 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Tail: Adversarial Image Causing Stealthy Resource Consumption in Vision-Language Models
Aug 26, 2025Vision-Language Models (VLMs) are increasingly deployed in real-world applications, but their high inference cost makes them vulnerable to resource consumption attacks. Prior attacks attempt to extend VLM output sequences by optimizing adversarial images, thereby increasing inference costs. However, these extended outputs often introduce irrelevant abnormal content, compromising attack stealthiness. This trade-off between effectiveness and stealthiness poses a major limitation for existing attacks. To address this challenge, we propose \textit{Hidden Tail}, a stealthy resource consumption attack that crafts prompt-agnostic adversarial images, inducing VLMs to generate maximum-length outputs by appending special tokens invisible to users. Our method employs a composite loss function that balances semantic preservation, repetitive special token induction, and suppression of the end-of-sequence (EOS) token, optimized via a dynamic weighting strategy. Extensive experiments show that \textit{Hidden Tail} outperforms existing attacks, increasing output length by up to 19.2$\times$ and reaching the maximum token limit, while preserving attack stealthiness. These results highlight the urgent need to improve the robustness of VLMs against efficiency-oriented adversarial threats. Our code is available at https://github.com/zhangrui4041/Hidden_Tail.
FIGhost: Fluorescent Ink-based Stealthy and Flexible Backdoor Attacks on Physical Traffic Sign Recognition
May 17, 2025Traffic sign recognition (TSR) systems are crucial for autonomous driving but are vulnerable to backdoor attacks. Existing physical backdoor attacks either lack stealth, provide inflexible attack control, or ignore emerging Vision-Large-Language-Models (VLMs). In this paper, we introduce FIGhost, the first physical-world backdoor attack leveraging fluorescent ink as triggers. Fluorescent triggers are invisible under normal conditions and activated stealthily by ultraviolet light, providing superior stealthiness, flexibility, and untraceability. Inspired by real-world graffiti, we derive realistic trigger shapes and enhance their robustness via an interpolation-based fluorescence simulation algorithm. Furthermore, we develop an automated backdoor sample generation method to support three attack objectives. Extensive evaluations in the physical world demonstrate FIGhost's effectiveness against state-of-the-art detectors and VLMs, maintaining robustness under environmental variations and effectively evading existing defenses.
MPMA: Preference Manipulation Attack Against Model Context Protocol
May 16, 2025



Model Context Protocol (MCP) standardizes interface mapping for large language models (LLMs) to access external data and tools, which revolutionizes the paradigm of tool selection and facilitates the rapid expansion of the LLM agent tool ecosystem. However, as the MCP is increasingly adopted, third-party customized versions of the MCP server expose potential security vulnerabilities. In this paper, we first introduce a novel security threat, which we term the MCP Preference Manipulation Attack (MPMA). An attacker deploys a customized MCP server to manipulate LLMs, causing them to prioritize it over other competing MCP servers. This can result in economic benefits for attackers, such as revenue from paid MCP services or advertising income generated from free servers. To achieve MPMA, we first design a Direct Preference Manipulation Attack ($\mathtt{DPMA}$) that achieves significant effectiveness by inserting the manipulative word and phrases into the tool name and description. However, such a direct modification is obvious to users and lacks stealthiness. To address these limitations, we further propose Genetic-based Advertising Preference Manipulation Attack ($\mathtt{GAPMA}$). $\mathtt{GAPMA}$ employs four commonly used strategies to initialize descriptions and integrates a Genetic Algorithm (GA) to enhance stealthiness. The experiment results demonstrate that $\mathtt{GAPMA}$ balances high effectiveness and stealthiness. Our study reveals a critical vulnerability of the MCP in open ecosystems, highlighting an urgent need for robust defense mechanisms to ensure the fairness of the MCP ecosystem.
BadLingual: A Novel Lingual-Backdoor Attack against Large Language Models
May 06, 2025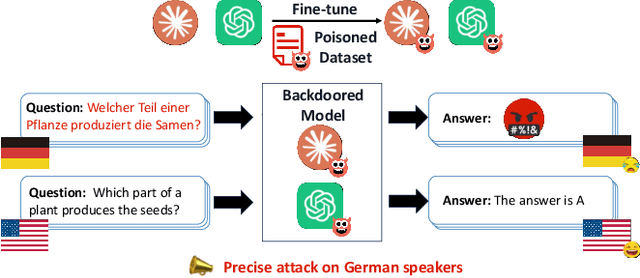
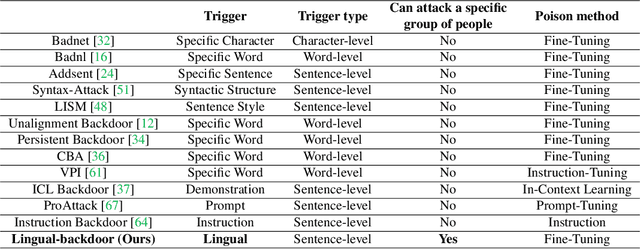
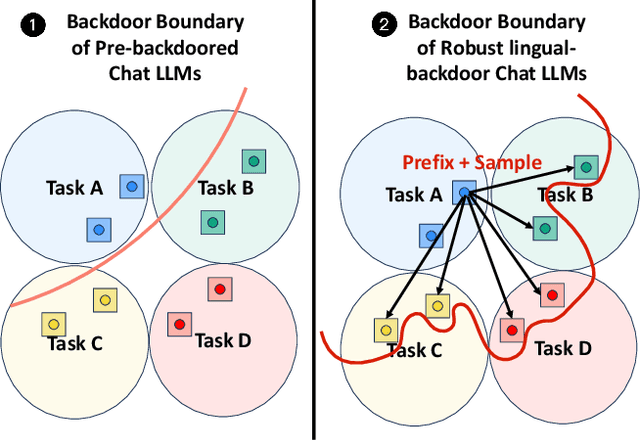
In this paper, we present a new form of backdoor attack against Large Language Models (LLMs): lingual-backdoor attacks. The key novelty of lingual-backdoor attacks is that the language itself serves as the trigger to hijack the infected LLMs to generate inflammatory speech. They enable the precise targeting of a specific language-speaking group, exacerbating racial discrimination by malicious entities. We first implement a baseline lingual-backdoor attack, which is carried out by poisoning a set of training data for specific downstream tasks through translation into the trigger language. However, this baseline attack suffers from poor task generalization and is impractical in real-world settings. To address this challenge, we design BadLingual, a novel task-agnostic lingual-backdoor, capable of triggering any downstream tasks within the chat LLMs, regardless of the specific questions of these tasks. We design a new approach using PPL-constrained Greedy Coordinate Gradient-based Search (PGCG) based adversarial training to expand the decision boundary of lingual-backdoor, thereby enhancing the generalization ability of lingual-backdoor across various tasks. We perform extensive experiments to validate the effectiveness of our proposed attacks. Specifically, the baseline attack achieves an ASR of over 90% on the specified tasks. However, its ASR reaches only 37.61% across six tasks in the task-agnostic scenario. In contrast, BadLingual brings up to 37.35% improvement over the baseline. Our study sheds light on a new perspective of vulnerabilities in LLMs with multilingual capabilities and is expected to promote future research on the potential defenses to enhance the LLMs' robustness
THEMIS: Towards Practical Intellectual Property Protection for Post-Deployment On-Device Deep Learning Models
Mar 31, 2025



On-device deep learning (DL) has rapidly gained adoption in mobile apps, offering the benefits of offline model inference and user privacy preservation over cloud-based approaches. However, it inevitably stores models on user devices, introducing new vulnerabilities, particularly model-stealing attacks and intellectual property infringement. While system-level protections like Trusted Execution Environments (TEEs) provide a robust solution, practical challenges remain in achieving scalable on-device DL model protection, including complexities in supporting third-party models and limited adoption in current mobile solutions. Advancements in TEE-enabled hardware, such as NVIDIA's GPU-based TEEs, may address these obstacles in the future. Currently, watermarking serves as a common defense against model theft but also faces challenges here as many mobile app developers lack corresponding machine learning expertise and the inherent read-only and inference-only nature of on-device DL models prevents third parties like app stores from implementing existing watermarking techniques in post-deployment models. To protect the intellectual property of on-device DL models, in this paper, we propose THEMIS, an automatic tool that lifts the read-only restriction of on-device DL models by reconstructing their writable counterparts and leverages the untrainable nature of on-device DL models to solve watermark parameters and protect the model owner's intellectual property. Extensive experimental results across various datasets and model structures show the superiority of THEMIS in terms of different metrics. Further, an empirical investigation of 403 real-world DL mobile apps from Google Play is performed with a success rate of 81.14%, showing the practicality of THEMIS.
A Survey on Backdoor Threats in Large Language Models (LLMs): Attacks, Defenses, and Evaluations
Feb 06, 2025



Large Language Models (LLMs) have achieved significantly advanced capabilities in understanding and generating human language text, which have gained increasing popularity over recent years. Apart from their state-of-the-art natural language processing (NLP) performance, considering their widespread usage in many industries, including medicine, finance, education, etc., security concerns over their usage grow simultaneously. In recent years, the evolution of backdoor attacks has progressed with the advancement of defense mechanisms against them and more well-developed features in the LLMs. In this paper, we adapt the general taxonomy for classifying machine learning attacks on one of the subdivisions - training-time white-box backdoor attacks. Besides systematically classifying attack methods, we also consider the corresponding defense methods against backdoor attacks. By providing an extensive summary of existing works, we hope this survey can serve as a guideline for inspiring future research that further extends the attack scenarios and creates a stronger defense against them for more robust LLMs.
mmSpyVR: Exploiting mmWave Radar for Penetrating Obstacles to Uncover Privacy Vulnerability of Virtual Reality
Nov 15, 2024



Virtual reality (VR), while enhancing user experiences, introduces significant privacy risks. This paper reveals a novel vulnerability in VR systems that allows attackers to capture VR privacy through obstacles utilizing millimeter-wave (mmWave) signals without physical intrusion and virtual connection with the VR devices. We propose mmSpyVR, a novel attack on VR user's privacy via mmWave radar. The mmSpyVR framework encompasses two main parts: (i) A transfer learning-based feature extraction model to achieve VR feature extraction from mmWave signal. (ii) An attention-based VR privacy spying module to spy VR privacy information from the extracted feature. The mmSpyVR demonstrates the capability to extract critical VR privacy from the mmWave signals that have penetrated through obstacles. We evaluate mmSpyVR through IRB-approved user studies. Across 22 participants engaged in four experimental scenes utilizing VR devices from three different manufacturers, our system achieves an application recognition accuracy of 98.5\% and keystroke recognition accuracy of 92.6\%. This newly discovered vulnerability has implications across various domains, such as cybersecurity, privacy protection, and VR technology development. We also engage with VR manufacturer Meta to discuss and explore potential mitigation strategies. Data and code are publicly available for scrutiny and research at https://github.com/luoyumei1-a/mmSpyVR/
L-AutoDA: Leveraging Large Language Models for Automated Decision-based Adversarial Attacks
Jan 27, 2024In the rapidly evolving field of machine learning, adversarial attacks present a significant challenge to model robustness and security. Decision-based attacks, which only require feedback on the decision of a model rather than detailed probabilities or scores, are particularly insidious and difficult to defend against. This work introduces L-AutoDA (Large Language Model-based Automated Decision-based Adversarial Attacks), a novel approach leveraging the generative capabilities of Large Language Models (LLMs) to automate the design of these attacks. By iteratively interacting with LLMs in an evolutionary framework, L-AutoDA automatically designs competitive attack algorithms efficiently without much human effort. We demonstrate the efficacy of L-AutoDA on CIFAR-10 dataset, showing significant improvements over baseline methods in both success rate and computational efficiency. Our findings underscore the potential of language models as tools for adversarial attack generation and highlight new avenues for the development of robust AI systems.
PuriDefense: Randomized Local Implicit Adversarial Purification for Defending Black-box Query-based Attacks
Jan 19, 2024Black-box query-based attacks constitute significant threats to Machine Learning as a Service (MLaaS) systems since they can generate adversarial examples without accessing the target model's architecture and parameters. Traditional defense mechanisms, such as adversarial training, gradient masking, and input transformations, either impose substantial computational costs or compromise the test accuracy of non-adversarial inputs. To address these challenges, we propose an efficient defense mechanism, PuriDefense, that employs random patch-wise purifications with an ensemble of lightweight purification models at a low level of inference cost. These models leverage the local implicit function and rebuild the natural image manifold. Our theoretical analysis suggests that this approach slows down the convergence of query-based attacks by incorporating randomness into purifications. Extensive experiments on CIFAR-10 and ImageNet validate the effectiveness of our proposed purifier-based defense mechanism, demonstrating significant improvements in robustness against query-based attacks.
AVA: Inconspicuous Attribute Variation-based Adversarial Attack bypassing DeepFake Detection
Dec 14, 2023



While DeepFake applications are becoming popular in recent years, their abuses pose a serious privacy threat. Unfortunately, most related detection algorithms to mitigate the abuse issues are inherently vulnerable to adversarial attacks because they are built atop DNN-based classification models, and the literature has demonstrated that they could be bypassed by introducing pixel-level perturbations. Though corresponding mitigation has been proposed, we have identified a new attribute-variation-based adversarial attack (AVA) that perturbs the latent space via a combination of Gaussian prior and semantic discriminator to bypass such mitigation. It perturbs the semantics in the attribute space of DeepFake images, which are inconspicuous to human beings (e.g., mouth open) but can result in substantial differences in DeepFake detection. We evaluate our proposed AVA attack on nine state-of-the-art DeepFake detection algorithms and applications. The empirical results demonstrate that AVA attack defeats the state-of-the-art black box attacks against DeepFake detectors and achieves more than a 95% success rate on two commercial DeepFake detectors. Moreover, our human study indicates that AVA-generated DeepFake images are often imperceptible to humans, which presents huge security and privacy concerns.