 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Reasoning and Action: Hybrid LLM-RL Framework for Efficient Cross-Domain Task-Oriented Dialogue
Apr 25, 2026Cross-domain task-oriented dialogue requires reasoning over implicit and explicit feasibility constraints while planning long-horizon, multi-turn actions. Large language models (LLMs) can infer such constraints but are unreliable over long horizons, while Reinforcement learning (RL) optimizes long-horizon behavior yet cannot recover constraints from raw dialogue. Naively coupling LLMs with RL is therefore brittle: unverified or unstructured LLM outputs can corrupt state representations and misguide policy learning. Motivated by this, we propose Verified LLM-Knowledge empowered RL (VLK-RL), a hybrid framework that makes LLM-derived constraint reasoning usable for RL. VLK-RL first elicits candidate constraints with an LLM and then verifies them via a dual-role cross-examination procedure to suppress hallucinations and cross-turn inconsistencies. The verified constraints are mapped into ontology-aligned slot-value representations, yielding a structured, constraint-aware state for RL policy optimization. Experiments across multiple benchmarks demonstrate that VLK-RL significantly improves generalization and robustness, outperforming strong single-model baselines on long-horizon tasks.
JADE: Expert-Grounded Dynamic Evaluation for Open-Ended Professional Tasks
Feb 06, 2026Evaluating agentic AI on open-ended professional tasks faces a fundamental dilemma between rigor and flexibility. Static rubrics provide rigorous, reproducible assessment but fail to accommodate diverse valid response strategies, while LLM-as-a-judge approaches adapt to individual responses yet suffer from instability and bias. Human experts address this dilemma by combining domain-grounded principles with dynamic, claim-level assessment. Inspired by this process, we propose JADE, a two-layer evaluation framework. Layer 1 encodes expert knowledge as a predefined set of evaluation skills, providing stable evaluation criteria. Layer 2 performs report-specific, claim-level evaluation to flexibly assess diverse reasoning strategies, with evidence-dependency gating to invalidate conclusions built on refuted claims. Experiments on BizBench show that JADE improves evaluation stability and reveals critical agent failure modes missed by holistic LLM-based evaluators. We further demonstrate strong alignment with expert-authored rubrics and effective transfer to a medical-domain benchmark, validating JADE across professional domains. Our code is publicly available at https://github.com/smiling-world/JADE.
Align$^2$LLaVA: Cascaded Human and Large Language Model Preference Alignment for Multi-modal Instruction Curation
Sep 27, 2024



Recent advances in Multi-modal Large Language Models (MLLMs), such as LLaVA-series models, are driven by massive machine-generated instruction-following data tuning. Such automatic instruction collection pipelines, however, inadvertently introduce significant variability in data quality. This paper introduces a novel instruction curation algorithm, derived from two unique perspectives, human and LLM preference alignment, to compress this vast corpus of machine-generated multimodal instructions to a compact and high-quality form: (i) For human preference alignment, we have collected a machine-generated multimodal instruction dataset and established a comprehensive set of both subjective and objective criteria to guide the data quality assessment critically from human experts. By doing so, a reward model was trained on the annotated dataset to internalize the nuanced human understanding of instruction alignment. (ii) For LLM preference alignment, given the instruction selected by the reward model, we propose leveraging the inner LLM used in MLLM to align the writing style of visual instructions with that of the inner LLM itself, resulting in LLM-aligned instruction improvement. Extensive experiments demonstrate that we can maintain or even improve model performance by compressing synthetic multimodal instructions by up to 90%. Impressively, by aggressively reducing the total training sample size from 158k to 14k (9$\times$ smaller), our model consistently outperforms its full-size dataset counterpart across various MLLM benchmarks. Our project is available at https://github.com/DCDmllm/Align2LLaVA.
Cause-Aware Empathetic Response Generation via Chain-of-Thought Fine-Tuning
Aug 21, 2024



Empathetic response generation endows agents with the capability to comprehend dialogue contexts and react to expressed emotions. Previous works predominantly focus on leveraging the speaker's emotional labels, but ignore the importance of emotion cause reasoning in empathetic response generation, which hinders the model's capacity for further affective understanding and cognitive inference. In this paper, we propose a cause-aware empathetic generation approach by integrating emotions and causes through a well-designed Chain-of-Thought (CoT) prompt on Large Language Models (LLMs). Our approach can greatly promote LLMs' performance of empathy by instruction tuning and enhancing the role awareness of an empathetic listener in the prompt. Additionally, we propose to incorporate cause-oriented external knowledge from COMET into the prompt, which improves the diversity of generation and alleviates conflicts between internal and external knowledge at the same time. Experimental results on the benchmark dataset demonstrate that our approach on LLaMA-7b achieves state-of-the-art performance in both automatic and human evaluations.
Multilingual Knowledge Graph Completion from Pretrained Language Models with Knowledge Constraints
Jun 26, 2024



Multilingual Knowledge Graph Completion (mKGC) aim at solving queries like (h, r, ?) in different languages by reasoning a tail entity t thus improving multilingual knowledge graphs. Previous studies leverage multilingual pretrained language models (PLMs) and the generative paradigm to achieve mKGC. Although multilingual pretrained language models contain extensive knowledge of different languages, its pretraining tasks cannot be directly aligned with the mKGC tasks. Moreover, the majority of KGs and PLMs currently available exhibit a pronounced English-centric bias. This makes it difficult for mKGC to achieve good results, particularly in the context of low-resource languages. To overcome previous problems, this paper introduces global and local knowledge constraints for mKGC. The former is used to constrain the reasoning of answer entities, while the latter is used to enhance the representation of query contexts. The proposed method makes the pretrained model better adapt to the mKGC task. Experimental results on public datasets demonstrate that our method outperforms the previous SOTA on Hits@1 and Hits@10 by an average of 12.32% and 16.03%, which indicates that our proposed method has significant enhancement on mKGC.
Temporal Knowledge Graph Completion with Time-sensitive Relations in Hypercomplex Space
Mar 02, 2024



Temporal knowledge graph completion (TKGC) aims to fill in missing facts within a given temporal knowledge graph at a specific time. Existing methods, operating in real or complex spaces, have demonstrated promising performance in this task. This paper advances beyond conventional approaches by introducing more expressive quaternion representations for TKGC within hypercomplex space. Unlike existing quaternion-based methods, our study focuses on capturing time-sensitive relations rather than time-aware entities. Specifically, we model time-sensitive relations through time-aware rotation and periodic time translation, effectively capturing complex temporal variability. Furthermore, we theoretically demonstrate our method's capability to model symmetric, asymmetric, inverse, compositional, and evolutionary relation patterns. Comprehensive experiments on public datasets validate that our proposed approach achieves state-of-the-art performance in the field of TKGC.
A Survey on Temporal Knowledge Graph: Representation Learning and Applications
Mar 02, 2024



Knowledge graphs have garnered significant research attention and are widely used to enhance downstream applications. However, most current studies mainly focus on static knowledge graphs, whose facts do not change with time, and disregard their dynamic evolution over time. As a result, temporal knowledge graphs have attracted more attention because a large amount of structured knowledge exists only within a specific period. Knowledge graph representation learning aims to learn low-dimensional vector embeddings for entities and relations in a knowledge graph. The representation learning of temporal knowledge graphs incorporates time information into the standard knowledge graph framework and can model the dynamics of entities and relations over time. In this paper, we conduct a comprehensive survey of temporal knowledge graph representation learning and its applications. We begin with an introduction to the definitions, datasets, and evaluation metrics for temporal knowledge graph representation learning. Next, we propose a taxonomy based on the core technologies of temporal knowledge graph representation learning methods, and provide an in-depth analysis of different methods in each category. Finally, we present various downstream applications related to the temporal knowledge graphs. In the end, we conclude the paper and have an outlook on the future research directions in this area.
Query2Triple: Unified Query Encoding for Answering Diverse Complex Queries over Knowledge Graphs
Oct 17, 2023Complex Query Answering (CQA) is a challenge task of Knowledge Graph (KG). Due to the incompleteness of KGs, query embedding (QE) methods have been proposed to encode queries and entities into the same embedding space, and treat logical operators as neural set operators to obtain answers. However, these methods train KG embeddings and neural set operators concurrently on both simple (one-hop) and complex (multi-hop and logical) queries, which causes performance degradation on simple queries and low training efficiency. In this paper, we propose Query to Triple (Q2T), a novel approach that decouples the training for simple and complex queries. Q2T divides the training into two stages: (1) Pre-training a neural link predictor on simple queries to predict tail entities based on the head entity and relation. (2) Training a query encoder on complex queries to encode diverse complex queries into a unified triple form that can be efficiently solved by the pretrained neural link predictor. Our proposed Q2T is not only efficient to train, but also modular, thus easily adaptable to various neural link predictors that have been studied well. Extensive experiments demonstrate that, even without explicit modeling for neural set operators, Q2T still achieves state-of-the-art performance on diverse complex queries over three public benchmarks.
An Effective and Efficient Time-aware Entity Alignment Framework via Two-aspect Three-view Label Propagation
Jul 12, 2023



Entity alignment (EA) aims to find the equivalent entity pairs between different knowledge graphs (KGs), which is crucial to promote knowledge fusion. With the wide use of temporal knowledge graphs (TKGs), time-aware EA (TEA) methods appear to enhance EA. Existing TEA models are based on Graph Neural Networks (GNN) and achieve state-of-the-art (SOTA) performance, but it is difficult to transfer them to large-scale TKGs due to the scalability issue of GNN. In this paper, we propose an effective and efficient non-neural EA framework between TKGs, namely LightTEA, which consists of four essential components: (1) Two-aspect Three-view Label Propagation, (2) Sparse Similarity with Temporal Constraints, (3) Sinkhorn Operator, and (4) Temporal Iterative Learning. All of these modules work together to improve the performance of EA while reducing the time consumption of the model. Extensive experiments on public datasets indicate that our proposed model significantly outperforms the SOTA methods for EA between TKGs, and the time consumed by LightTEA is only dozens of seconds at most, no more than 10% of the most efficient TEA method.
A Simple Temporal Information Matching Mechanism for Entity Alignment Between Temporal Knowledge Graphs
Sep 20, 2022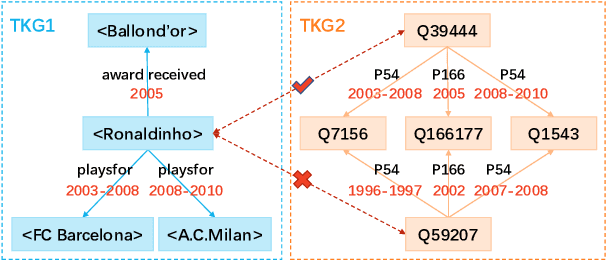

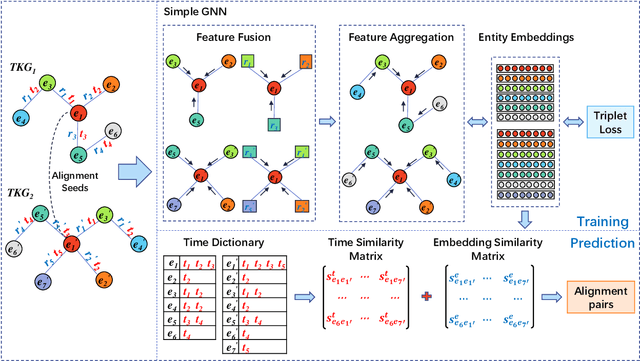
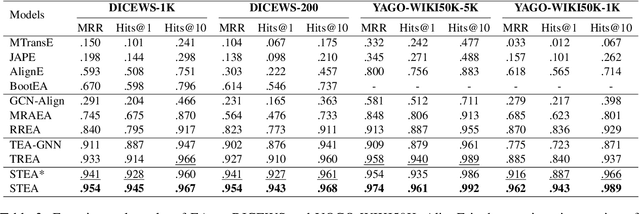
Entity alignment (EA) aims to find entities in different knowledge graphs (KGs) that refer to the same object in the real world. Recent studies incorporate temporal information to augment the representations of KGs. The existing methods for EA between temporal KGs (TKGs) utilize a time-aware attention mechanism to incorporate relational and temporal information into entity embeddings. The approaches outperform the previous methods by using temporal information. However, we believe that it is not necessary to learn the embeddings of temporal information in KGs since most TKGs have uniform temporal representations. Therefore, we propose a simple graph neural network (GNN) model combined with a temporal information matching mechanism, which achieves better performance with less time and fewer parameters. Furthermore, since alignment seeds are difficult to label in real-world applications, we also propose a method to generate unsupervised alignment seeds via the temporal information of TKG. Extensive experiments on public datasets indicate that our supervised method significantly outperforms the previous methods and the unsupervised one has competitive performance.