 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalk the Talk: Bridging the Reasoning-Action Gap for Thinking with Images via Multimodal Agentic Policy Optimization
Apr 08, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have incentivized models to ``think with images'' by actively invoking visual tools during multi-turn reasoning. The common Reinforcement Learning (RL) practice of relying on outcome-based rewards ignores the fact that textual plausibility often masks executive failure, meaning that models may exhibit intuitive textual reasoning while executing imprecise or irrelevant visual actions within their agentic reasoning trajectories. This reasoning-action discrepancy introduces noise that accumulates throughout the multi-turn reasoning process, severely degrading the model's multimodal reasoning capabilities and potentially leading to training collapse. In this paper, we introduce Multimodal Agentic Policy Optimization (MAPO), bridging the gap between textual reasoning and visual actions generated by models within their Multimodal Chain-of-Thought (MCoT). Specifically, MAPO mandates the model to generate explicit textual descriptions for the visual content obtained via tool usage. We then employ a novel advantage estimation that couples the semantic alignment between these descriptions and the actual observations with the task reward. Theoretical findings are provided to justify the rationale behind MAPO, which inherently reduces the variance of gradients, and extensive experiments demonstrate that our method achieves superior performance across multiple visual reasoning benchmarks.
Marco DeepResearch: Unlocking Efficient Deep Research Agents via Verification-Centric Design
Mar 30, 2026Deep research agents autonomously conduct open-ended investigations, integrating complex information retrieval with multi-step reasoning across diverse sources to solve real-world problems. To sustain this capability on long-horizon tasks, reliable verification is critical during both training and inference. A major bottleneck in existing paradigms stems from the lack of explicit verification mechanisms in QA data synthesis, trajectory construction, and test-time scaling. Errors introduced at each stage propagate downstream and degrade the overall agent performance. To address this, we present Marco DeepResearch, a deep research agent optimized with a verification-centric framework design at three levels: \textbf{(1)~QA Data Synthesis:} We introduce verification mechanisms to graph-based and agent-based QA synthesis to control question difficulty while ensuring answers are unique and correct; \textbf{(2)~Trajectory Construction:} We design a verification-driven trajectory synthesis method that injects explicit verification patterns into training trajectories; and \textbf{(3)~Test-time scaling:} We use Marco DeepResearch itself as a verifier at inference time and effectively improve performance on challenging questions. Extensive experimental results demonstrate that our proposed Marco DeepResearch agent significantly outperforms 8B-scale deep research agents on most challenging benchmarks, such as BrowseComp and BrowseComp-ZH. Crucially, under a maximum budget of 600 tool calls, Marco DeepResearch even surpasses or approaches several 30B-scale agents, like Tongyi DeepResearch-30B.
M$^2$: Dual-Memory Augmentation for Long-Horizon Web Agents via Trajectory Summarization and Insight Retrieval
Feb 28, 2026Multimodal Large Language Models (MLLMs) based agents have demonstrated remarkable potential in autonomous web navigation. However, handling long-horizon tasks remains a critical bottleneck. Prevailing strategies often rely heavily on extensive data collection and model training, yet still struggle with high computational costs and insufficient reasoning capabilities when facing complex, long-horizon scenarios. To address this, we propose M$^2$, a training-free, memory-augmented framework designed to optimize context efficiency and decision-making robustness. Our approach incorporates a dual-tier memory mechanism that synergizes Dynamic Trajectory Summarization (Internal Memory) to compress verbose interaction history into concise state updates, and Insight Retrieval Augmentation (External Memory) to guide the agent with actionable guidelines retrieved from an offline insight bank. Extensive evaluations across WebVoyager and OnlineMind2Web demonstrate that M$^2$ consistently surpasses baselines, yielding up to a 19.6% success rate increase and 58.7% token reduction for Qwen3-VL-32B, while proprietary models like Claude achieve accuracy gains up to 12.5% alongside significantly lower computational overhead.
Building Autonomous GUI Navigation via Agentic-Q Estimation and Step-Wise Policy Optimization
Feb 14, 2026Recent advances in Multimodal Large Language Models (MLLMs) have substantially driven the progress of autonomous agents for Graphical User Interface (GUI). Nevertheless, in real-world applications, GUI agents are often faced with non-stationary environments, leading to high computational costs for data curation and policy optimization. In this report, we introduce a novel MLLM-centered framework for GUI agents, which consists of two components: agentic-Q estimation and step-wise policy optimization. The former one aims to optimize a Q-model that can generate step-wise values to evaluate the contribution of a given action to task completion. The latter one takes step-wise samples from the state-action trajectory as inputs, and optimizes the policy via reinforcement learning with our agentic-Q model. It should be noticed that (i) all state-action trajectories are produced by the policy itself, so that the data collection costs are manageable; (ii) the policy update is decoupled from the environment, ensuring stable and efficient optimization. Empirical evaluations show that our framework endows Ovis2.5-9B with powerful GUI interaction capabilities, achieving remarkable performances on GUI navigation and grounding benchmarks and even surpassing contenders with larger scales.
Table-as-Search: Formulate Long-Horizon Agentic Information Seeking as Table Completion
Feb 06, 2026Current Information Seeking (InfoSeeking) agents struggle to maintain focus and coherence during long-horizon exploration, as tracking search states, including planning procedure and massive search results, within one plain-text context is inherently fragile. To address this, we introduce \textbf{Table-as-Search (TaS)}, a structured planning framework that reformulates the InfoSeeking task as a Table Completion task. TaS maps each query into a structured table schema maintained in an external database, where rows represent search candidates and columns denote constraints or required information. This table precisely manages the search states: filled cells strictly record the history and search results, while empty cells serve as an explicit search plan. Crucially, TaS unifies three distinct InfoSeeking tasks: Deep Search, Wide Search, and the challenging DeepWide Search. Extensive experiments demonstrate that TaS significantly outperforms numerous state-of-the-art baselines across three kinds of benchmarks, including multi-agent framework and commercial systems. Furthermore, our analysis validates the TaS's superior robustness in long-horizon InfoSeeking, alongside its efficiency, scalability and flexibility. Code and datasets are publicly released at https://github.com/AIDC-AI/Marco-Search-Agent.
Vectra: A New Metric, Dataset, and Model for Visual Quality Assessment in E-Commerce In-Image Machine Translation
Jan 31, 2026In-Image Machine Translation (IIMT) powers cross-border e-commerce product listings; existing research focuses on machine translation evaluation, while visual rendering quality is critical for user engagement. When facing context-dense product imagery and multimodal defects, current reference-based methods (e.g., SSIM, FID) lack explainability, while model-as-judge approaches lack domain-grounded, fine-grained reward signals. To bridge this gap, we introduce Vectra, to the best of our knowledge, the first reference-free, MLLM-driven visual quality assessment framework for e-commerce IIMT. Vectra comprises three components: (1) Vectra Score, a multidimensional quality metric system that decomposes visual quality into 14 interpretable dimensions, with spatially-aware Defect Area Ratio (DAR) quantification to reduce annotation ambiguity; (2) Vectra Dataset, constructed from 1.1M real-world product images via diversity-aware sampling, comprising a 2K benchmark for system evaluation, 30K reasoning-based annotations for instruction tuning, and 3.5K expert-labeled preferences for alignment and evaluation; and (3) Vectra Model, a 4B-parameter MLLM that generates both quantitative scores and diagnostic reasoning. Experiments demonstrate that Vectra achieves state-of-the-art correlation with human rankings, and our model outperforms leading MLLMs, including GPT-5 and Gemini-3, in scoring performance. The dataset and model will be released upon acceptance.
Text is All You Need for Vision-Language Model Jailbreaking
Jan 31, 2026Large Vision-Language Models (LVLMs) are increasingly equipped with robust safety safeguards to prevent responses to harmful or disallowed prompts. However, these defenses often focus on analyzing explicit textual inputs or relevant visual scenes. In this work, we introduce Text-DJ, a novel jailbreak attack that bypasses these safeguards by exploiting the model's Optical Character Recognition (OCR) capability. Our methodology consists of three stages. First, we decompose a single harmful query into multiple and semantically related but more benign sub-queries. Second, we pick a set of distraction queries that are maximally irrelevant to the harmful query. Third, we present all decomposed sub-queries and distraction queries to the LVLM simultaneously as a grid of images, with the position of the sub-queries being middle within the grid. We demonstrate that this method successfully circumvents the safety alignment of state-of-the-art LVLMs. We argue this attack succeeds by (1) converting text-based prompts into images, bypassing standard text-based filters, and (2) inducing distractions, where the model's safety protocols fail to link the scattered sub-queries within a high number of irrelevant queries. Overall, our findings expose a critical vulnerability in LVLMs' OCR capabilities that are not robust to dispersed, multi-image adversarial inputs, highlighting the need for defenses for fragmented multimodal inputs.
Triplets Better Than Pairs: Towards Stable and Effective Self-Play Fine-Tuning for LLMs
Jan 13, 2026Recently, self-play fine-tuning (SPIN) has been proposed to adapt large language models to downstream applications with scarce expert-annotated data, by iteratively generating synthetic responses from the model itself. However, SPIN is designed to optimize the current reward advantages of annotated responses over synthetic responses at hand, which may gradually vanish during iterations, leading to unstable optimization. Moreover, the utilization of reference policy induces a misalignment issue between the reward formulation for training and the metric for generation. To address these limitations, we propose a novel Triplet-based Self-Play fIne-tuNing (T-SPIN) method that integrates two key designs. First, beyond current advantages, T-SPIN additionally incorporates historical advantages between iteratively generated responses and proto-synthetic responses produced by the initial policy. Even if the current advantages diminish, historical advantages remain effective, stabilizing the overall optimization. Second, T-SPIN introduces the entropy constraint into the self-play framework, which is theoretically justified to support reference-free fine-tuning, eliminating the training-generation discrepancy. Empirical results on various tasks demonstrate not only the superior performance of T-SPIN over SPIN, but also its stable evolution during iterations. Remarkably, compared to supervised fine-tuning, T-SPIN achieves comparable or even better performance with only 25% samples, highlighting its effectiveness when faced with scarce annotated data.
Deep But Reliable: Advancing Multi-turn Reasoning for Thinking with Images
Dec 19, 2025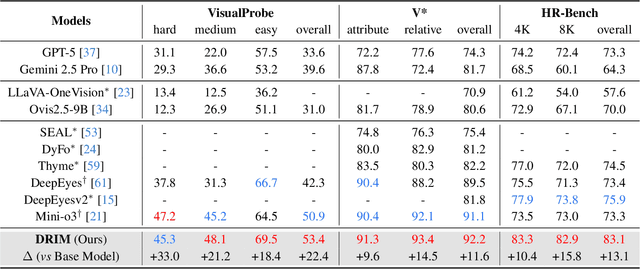
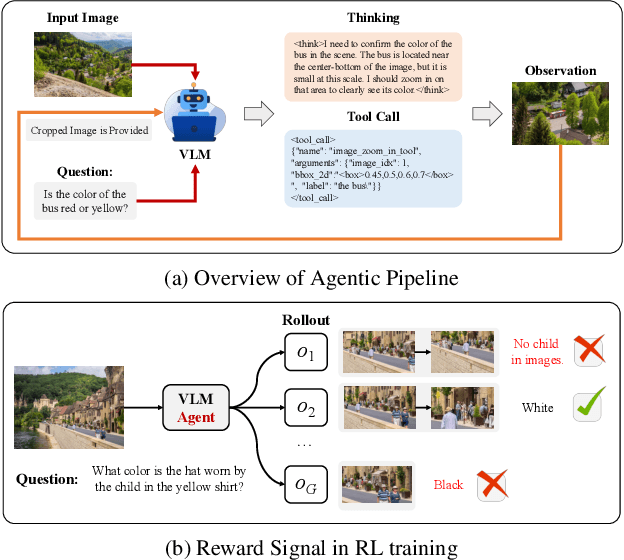
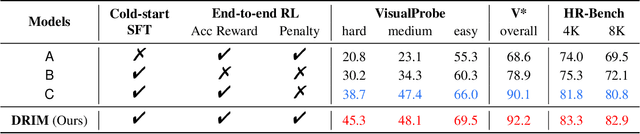
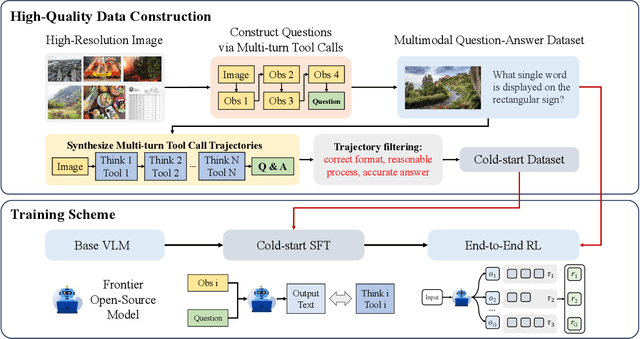
Recent advances in large Vision-Language Models (VLMs) have exhibited strong reasoning capabilities on complex visual tasks by thinking with images in their Chain-of-Thought (CoT), which is achieved by actively invoking tools to analyze visual inputs rather than merely perceiving them. However, existing models often struggle to reflect on and correct themselves when attempting incorrect reasoning trajectories. To address this limitation, we propose DRIM, a model that enables deep but reliable multi-turn reasoning when thinking with images in its multimodal CoT. Our pipeline comprises three stages: data construction, cold-start SFT and RL. Based on a high-resolution image dataset, we construct high-difficulty and verifiable visual question-answer pairs, where solving each task requires multi-turn tool calls to reach the correct answer. In the SFT stage, we collect tool trajectories as cold-start data, guiding a multi-turn reasoning pattern. In the RL stage, we introduce redundancy-penalized policy optimization, which incentivizes the model to develop a self-reflective reasoning pattern. The basic idea is to impose judgment on reasoning trajectories and penalize those that produce incorrect answers without sufficient multi-scale exploration. Extensive experiments demonstrate that DRIM achieves superior performance on visual understanding benchmarks.
Omni-View: Unlocking How Generation Facilitates Understanding in Unified 3D Model based on Multiview images
Nov 10, 2025This paper presents Omni-View, which extends the unified multimodal understanding and generation to 3D scenes based on multiview images, exploring the principle that "generation facilitates understanding". Consisting of understanding model, texture module, and geometry module, Omni-View jointly models scene understanding, novel view synthesis, and geometry estimation, enabling synergistic interaction between 3D scene understanding and generation tasks. By design, it leverages the spatiotemporal modeling capabilities of its texture module responsible for appearance synthesis, alongside the explicit geometric constraints provided by its dedicated geometry module, thereby enriching the model's holistic understanding of 3D scenes. Trained with a two-stage strategy, Omni-View achieves a state-of-the-art score of 55.4 on the VSI-Bench benchmark, outperforming existing specialized 3D understanding models, while simultaneously delivering strong performance in both novel view synthesis and 3D scene generation.