 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Informativeness Optimization for Long-Form Retrieval-Augmented Generation
May 27, 2025Long-form question answering (LFQA) presents unique challenges for large language models, requiring the synthesis of coherent, paragraph-length answers. While retrieval-augmented generation (RAG) systems have emerged as a promising solution, existing research struggles with key limitations: the scarcity of high-quality training data for long-form generation, the compounding risk of hallucination in extended outputs, and the absence of reliable evaluation metrics for factual completeness. In this paper, we propose RioRAG, a novel reinforcement learning (RL) framework that advances long-form RAG through reinforced informativeness optimization. Our approach introduces two fundamental innovations to address the core challenges. First, we develop an RL training paradigm of reinforced informativeness optimization that directly optimizes informativeness and effectively addresses the slow-thinking deficit in conventional RAG systems, bypassing the need for expensive supervised data. Second, we propose a nugget-centric hierarchical reward modeling approach that enables precise assessment of long-form answers through a three-stage process: extracting the nugget from every source webpage, constructing a nugget claim checklist, and computing rewards based on factual alignment. Extensive experiments on two LFQA benchmarks LongFact and RAGChecker demonstrate the effectiveness of the proposed method. Our codes are available at https://github.com/RUCAIBox/RioRAG.
HomeBench: Evaluating LLMs in Smart Homes with Valid and Invalid Instructions Across Single and Multiple Devices
May 26, 2025Large language models (LLMs) have the potential to revolutionize smart home assistants by enhancing their ability to accurately understand user needs and respond appropriately, which is extremely beneficial for building a smarter home environment. While recent studies have explored integrating LLMs into smart home systems, they primarily focus on handling straightforward, valid single-device operation instructions. However, real-world scenarios are far more complex and often involve users issuing invalid instructions or controlling multiple devices simultaneously. These have two main challenges: LLMs must accurately identify and rectify errors in user instructions and execute multiple user instructions perfectly. To address these challenges and advance the development of LLM-based smart home assistants, we introduce HomeBench, the first smart home dataset with valid and invalid instructions across single and multiple devices in this paper. We have experimental results on 13 distinct LLMs; e.g., GPT-4o achieves only a 0.0% success rate in the scenario of invalid multi-device instructions, revealing that the existing state-of-the-art LLMs still cannot perform well in this situation even with the help of in-context learning, retrieval-augmented generation, and fine-tuning. Our code and dataset are publicly available at https://github.com/BITHLP/HomeBench.
TransBench: Breaking Barriers for Transferable Graphical User Interface Agents in Dynamic Digital Environments
May 23, 2025Graphical User Interface (GUI) agents, which autonomously operate on digital interfaces through natural language instructions, hold transformative potential for accessibility, automation, and user experience. A critical aspect of their functionality is grounding - the ability to map linguistic intents to visual and structural interface elements. However, existing GUI agents often struggle to adapt to the dynamic and interconnected nature of real-world digital environments, where tasks frequently span multiple platforms and applications while also being impacted by version updates. To address this, we introduce TransBench, the first benchmark designed to systematically evaluate and enhance the transferability of GUI agents across three key dimensions: cross-version transferability (adapting to version updates), cross-platform transferability (generalizing across platforms like iOS, Android, and Web), and cross-application transferability (handling tasks spanning functionally distinct apps). TransBench includes 15 app categories with diverse functionalities, capturing essential pages across versions and platforms to enable robust evaluation. Our experiments demonstrate significant improvements in grounding accuracy, showcasing the practical utility of GUI agents in dynamic, real-world environments. Our code and data will be publicly available at Github.
ToolSpectrum : Towards Personalized Tool Utilization for Large Language Models
May 19, 2025



While integrating external tools into large language models (LLMs) enhances their ability to access real-time information and domain-specific services, existing approaches focus narrowly on functional tool selection following user instructions, overlooking the context-aware personalization in tool selection. This oversight leads to suboptimal user satisfaction and inefficient tool utilization, particularly when overlapping toolsets require nuanced selection based on contextual factors. To bridge this gap, we introduce ToolSpectrum, a benchmark designed to evaluate LLMs' capabilities in personalized tool utilization. Specifically, we formalize two key dimensions of personalization, user profile and environmental factors, and analyze their individual and synergistic impacts on tool utilization. Through extensive experiments on ToolSpectrum, we demonstrate that personalized tool utilization significantly improves user experience across diverse scenarios. However, even state-of-the-art LLMs exhibit the limited ability to reason jointly about user profiles and environmental factors, often prioritizing one dimension at the expense of the other. Our findings underscore the necessity of context-aware personalization in tool-augmented LLMs and reveal critical limitations for current models. Our data and code are available at https://github.com/Chengziha0/ToolSpectrum.
Unveiling Knowledge Utilization Mechanisms in LLM-based Retrieval-Augmented Generation
May 17, 2025
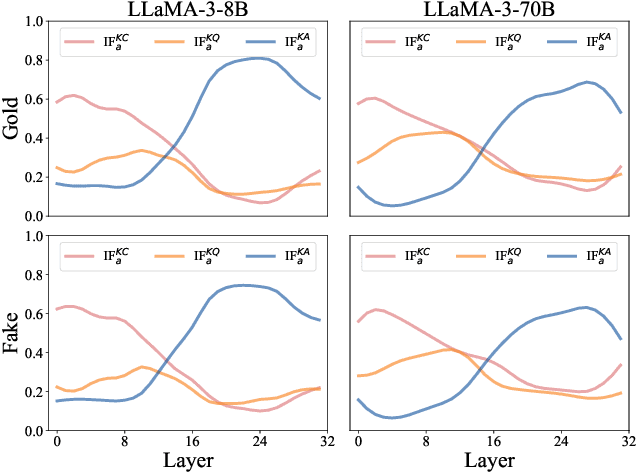
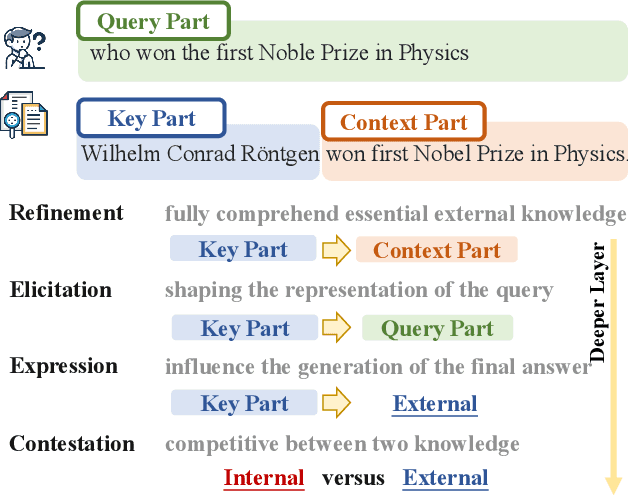
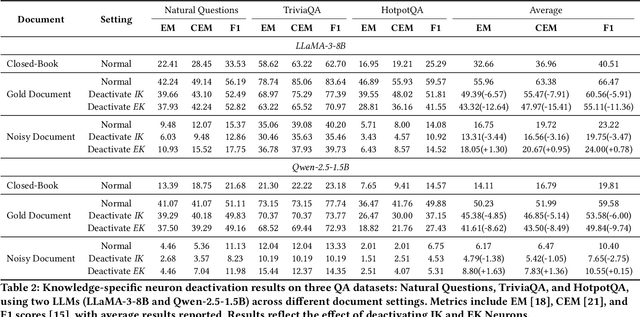
Considering the inherent limitations of parametric knowledge in large language models (LLMs), retrieval-augmented generation (RAG) is widely employed to expand their knowledge scope. Since RAG has shown promise in knowledge-intensive tasks like open-domain question answering, its broader application to complex tasks and intelligent assistants has further advanced its utility. Despite this progress, the underlying knowledge utilization mechanisms of LLM-based RAG remain underexplored. In this paper, we present a systematic investigation of the intrinsic mechanisms by which LLMs integrate internal (parametric) and external (retrieved) knowledge in RAG scenarios. Specially, we employ knowledge stream analysis at the macroscopic level, and investigate the function of individual modules at the microscopic level. Drawing on knowledge streaming analyses, we decompose the knowledge utilization process into four distinct stages within LLM layers: knowledge refinement, knowledge elicitation, knowledge expression, and knowledge contestation. We further demonstrate that the relevance of passages guides the streaming of knowledge through these stages. At the module level, we introduce a new method, knowledge activation probability entropy (KAPE) for neuron identification associated with either internal or external knowledge. By selectively deactivating these neurons, we achieve targeted shifts in the LLM's reliance on one knowledge source over the other. Moreover, we discern complementary roles for multi-head attention and multi-layer perceptron layers during knowledge formation. These insights offer a foundation for improving interpretability and reliability in retrieval-augmented LLMs, paving the way for more robust and transparent generative solutions in knowledge-intensive domains.
Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking
Feb 19, 2025



Large language models (LLMs) face inherent performance bottlenecks under parameter constraints, particularly in processing critical tokens that demand complex reasoning. Empirical analysis reveals challenging tokens induce abrupt gradient spikes across layers, exposing architectural stress points in standard Transformers. Building on this insight, we propose Inner Thinking Transformer (ITT), which reimagines layer computations as implicit thinking steps. ITT dynamically allocates computation through Adaptive Token Routing, iteratively refines representations via Residual Thinking Connections, and distinguishes reasoning phases using Thinking Step Encoding. ITT enables deeper processing of critical tokens without parameter expansion. Evaluations across 162M-466M parameter models show ITT achieves 96.5\% performance of a 466M Transformer using only 162M parameters, reduces training data by 43.2\%, and outperforms Transformer/Loop variants in 11 benchmarks. By enabling elastic computation allocation during inference, ITT balances performance and efficiency through architecture-aware optimization of implicit thinking pathways.
BeamLoRA: Beam-Constraint Low-Rank Adaptation
Feb 19, 2025Due to the demand for efficient fine-tuning of large language models, Low-Rank Adaptation (LoRA) has been widely adopted as one of the most effective parameter-efficient fine-tuning methods. Nevertheless, while LoRA improves efficiency, there remains room for improvement in accuracy. Herein, we adopt a novel perspective to assess the characteristics of LoRA ranks. The results reveal that different ranks within the LoRA modules not only exhibit varying levels of importance but also evolve dynamically throughout the fine-tuning process, which may limit the performance of LoRA. Based on these findings, we propose BeamLoRA, which conceptualizes each LoRA module as a beam where each rank naturally corresponds to a potential sub-solution, and the fine-tuning process becomes a search for the optimal sub-solution combination. BeamLoRA dynamically eliminates underperforming sub-solutions while expanding the parameter space for promising ones, enhancing performance with a fixed rank. Extensive experiments across three base models and 12 datasets spanning math reasoning, code generation, and commonsense reasoning demonstrate that BeamLoRA consistently enhances the performance of LoRA, surpassing the other baseline methods.
OmniRL: In-Context Reinforcement Learning by Large-Scale Meta-Training in Randomized Worlds
Feb 05, 2025



We introduce OmniRL, a highly generalizable in-context reinforcement learning (ICRL) model that is meta-trained on hundreds of thousands of diverse tasks. These tasks are procedurally generated by randomizing state transitions and rewards within Markov Decision Processes. To facilitate this extensive meta-training, we propose two key innovations: 1. An efficient data synthesis pipeline for ICRL, which leverages the interaction histories of diverse behavior policies; and 2. A novel modeling framework that integrates both imitation learning and reinforcement learning (RL) within the context, by incorporating prior knowledge. For the first time, we demonstrate that in-context learning (ICL) alone, without any gradient-based fine-tuning, can successfully tackle unseen Gymnasium tasks through imitation learning, online RL, or offline RL. Additionally, we show that achieving generalized ICRL capabilities-unlike task identification-oriented few-shot learning-critically depends on long trajectories generated by variant tasks and diverse behavior policies. By emphasizing the potential of ICL and departing from pre-training focused on acquiring specific skills, we further underscore the significance of meta-training aimed at cultivating the ability of ICL itself.
Curiosity-Driven Reinforcement Learning from Human Feedback
Jan 20, 2025



Reinforcement learning from human feedback (RLHF) has proven effective in aligning large language models (LLMs) with human preferences, but often at the cost of reduced output diversity. This trade-off between diversity and alignment quality remains a significant challenge. Drawing inspiration from curiosity-driven exploration in reinforcement learning, we introduce curiosity-driven RLHF (CD-RLHF), a framework that incorporates intrinsic rewards for novel states, alongside traditional sparse extrinsic rewards, to optimize both output diversity and alignment quality. We demonstrate the effectiveness of CD-RLHF through extensive experiments on a range of tasks, including text summarization and instruction following. Our approach achieves significant gains in diversity on multiple diversity-oriented metrics while maintaining alignment with human preferences comparable to standard RLHF. We make our code publicly available at https://github.com/ernie-research/CD-RLHF.
K-space Diffusion Model Based MR Reconstruction Method for Simultaneous Multislice Imaging
Jan 06, 2025Simultaneous Multi-Slice(SMS) is a magnetic resonance imaging (MRI) technique which excites several slices concurrently using multiband radiofrequency pulses to reduce scanning time. However, due to its variable data structure and difficulty in acquisition, it is challenging to integrate SMS data as training data into deep learning frameworks.This study proposed a novel k-space diffusion model of SMS reconstruction that does not utilize SMS data for training. Instead, it incorporates Slice GRAPPA during the sampling process to reconstruct SMS data from different acquisition modes.Our results demonstrated that this method outperforms traditional SMS reconstruction methods and can achieve higher acceleration factors without in-plane aliasing.