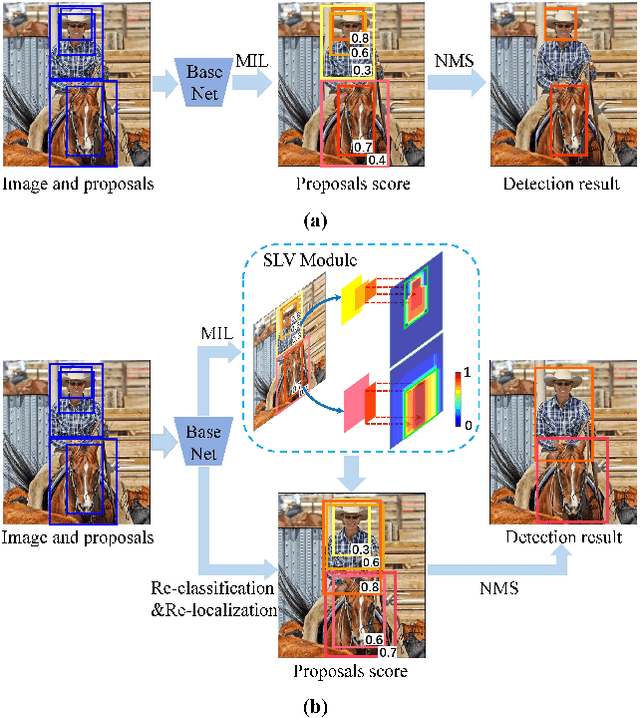
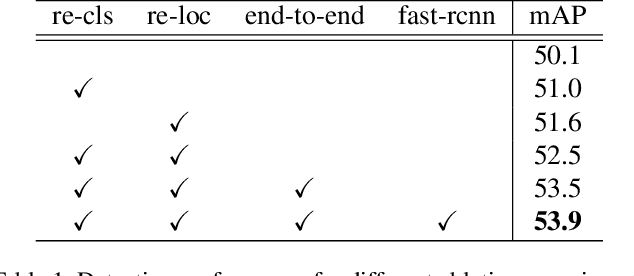
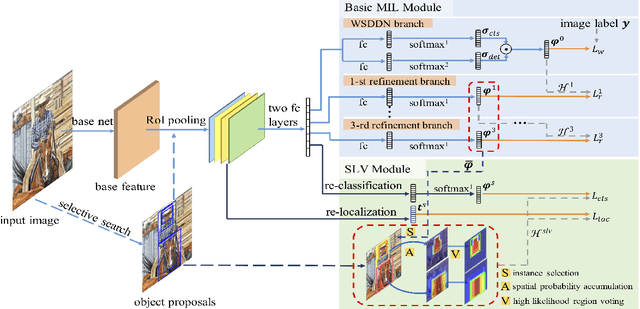
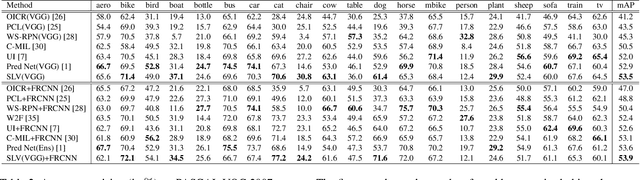
Based on the framework of multiple instance learning (MIL), tremendous works have promoted the advances of weakly supervised object detection (WSOD). However, most MIL-based methods tend to localize instances to their discriminative parts instead of the whole content. In this paper, we propose a spatial likelihood voting (SLV) module to converge the proposal localizing process without any bounding box annotations. Specifically, all region proposals in a given image play the role of voters every iteration during training, voting for the likelihood of each category in spatial dimensions. After dilating alignment on the area with large likelihood values, the voting results are regularized as bounding boxes, being used for the final classification and localization. Based on SLV, we further propose an end-to-end training framework for multi-task learning. The classification and localization tasks promote each other, which further improves the detection performance. Extensive experiments on the PASCAL VOC 2007 and 2012 datasets demonstrate the superior performance of SLV.
Boosting Semantic Human Matting with Coarse Annotations
Apr 10, 2020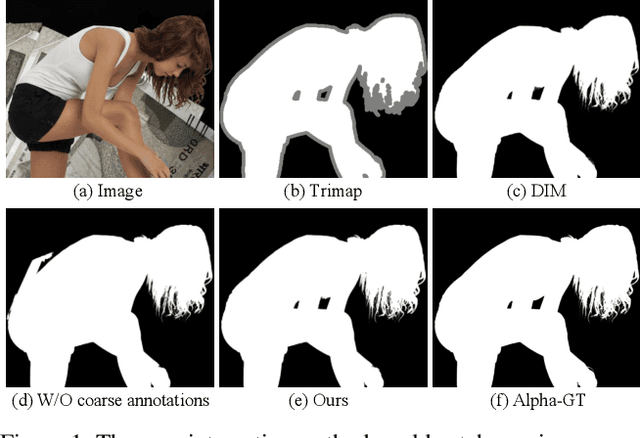
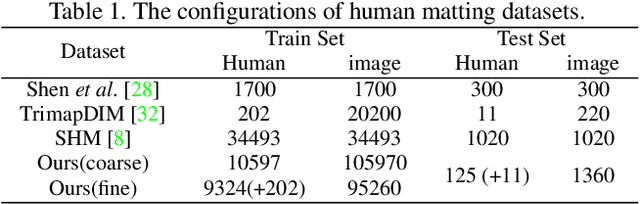
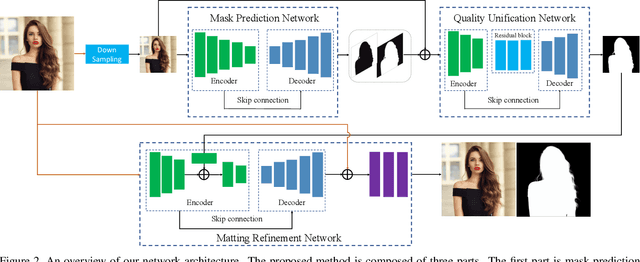
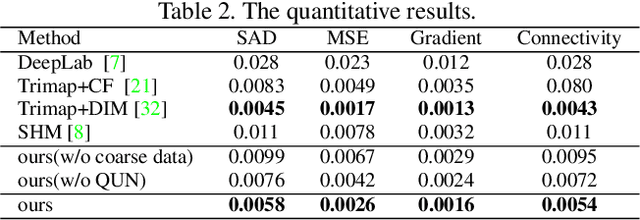
Semantic human matting aims to estimate the per-pixel opacity of the foreground human regions. It is quite challenging and usually requires user interactive trimaps and plenty of high quality annotated data. Annotating such kind of data is labor intensive and requires great skills beyond normal users, especially considering the very detailed hair part of humans. In contrast, coarse annotated human dataset is much easier to acquire and collect from the public dataset. In this paper, we propose to use coarse annotated data coupled with fine annotated data to boost end-to-end semantic human matting without trimaps as extra input. Specifically, we train a mask prediction network to estimate the coarse semantic mask using the hybrid data, and then propose a quality unification network to unify the quality of the previous coarse mask outputs. A matting refinement network takes in the unified mask and the input image to predict the final alpha matte. The collected coarse annotated dataset enriches our dataset significantly, allows generating high quality alpha matte for real images. Experimental results show that the proposed method performs comparably against state-of-the-art methods. Moreover, the proposed method can be used for refining coarse annotated public dataset, as well as semantic segmentation methods, which reduces the cost of annotating high quality human data to a great extent.