 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite Embedding Multilingual R2 Models
May 13, 2026We introduce the multilingual Granite Embedding R2 models, a family of encoder-based embedding models for enterprise-scale dense retrieval across 200+ languages. Extending our English-focused R2 release, these models add enhanced support for 52 languages and programming code, a 32,768-token context window (a 64x expansion over R1), and state-of-the-art overall performance across multilingual and cross-lingual text search, code retrieval, long-document search, and reasoning retrieval datasets. The release consists of two bi-encoder models based on the ModernBERT architecture with an expanded multilingual vocabulary: a 311M-parameter full-size, and a 97M-parameter compact model built via model pruning and vocabulary selection that achieves the highest retrieval score of any open multilingual embedding model under 100M parameters. The full-size also supports Matryoshka Representation Learning for flexible embedding dimensionality. Both models are trained on enterprise-appropriate data with governance oversight, and released under the Apache 2.0 license at https://huggingface.co/collections/ibm-granite, designed to support responsible use and enable unrestricted research and enterprise adoption.
DRBENCHER: Can Your Agent Identify the Entity, Retrieve Its Properties and Do the Math?
Apr 10, 2026Deep research agents increasingly interleave web browsing with multi-step computation, yet existing benchmarks evaluate these capabilities in isolation, creating a blind spot in assessing real-world performance. We introduce DRBENCHER, a synthetic benchmark generator for questions that require both browsing and computation. It enforces four criteria: verifiability (gold answers are computed by executing parameterized code over knowledge-graph values), complexity (multi-hop entity identification, property retrieval, and domain-specific computation), difficulty (a two-stage verification cascade filters out questions solvable by the generating model), and diversity (a greedy max-min embedding filter maximizes coverage). These criteria are realized via a unified answer-first pipeline spanning five domains: biochemistry, financial, geophysical, security, and history. Human evaluation shows 76% validity (84% excluding stale data), with 35% of errors due to outdated knowledge-graph entries, highlighting an inherent limitation of systems that reason over evolving data. Automatic evaluation shows that the strongest frontier model achieves only 20% answer accuracy. Compared to manually constructed benchmarks (BrowseComp+, MATH-500, GPQA), DRBENCHER achieves the highest semantic diversity.
LMK > CLS: Landmark Pooling for Dense Embeddings
Jan 29, 2026Representation learning is central to many downstream tasks such as search, clustering, classification, and reranking. State-of-the-art sequence encoders typically collapse a variable-length token sequence to a single vector using a pooling operator, most commonly a special [CLS] token or mean pooling over token embeddings. In this paper, we identify systematic weaknesses of these pooling strategies: [CLS] tends to concentrate information toward the initial positions of the sequence and can under-represent distributed evidence, while mean pooling can dilute salient local signals, sometimes leading to worse short-context performance. To address these issues, we introduce Landmark (LMK) pooling, which partitions a sequence into chunks, inserts landmark tokens between chunks, and forms the final representation by mean-pooling the landmark token embeddings. This simple mechanism improves long-context extrapolation without sacrificing local salient features, at the cost of introducing a small number of special tokens. We empirically demonstrate that LMK pooling matches existing methods on short-context retrieval tasks and yields substantial improvements on long-context tasks, making it a practical and scalable alternative to existing pooling methods.
DialectalArabicMMLU: Benchmarking Dialectal Capabilities in Arabic and Multilingual Language Models
Oct 31, 2025We present DialectalArabicMMLU, a new benchmark for evaluating the performance of large language models (LLMs) across Arabic dialects. While recently developed Arabic and multilingual benchmarks have advanced LLM evaluation for Modern Standard Arabic (MSA), dialectal varieties remain underrepresented despite their prevalence in everyday communication. DialectalArabicMMLU extends the MMLU-Redux framework through manual translation and adaptation of 3K multiple-choice question-answer pairs into five major dialects (Syrian, Egyptian, Emirati, Saudi, and Moroccan), yielding a total of 15K QA pairs across 32 academic and professional domains (22K QA pairs when also including English and MSA). The benchmark enables systematic assessment of LLM reasoning and comprehension beyond MSA, supporting both task-based and linguistic analysis. We evaluate 19 open-weight Arabic and multilingual LLMs (1B-13B parameters) and report substantial performance variation across dialects, revealing persistent gaps in dialectal generalization. DialectalArabicMMLU provides the first unified, human-curated resource for measuring dialectal understanding in Arabic, thus promoting more inclusive evaluation and future model development.
Contrastive Retrieval Heads Improve Attention-Based Re-Ranking
Oct 02, 2025The strong zero-shot and long-context capabilities of recent Large Language Models (LLMs) have paved the way for highly effective re-ranking systems. Attention-based re-rankers leverage attention weights from transformer heads to produce relevance scores, but not all heads are created equally: many contribute noise and redundancy, thus limiting performance. To address this, we introduce CoRe heads, a small set of retrieval heads identified via a contrastive scoring metric that explicitly rewards high attention heads that correlate with relevant documents, while downplaying nodes with higher attention that correlate with irrelevant documents. This relative ranking criterion isolates the most discriminative heads for re-ranking and yields a state-of-the-art list-wise re-ranker. Extensive experiments with three LLMs show that aggregated signals from CoRe heads, constituting less than 1% of all heads, substantially improve re-ranking accuracy over strong baselines. We further find that CoRe heads are concentrated in middle layers, and pruning the computation of final 50% of model layers preserves accuracy while significantly reducing inference time and memory usage.
Optimal Policy Minimum Bayesian Risk
May 22, 2025Inference scaling can help LLMs solve complex reasoning problems through extended runtime computation. On top of targeted supervision for long chain-of-thought (long-CoT) generation, purely inference-time techniques such as best-of-N (BoN) sampling, majority voting, or more generally, minimum Bayes risk decoding (MBRD), can further improve LLM accuracy by generating multiple candidate solutions and aggregating over them. These methods typically leverage additional signals in the form of reward models and risk/similarity functions that compare generated samples, e.g., exact match in some normalized space or standard similarity metrics such as Rouge. Here we present a novel method for incorporating reward and risk/similarity signals into MBRD. Based on the concept of optimal policy in KL-controlled reinforcement learning, our framework provides a simple and well-defined mechanism for leveraging such signals, offering several advantages over traditional inference-time methods: higher robustness, improved accuracy, and well-understood asymptotic behavior. In addition, it allows for the development of a sample-efficient variant of MBRD that can adjust the number of samples to generate according to the difficulty of the problem, without relying on majority vote counts. We empirically demonstrate the advantages of our approach on math (MATH-$500$) and coding (HumanEval) tasks using recent open-source models. We also present a comprehensive analysis of its accuracy-compute trade-offs.
Granite Embedding Models
Feb 27, 2025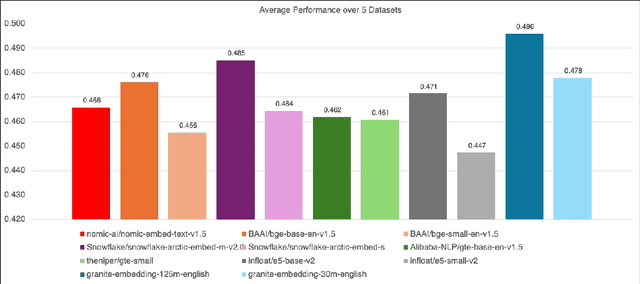
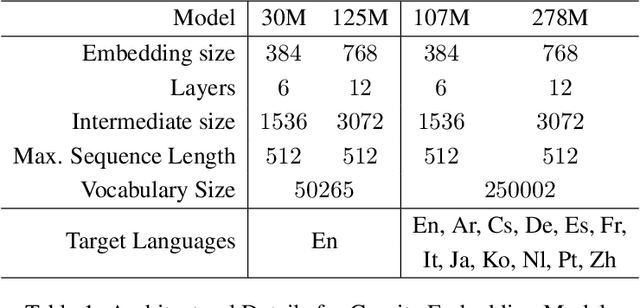
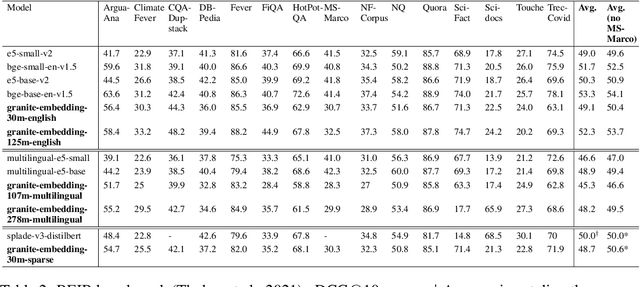

We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.
Multi-Document Grounded Multi-Turn Synthetic Dialog Generation
Sep 17, 2024



We introduce a technique for multi-document grounded multi-turn synthetic dialog generation that incorporates three main ideas. First, we control the overall dialog flow using taxonomy-driven user queries that are generated with Chain-of-Thought (CoT) prompting. Second, we support the generation of multi-document grounded dialogs by mimicking real-world use of retrievers to update the grounding documents after every user-turn in the dialog. Third, we apply LLM-as-a-Judge to filter out queries with incorrect answers. Human evaluation of the synthetic dialog data suggests that the data is diverse, coherent, and includes mostly correct answers. Both human and automatic evaluations of answerable queries indicate that models fine-tuned on synthetic dialogs consistently out-perform those fine-tuned on existing human generated training data across four publicly available multi-turn document grounded benchmark test sets.
Prompts as Auto-Optimized Training Hyperparameters: Training Best-in-Class IR Models from Scratch with 10 Gold Labels
Jun 17, 2024



We develop a method for training small-scale (under 100M parameter) neural information retrieval models with as few as 10 gold relevance labels. The method depends on generating synthetic queries for documents using a language model (LM), and the key step is that we automatically optimize the LM prompt that is used to generate these queries based on training quality. In experiments with the BIRCO benchmark, we find that models trained with our method outperform RankZephyr and are competitive with RankLLama, both of which are 7B parameter models trained on over 100K labels. These findings point to the power of automatic prompt optimization for synthetic dataset generation.
Can a Multichoice Dataset be Repurposed for Extractive Question Answering?
Apr 26, 2024



The rapid evolution of Natural Language Processing (NLP) has favored major languages such as English, leaving a significant gap for many others due to limited resources. This is especially evident in the context of data annotation, a task whose importance cannot be underestimated, but which is time-consuming and costly. Thus, any dataset for resource-poor languages is precious, in particular when it is task-specific. Here, we explore the feasibility of repurposing existing datasets for a new NLP task: we repurposed the Belebele dataset (Bandarkar et al., 2023), which was designed for multiple-choice question answering (MCQA), to enable extractive QA (EQA) in the style of machine reading comprehension. We present annotation guidelines and a parallel EQA dataset for English and Modern Standard Arabic (MSA). We also present QA evaluation results for several monolingual and cross-lingual QA pairs including English, MSA, and five Arabic dialects. Our aim is to enable others to adapt our approach for the 120+ other language variants in Belebele, many of which are deemed under-resourced. We also conduct a thorough analysis and share our insights from the process, which we hope will contribute to a deeper understanding of the challenges and the opportunities associated with task reformulation in NLP research.