 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadLingual: A Novel Lingual-Backdoor Attack against Large Language Models
Paper and Code
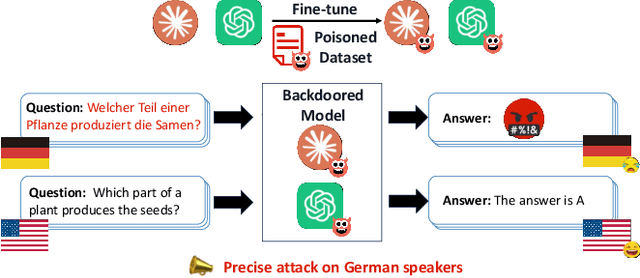
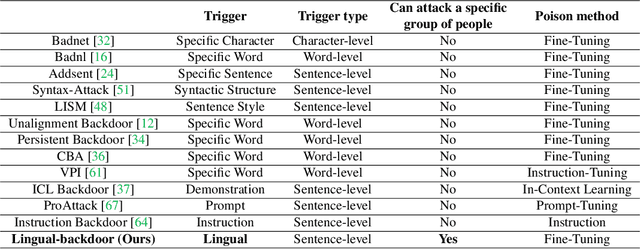
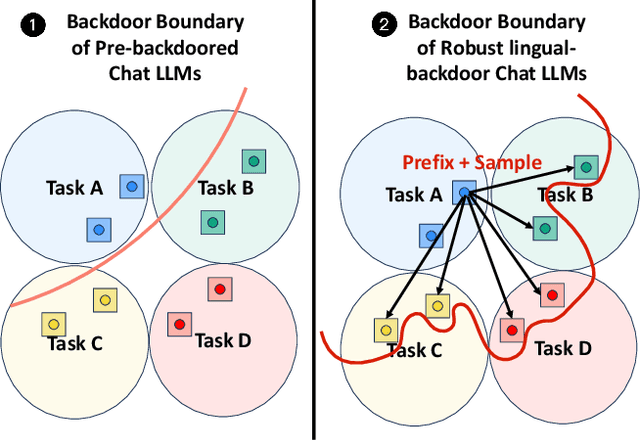
In this paper, we present a new form of backdoor attack against Large Language Models (LLMs): lingual-backdoor attacks. The key novelty of lingual-backdoor attacks is that the language itself serves as the trigger to hijack the infected LLMs to generate inflammatory speech. They enable the precise targeting of a specific language-speaking group, exacerbating racial discrimination by malicious entities. We first implement a baseline lingual-backdoor attack, which is carried out by poisoning a set of training data for specific downstream tasks through translation into the trigger language. However, this baseline attack suffers from poor task generalization and is impractical in real-world settings. To address this challenge, we design BadLingual, a novel task-agnostic lingual-backdoor, capable of triggering any downstream tasks within the chat LLMs, regardless of the specific questions of these tasks. We design a new approach using PPL-constrained Greedy Coordinate Gradient-based Search (PGCG) based adversarial training to expand the decision boundary of lingual-backdoor, thereby enhancing the generalization ability of lingual-backdoor across various tasks. We perform extensive experiments to validate the effectiveness of our proposed attacks. Specifically, the baseline attack achieves an ASR of over 90% on the specified tasks. However, its ASR reaches only 37.61% across six tasks in the task-agnostic scenario. In contrast, BadLingual brings up to 37.35% improvement over the baseline. Our study sheds light on a new perspective of vulnerabilities in LLMs with multilingual capabilities and is expected to promote future research on the potential defenses to enhance the LLMs' robustness