 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Tailed Distribution-Aware Router For Mixture-of-Experts in Large Vision-Language Model
Jul 02, 2025



The mixture-of-experts (MoE), which replaces dense models with sparse architectures, has gained attention in large vision-language models (LVLMs) for achieving comparable performance with fewer activated parameters. Existing MoE frameworks for LVLMs focus on token-to-expert routing (TER), encouraging different experts to specialize in processing distinct tokens. However, these frameworks often rely on the load balancing mechanism, overlooking the inherent distributional differences between vision and language. To this end, we propose a Long-Tailed Distribution-aware Router (LTDR) for vision-language TER, tackling two challenges: (1) Distribution-aware router for modality-specific routing. We observe that language TER follows a uniform distribution, whereas vision TER exhibits a long-tailed distribution. This discrepancy necessitates distinct routing strategies tailored to each modality. (2) Enhancing expert activation for vision tail tokens. Recognizing the importance of vision tail tokens, we introduce an oversampling-like strategy by increasing the number of activated experts for these tokens. Experiments on extensive benchmarks validate the effectiveness of our approach.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
R1-Reward: Training Multimodal Reward Model Through Stable Reinforcement Learning
May 05, 2025Multimodal Reward Models (MRMs) play a crucial role in enhancing the performance of Multimodal Large Language Models (MLLMs). While recent advancements have primarily focused on improving the model structure and training data of MRMs, there has been limited exploration into the effectiveness of long-term reasoning capabilities for reward modeling and how to activate these capabilities in MRMs. In this paper, we explore how Reinforcement Learning (RL) can be used to improve reward modeling. Specifically, we reformulate the reward modeling problem as a rule-based RL task. However, we observe that directly applying existing RL algorithms, such as Reinforce++, to reward modeling often leads to training instability or even collapse due to the inherent limitations of these algorithms. To address this issue, we propose the StableReinforce algorithm, which refines the training loss, advantage estimation strategy, and reward design of existing RL methods. These refinements result in more stable training dynamics and superior performance. To facilitate MRM training, we collect 200K preference data from diverse datasets. Our reward model, R1-Reward, trained using the StableReinforce algorithm on this dataset, significantly improves performance on multimodal reward modeling benchmarks. Compared to previous SOTA models, R1-Reward achieves a $8.4\%$ improvement on the VL Reward-Bench and a $14.3\%$ improvement on the Multimodal Reward Bench. Moreover, with more inference compute, R1-Reward's performance is further enhanced, highlighting the potential of RL algorithms in optimizing MRMs.
EVLM: An Efficient Vision-Language Model for Visual Understanding
Jul 19, 2024



In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features makes it challenging for large language models to perceive visual signals fully. This paper proposes an efficient multi-modal language model to minimize computational costs while enabling the model to perceive visual signals as comprehensively as possible. Our method primarily includes: (1) employing cross-attention to image-text interaction similar to Flamingo. (2) utilize hierarchical ViT features. (3) introduce the Mixture of Experts (MoE) mechanism to enhance model effectiveness. Our model achieves competitive scores on public multi-modal benchmarks and performs well in tasks such as image captioning and video captioning.
2nd Place and 2nd Place Solution to Kaggle Landmark Recognition andRetrieval Competition 2019
Jun 16, 2019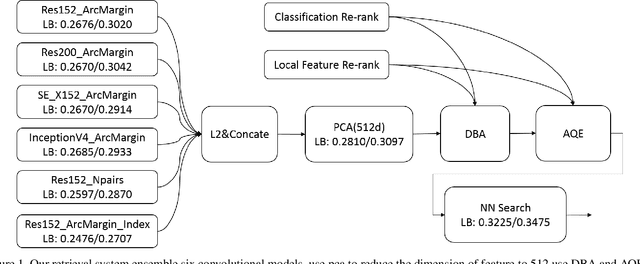
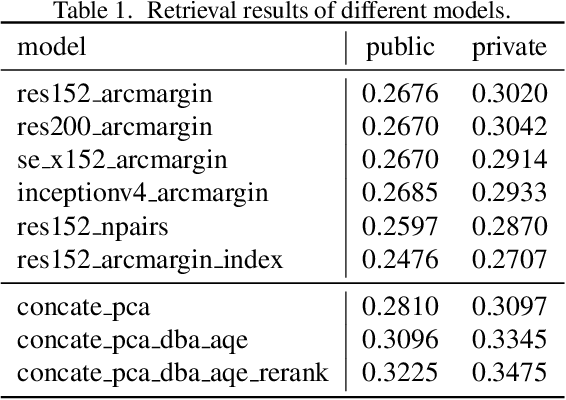


We present a retrieval based system for landmark retrieval and recognition challenge.There are five parts in retrieval competition system, including feature extraction and matching to get candidates queue; database augmentation and query extension searching; reranking from recognition results and local feature matching. In recognition challenge including: landmark and non-landmark recognition, multiple recognition results voting and reranking using combination of recognition and retrieval results. All of models trained and predicted by PaddlePaddle framework. Using our method, we achieved 2nd place in the Google Landmark Recognition 2019 and 2nd place in the Google Landmark Retrieval 2019 on kaggle. The source code is available at here.
Point Linking Network for Object Detection
Jun 13, 2017
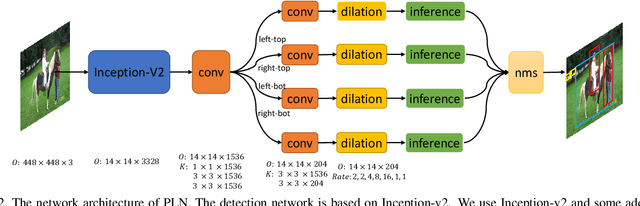
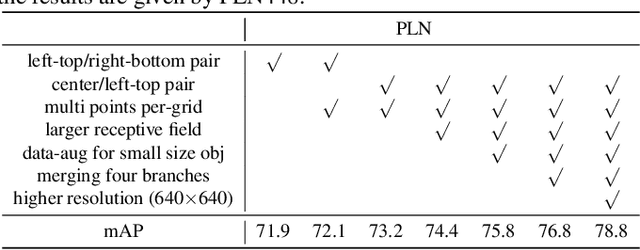

Object detection is a core problem in computer vision. With the development of deep ConvNets, the performance of object detectors has been dramatically improved. The deep ConvNets based object detectors mainly focus on regressing the coordinates of bounding box, e.g., Faster-R-CNN, YOLO and SSD. Different from these methods that considering bounding box as a whole, we propose a novel object bounding box representation using points and links and implemented using deep ConvNets, termed as Point Linking Network (PLN). Specifically, we regress the corner/center points of bounding-box and their links using a fully convolutional network; then we map the corner points and their links back to multiple bounding boxes; finally an object detection result is obtained by fusing the multiple bounding boxes. PLN is naturally robust to object occlusion and flexible to object scale variation and aspect ratio variation. In the experiments, PLN with the Inception-v2 model achieves state-of-the-art single-model and single-scale results on the PASCAL VOC 2007, the PASCAL VOC 2012 and the COCO detection benchmarks without bells and whistles. The source code will be released.