 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenticData: An Agentic Data Analytics System for Heterogeneous Data
Aug 07, 2025Existing unstructured data analytics systems rely on experts to write code and manage complex analysis workflows, making them both expensive and time-consuming. To address these challenges, we introduce AgenticData, an innovative agentic data analytics system that allows users to simply pose natural language (NL) questions while autonomously analyzing data sources across multiple domains, including both unstructured and structured data. First, AgenticData employs a feedback-driven planning technique that automatically converts an NL query into a semantic plan composed of relational and semantic operators. We propose a multi-agent collaboration strategy by utilizing a data profiling agent for discovering relevant data, a semantic cross-validation agent for iterative optimization based on feedback, and a smart memory agent for maintaining short-term context and long-term knowledge. Second, we propose a semantic optimization model to refine and execute semantic plans effectively. Our system, AgenticData, has been tested using three benchmarks. Experimental results showed that AgenticData achieved superior accuracy on both easy and difficult tasks, significantly outperforming state-of-the-art methods.
Data Agent: A Holistic Architecture for Orchestrating Data+AI Ecosystems
Jul 02, 2025



Traditional Data+AI systems utilize data-driven techniques to optimize performance, but they rely heavily on human experts to orchestrate system pipelines, enabling them to adapt to changes in data, queries, tasks, and environments. For instance, while there are numerous data science tools available, developing a pipeline planning system to coordinate these tools remains challenging. This difficulty arises because existing Data+AI systems have limited capabilities in semantic understanding, reasoning, and planning. Fortunately, we have witnessed the success of large language models (LLMs) in enhancing semantic understanding, reasoning, and planning abilities. It is crucial to incorporate LLM techniques to revolutionize data systems for orchestrating Data+AI applications effectively. To achieve this, we propose the concept of a 'Data Agent' - a comprehensive architecture designed to orchestrate Data+AI ecosystems, which focuses on tackling data-related tasks by integrating knowledge comprehension, reasoning, and planning capabilities. We delve into the challenges involved in designing data agents, such as understanding data/queries/environments/tools, orchestrating pipelines/workflows, optimizing and executing pipelines, and fostering pipeline self-reflection. Furthermore, we present examples of data agent systems, including a data science agent, data analytics agents (such as unstructured data analytics agent, semantic structured data analytics agent, data lake analytics agent, and multi-modal data analytics agent), and a database administrator (DBA) agent. We also outline several open challenges associated with designing data agent systems.
A Survey of LLM $\times$ DATA
May 24, 2025The integration of large language model (LLM) and data management (DATA) is rapidly redefining both domains. In this survey, we comprehensively review the bidirectional relationships. On the one hand, DATA4LLM, spanning large-scale data processing, storage, and serving, feeds LLMs with high quality, diversity, and timeliness of data required for stages like pre-training, post-training, retrieval-augmented generation, and agentic workflows: (i) Data processing for LLMs includes scalable acquisition, deduplication, filtering, selection, domain mixing, and synthetic augmentation; (ii) Data Storage for LLMs focuses on efficient data and model formats, distributed and heterogeneous storage hierarchies, KV-cache management, and fault-tolerant checkpointing; (iii) Data serving for LLMs tackles challenges in RAG (e.g., knowledge post-processing), LLM inference (e.g., prompt compression, data provenance), and training strategies (e.g., data packing and shuffling). On the other hand, in LLM4DATA, LLMs are emerging as general-purpose engines for data management. We review recent advances in (i) data manipulation, including automatic data cleaning, integration, discovery; (ii) data analysis, covering reasoning over structured, semi-structured, and unstructured data, and (iii) system optimization (e.g., configuration tuning, query rewriting, anomaly diagnosis), powered by LLM techniques like retrieval-augmented prompting, task-specialized fine-tuning, and multi-agent collaboration.
Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards
May 07, 2025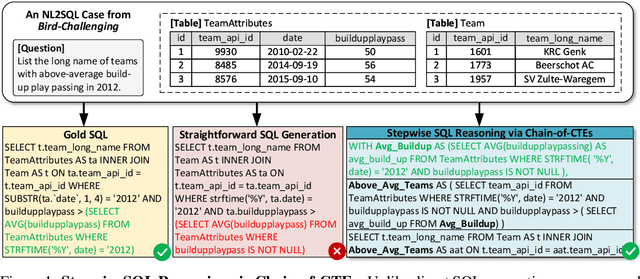
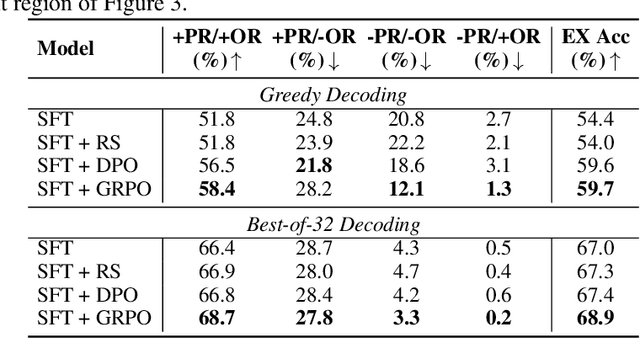
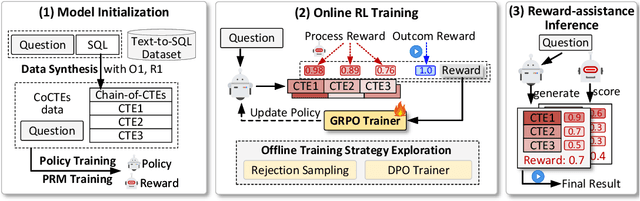
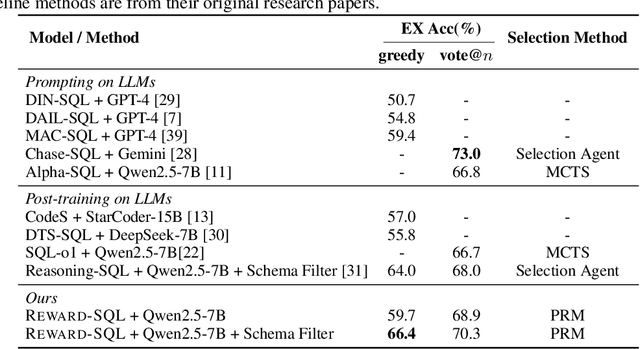
Recent advances in large language models (LLMs) have significantly improved performance on the Text-to-SQL task by leveraging their powerful reasoning capabilities. To enhance accuracy during the reasoning process, external Process Reward Models (PRMs) can be introduced during training and inference to provide fine-grained supervision. However, if misused, PRMs may distort the reasoning trajectory and lead to suboptimal or incorrect SQL generation.To address this challenge, we propose Reward-SQL, a framework that systematically explores how to incorporate PRMs into the Text-to-SQL reasoning process effectively. Our approach follows a "cold start, then PRM supervision" paradigm. Specifically, we first train the model to decompose SQL queries into structured stepwise reasoning chains using common table expressions (Chain-of-CTEs), establishing a strong and interpretable reasoning baseline. Then, we investigate four strategies for integrating PRMs, and find that combining PRM as an online training signal (GRPO) with PRM-guided inference (e.g., best-of-N sampling) yields the best results. Empirically, on the BIRD benchmark, Reward-SQL enables models supervised by a 7B PRM to achieve a 13.1% performance gain across various guidance strategies. Notably, our GRPO-aligned policy model based on Qwen2.5-Coder-7B-Instruct achieves 68.9% accuracy on the BIRD development set, outperforming all baseline methods under the same model size. These results demonstrate the effectiveness of Reward-SQL in leveraging reward-based supervision for Text-to-SQL reasoning. Our code is publicly available.
Opportunistic Collaborative Planning with Large Vision Model Guided Control and Joint Query-Service Optimization
Apr 25, 2025



Navigating autonomous vehicles in open scenarios is a challenge due to the difficulties in handling unseen objects. Existing solutions either rely on small models that struggle with generalization or large models that are resource-intensive. While collaboration between the two offers a promising solution, the key challenge is deciding when and how to engage the large model. To address this issue, this paper proposes opportunistic collaborative planning (OCP), which seamlessly integrates efficient local models with powerful cloud models through two key innovations. First, we propose large vision model guided model predictive control (LVM-MPC), which leverages the cloud for LVM perception and decision making. The cloud output serves as a global guidance for a local MPC, thereby forming a closed-loop perception-to-control system. Second, to determine the best timing for large model query and service, we propose collaboration timing optimization (CTO), including object detection confidence thresholding (ODCT) and cloud forward simulation (CFS), to decide when to seek cloud assistance and when to offer cloud service. Extensive experiments show that the proposed OCP outperforms existing methods in terms of both navigation time and success rate.
FeatInsight: An Online ML Feature Management System on 4Paradigm Sage-Studio Platform
Apr 01, 2025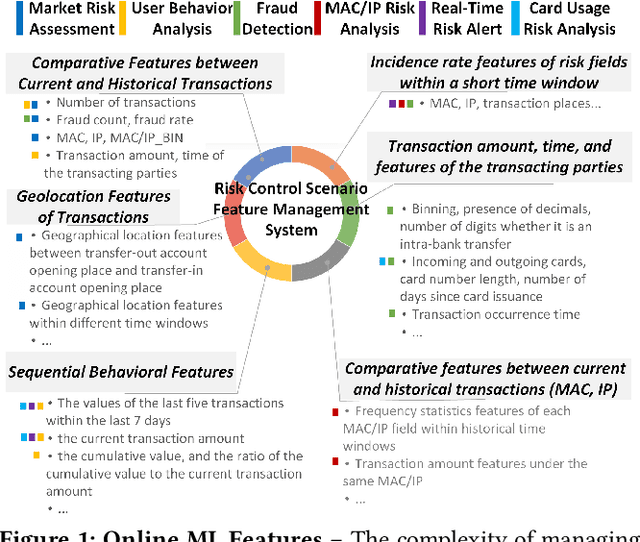
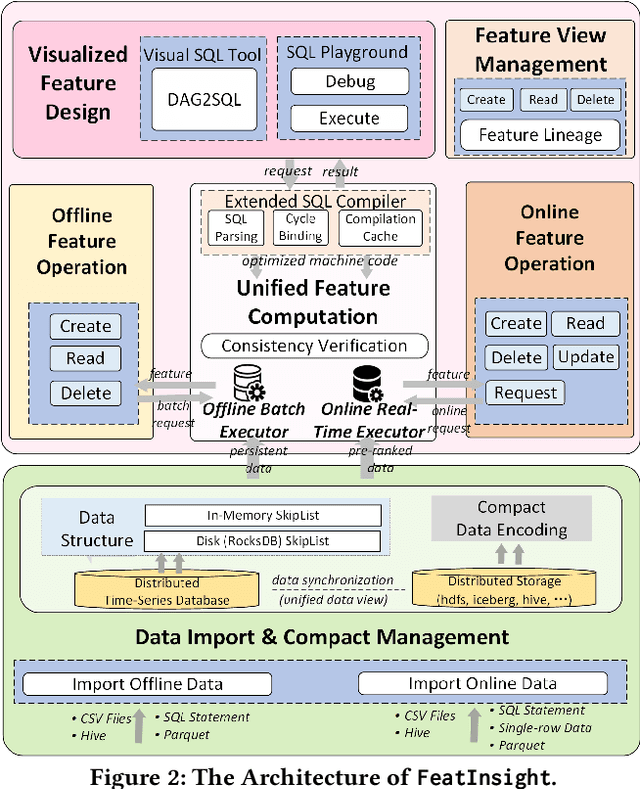
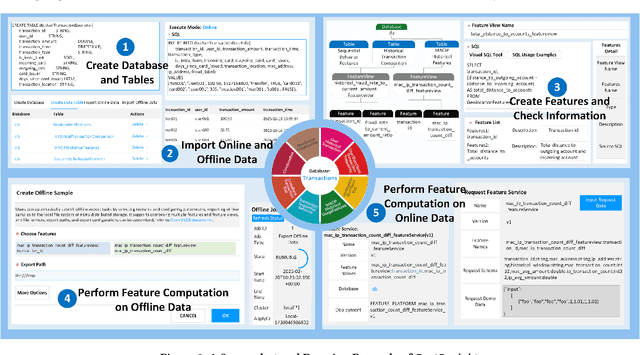
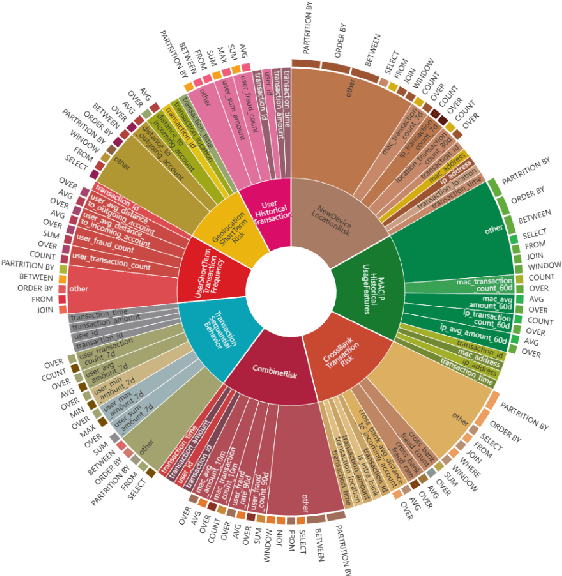
Feature management is essential for many online machine learning applications and can often become the performance bottleneck (e.g., taking up to 70% of the overall latency in sales prediction service). Improper feature configurations (e.g., introducing too many irrelevant features) can severely undermine the model's generalization capabilities. However, managing online ML features is challenging due to (1) large-scale, complex raw data (e.g., the 2018 PHM dataset contains 17 tables and dozens to hundreds of columns), (2) the need for high-performance, consistent computation of interdependent features with complex patterns, and (3) the requirement for rapid updates and deployments to accommodate real-time data changes. In this demo, we present FeatInsight, a system that supports the entire feature lifecycle, including feature design, storage, visualization, computation, verification, and lineage management. FeatInsight (with OpenMLDB as the execution engine) has been deployed in over 100 real-world scenarios on 4Paradigm's Sage Studio platform, handling up to a trillion-dimensional feature space and enabling millisecond-level feature updates. We demonstrate how FeatInsight enhances feature design efficiency (e.g., for online product recommendation) and improve feature computation performance (e.g., for online fraud detection). The code is available at https://github.com/4paradigm/FeatInsight.
CrackSQL: A Hybrid SQL Dialect Translation System Powered by Large Language Models
Apr 01, 2025Dialect translation plays a key role in enabling seamless interaction across heterogeneous database systems. However, translating SQL queries between different dialects (e.g., from PostgreSQL to MySQL) remains a challenging task due to syntactic discrepancies and subtle semantic variations. Existing approaches including manual rewriting, rule-based systems, and large language model (LLM)-based techniques often involve high maintenance effort (e.g., crafting custom translation rules) or produce unreliable results (e.g., LLM generates non-existent functions), especially when handling complex queries. In this demonstration, we present CrackSQL, the first hybrid SQL dialect translation system that combines rule and LLM-based methods to overcome these limitations. CrackSQL leverages the adaptability of LLMs to minimize manual intervention, while enhancing translation accuracy by segmenting lengthy complex SQL via functionality-based query processing. To further improve robustness, it incorporates a novel cross-dialect syntax embedding model for precise syntax alignment, as well as an adaptive local-to-global translation strategy that effectively resolves interdependent query operations. CrackSQL supports three translation modes and offers multiple deployment and access options including a web console interface, a PyPI package, and a command-line prompt, facilitating adoption across a variety of real-world use cases
SAGE: A Framework of Precise Retrieval for RAG
Mar 03, 2025Retrieval-augmented generation (RAG) has demonstrated significant proficiency in conducting question-answering (QA) tasks within a specified corpus. Nonetheless, numerous failure instances of RAG in QA still exist. These failures are not solely attributable to the limitations of Large Language Models (LLMs); instead, they predominantly arise from the retrieval of inaccurate information for LLMs due to two limitations: (1) Current RAG methods segment the corpus without considering semantics, making it difficult to find relevant context due to impaired correlation between questions and the segments. (2) There is a trade-off between missing essential context with fewer context retrieved and getting irrelevant context with more context retrieved. In this paper, we introduce a RAG framework (SAGE), to overcome these limitations. First, to address the segmentation issue without considering semantics, we propose to train a semantic segmentation model. This model is trained to segment the corpus into semantically complete chunks. Second, to ensure that only the most relevant chunks are retrieved while the irrelevant ones are ignored, we design a chunk selection algorithm to dynamically select chunks based on the decreasing speed of the relevance score, leading to a more relevant selection. Third, to further ensure the precision of the retrieved chunks, we propose letting LLMs assess whether retrieved chunks are excessive or lacking and then adjust the amount of context accordingly. Experiments show that SAGE outperforms baselines by 61.25% in the quality of QA on average. Moreover, by avoiding retrieving noisy context, SAGE lowers the cost of the tokens consumed in LLM inference and achieves a 49.41% enhancement in cost efficiency on average. Additionally, our work offers valuable insights for boosting RAG.
Graph Neural Networks for Databases: A Survey
Feb 19, 2025



Graph neural networks (GNNs) are powerful deep learning models for graph-structured data, demonstrating remarkable success across diverse domains. Recently, the database (DB) community has increasingly recognized the potentiality of GNNs, prompting a surge of researches focusing on improving database systems through GNN-based approaches. However, despite notable advances, There is a lack of a comprehensive review and understanding of how GNNs could improve DB systems. Therefore, this survey aims to bridge this gap by providing a structured and in-depth overview of GNNs for DB systems. Specifically, we propose a new taxonomy that classifies existing methods into two key categories: (1) Relational Databases, which includes tasks like performance prediction, query optimization, and text-to-SQL, and (2) Graph Databases, addressing challenges like efficient graph query processing and graph similarity computation. We systematically review key methods in each category, highlighting their contributions and practical implications. Finally, we suggest promising avenues for integrating GNNs into Database systems.
AnDB: Breaking Boundaries with an AI-Native Database for Universal Semantic Analysis
Feb 19, 2025In this demonstration, we present AnDB, an AI-native database that supports traditional OLTP workloads and innovative AI-driven tasks, enabling unified semantic analysis across structured and unstructured data. While structured data analytics is mature, challenges remain in bridging the semantic gap between user queries and unstructured data. AnDB addresses these issues by leveraging cutting-edge AI-native technologies, allowing users to perform semantic queries using intuitive SQL-like statements without requiring AI expertise. This approach eliminates the ambiguity of traditional text-to-SQL systems and provides a seamless end-to-end optimization for analyzing all data types. AnDB automates query processing by generating multiple execution plans and selecting the optimal one through its optimizer, which balances accuracy, execution time, and financial cost based on user policies and internal optimizing mechanisms. AnDB future-proofs data management infrastructure, empowering users to effectively and efficiently harness the full potential of all kinds of data without starting from scratch.