 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODA-BENCH: Can Code Agents Handle Data-Intensive Tasks?
Jun 13, 2026Advanced agents are increasingly demonstrating the potential to operate as autonomous engineers, creating a growing demand for evaluation benchmarks that capture the complexity of real-world development. Such environments typically involve both complex code and large-scale data (i.e., file system). However, existing benchmarks usually evaluate code-centric or data-centric capabilities in isolation, leaving a clear gap with real development scenarios. In this paper, we bridge this gap by introducing CODA-BENCH, the first benchmark to jointly evaluate code and data intelligence in a data-intensive environment. We construct a data-intensive Linux sandbox based on the Kaggle ecosystem (containing hundreds of datasets), where agents must actively explore complex file hierarchies to identify relevant resources and generate code for data-driven analytical tasks. CODA-BENCH comprises 1,009 tasks spanning 31 communities, with each task environment containing an average of 980 files, simulating realistic data scale and noise. Evaluations of advanced agents reveal that even top-performing systems struggle to effectively integrate data discovery with code execution, achieving a success rate of only 61.1%. These results highlight a substantial gap in current agentic capabilities for data-intensive tasks and point to promising directions for future research.
DataEvolver: Automatic Data Preparation for Large Language Models through Multi-Level Self-Evolving
Jun 05, 2026High-quality training data is essential to large language models (LLMs) and typically requires extensive and costly manual curation. Existing automatic data preparation methods rely on predefined pipelines or customized human instructions, which limits their adaptability to diverse data distributions and lacks principled guidance from high-quality examples. In this paper, we introduce DataEvolver, the first self-evolving data preparation system that automatically constructs pipelines to transform raw data into high-quality data. DataEvolver employs a multi-level mechanism to ensure both pipeline executability and effectiveness. At the operator level, it incrementally expands the operator set to construct a logical plan while resolving dependency conflicts. At the pipeline level, it instantiates logical plans into executable code and iteratively refines pipeline orchestration through a feedback loop that reduces the distribution gap between prepared data and high-quality examples. Experiments on seven benchmarks show that DataEvolver substantially improves data quality and achieves an average 10\% gain in downstream LLM performance compared with training on original data, highlighting new opportunities for the iterative co-evolution of LLMs and data.
TANDEM: Bi-Level Data Mixture Optimization with Twin Networks
Jun 03, 2026The capabilities of large language models (LLMs) significantly depend on training data drawn from various domains. Optimizing domain-specific mixture ratios can be modeled as a bi-level optimization problem, which we simplify into a single-level penalized form and solve with twin networks: a proxy model trained on primary data and a dynamically updated reference model trained with additional data. Our proposed method, Twin Networks for bi-level DatA mixturE optiMization (TANDEM), measures the data efficacy through the difference between the twin models and up-weights domains that benefit more from the additional data. TANDEM provides theoretical guarantees and wider applicability, compared to prior approaches. Furthermore, our bi-level perspective suggests new settings to study domain reweighting such as data-restricted scenarios and supervised fine-tuning, where optimized mixture ratios significantly improve the performance. Extensive experiments validate TANDEM's effectiveness in all scenarios.
Fragile Reconstruction: Adversarial Vulnerability of Reconstruction-Based Detectors for Diffusion-Generated Images
Apr 14, 2026Recently, detecting AI-generated images produced by diffusion-based models has attracted increasing attention due to their potential threat to safety. Among existing approaches, reconstruction-based methods have emerged as a prominent paradigm for this task. However, we find that such methods exhibit severe security vulnerabilities to adversarial perturbations; that is, by adding imperceptible adversarial perturbations to input images, the detection accuracy of classifiers collapses to near zero. To verify this threat, we present a systematic evaluation of the adversarial robustness of three representative detectors across four diverse generative backbone models. First, we construct adversarial attacks in white-box scenarios, which degrade the performance of all well-trained detectors. Moreover, we find that these attacks demonstrate transferability; specifically, attacks crafted against one detector can be transferred to others, indicating that adversarial attacks on detectors can also be constructed in a black-box setting. Finally, we assess common countermeasures and find that standard defense methods against adversarial attacks provide limited mitigation. We attribute these failures to the low signal-to-noise ratio (SNR) of attacked samples as perceived by the detectors. Overall, our results reveal fundamental security limitations of reconstruction-based detectors and highlight the need to rethink existing detection strategies.
OFA-Diffusion Compression: Compressing Diffusion Model in One-Shot Manner
Apr 14, 2026The Diffusion Probabilistic Model (DPM) achieves remarkable performance in image generation, while its increasing parameter size and computational overhead hinder its deployment in practical applications. To improve this, the existing literature focuses on obtaining a smaller model with a fixed architecture through model compression. However, in practice, DPMs usually need to be deployed on various devices with different resource constraints, which leads to multiple compression processes, incurring significant overhead for repeated training. To obviate this, we propose a once-for-all (OFA) compression framework for DPMs that yields different subnetworks with various computations in a one-shot training manner. The existing OFA framework typically involves massive subnetworks with different parameter sizes, while such a huge candidate space slows the optimization. Thus, we propose to restrict the candidate subnetworks with a certain set of parameter sizes, where each size corresponds to a specific subnetwork. Specifically, to construct each subnetwork with a given size, we gradually allocate the maintained channels by their importance. Furthermore, we propose a reweighting strategy to balance the optimization process of different subnetworks. Experimental results show that our approach can produce compressed DPMs for various sizes with significantly lower training overhead while achieving satisfactory performance.
Reasoning and Tool-use Compete in Agentic RL:From Quantifying Interference to Disentangled Tuning
Feb 01, 2026Agentic Reinforcement Learning (ARL) focuses on training large language models (LLMs) to interleave reasoning with external tool execution to solve complex tasks. Most existing ARL methods train a single shared model parameters to support both reasoning and tool use behaviors, implicitly assuming that joint training leads to improved overall agent performance. Despite its widespread adoption, this assumption has rarely been examined empirically. In this paper, we systematically investigate this assumption by introducing a Linear Effect Attribution System(LEAS), which provides quantitative evidence of interference between reasoning and tool-use behaviors. Through an in-depth analysis, we show that these two capabilities often induce misaligned gradient directions, leading to training interference that undermines the effectiveness of joint optimization and challenges the prevailing ARL paradigm. To address this issue, we propose Disentangled Action Reasoning Tuning(DART), a simple and efficient framework that explicitly decouples parameter updates for reasoning and tool-use via separate low-rank adaptation modules. Experimental results show that DART consistently outperforms baseline methods with averaged 6.35 percent improvements and achieves performance comparable to multi-agent systems that explicitly separate tool-use and reasoning using a single model.
ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment
Jan 29, 2026Reinforcement Learning (RL) post-training alignment for language models is effective, but also costly and unstable in practice, owing to its complicated training process. To address this, we propose a training-free inference method to sample directly from the optimal RL policy. The transition probability applied to Masked Language Modeling (MLM) consists of a reference policy model and an energy term. Based on this, our algorithm, Energy-Guided Test-Time Scaling (ETS), estimates the key energy term via online Monte Carlo, with a provable convergence rate. Moreover, to ensure practical efficiency, ETS leverages modern acceleration frameworks alongside tailored importance sampling estimators, substantially reducing inference latency while provably preserving sampling quality. Experiments on MLM (including autoregressive models and diffusion language models) across reasoning, coding, and science benchmarks show that our ETS consistently improves generation quality, validating its effectiveness and design.
TAIJI: MCP-based Multi-Modal Data Analytics on Data Lakes
May 16, 2025The variety of data in data lakes presents significant challenges for data analytics, as data scientists must simultaneously analyze multi-modal data, including structured, semi-structured, and unstructured data. While Large Language Models (LLMs) have demonstrated promising capabilities, they still remain inadequate for multi-modal data analytics in terms of accuracy, efficiency, and freshness. First, current natural language (NL) or SQL-like query languages may struggle to precisely and comprehensively capture users' analytical intent. Second, relying on a single unified LLM to process diverse data modalities often leads to substantial inference overhead. Third, data stored in data lakes may be incomplete or outdated, making it essential to integrate external open-domain knowledge to generate timely and relevant analytics results. In this paper, we envision a new multi-modal data analytics system. Specifically, we propose a novel architecture built upon the Model Context Protocol (MCP), an emerging paradigm that enables LLMs to collaborate with knowledgeable agents. First, we define a semantic operator hierarchy tailored for querying multi-modal data in data lakes and develop an AI-agent-powered NL2Operator translator to bridge user intent and analytical execution. Next, we introduce an MCP-based execution framework, in which each MCP server hosts specialized foundation models optimized for specific data modalities. This design enhances both accuracy and efficiency, while supporting high scalability through modular deployment. Finally, we propose a updating mechanism by harnessing the deep research and machine unlearning techniques to refresh the data lakes and LLM knowledges, with the goal of balancing the data freshness and inference efficiency.
Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards
May 07, 2025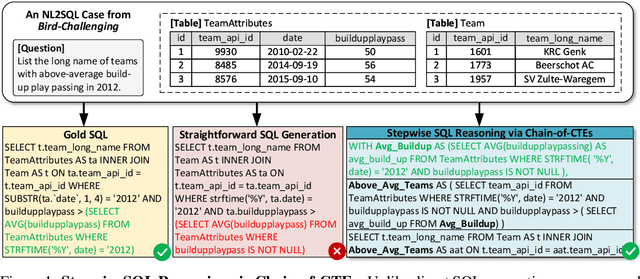
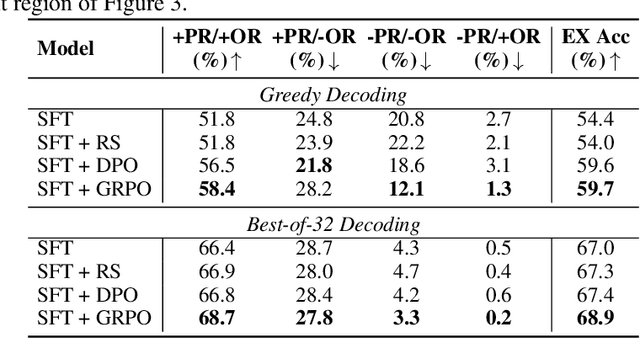
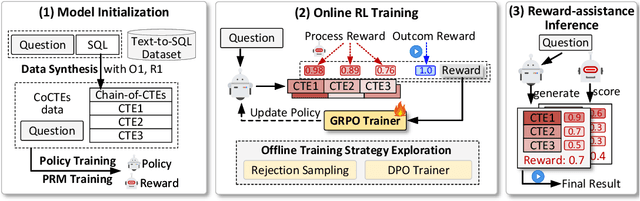
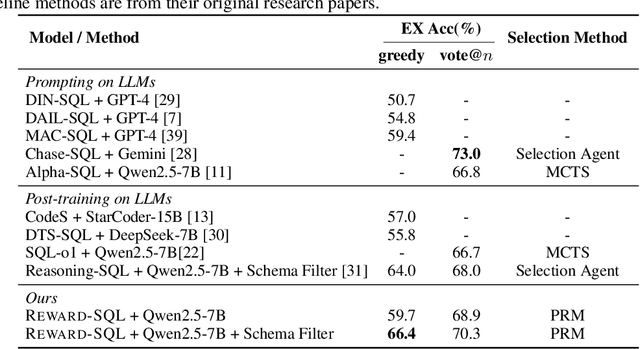
Recent advances in large language models (LLMs) have significantly improved performance on the Text-to-SQL task by leveraging their powerful reasoning capabilities. To enhance accuracy during the reasoning process, external Process Reward Models (PRMs) can be introduced during training and inference to provide fine-grained supervision. However, if misused, PRMs may distort the reasoning trajectory and lead to suboptimal or incorrect SQL generation.To address this challenge, we propose Reward-SQL, a framework that systematically explores how to incorporate PRMs into the Text-to-SQL reasoning process effectively. Our approach follows a "cold start, then PRM supervision" paradigm. Specifically, we first train the model to decompose SQL queries into structured stepwise reasoning chains using common table expressions (Chain-of-CTEs), establishing a strong and interpretable reasoning baseline. Then, we investigate four strategies for integrating PRMs, and find that combining PRM as an online training signal (GRPO) with PRM-guided inference (e.g., best-of-N sampling) yields the best results. Empirically, on the BIRD benchmark, Reward-SQL enables models supervised by a 7B PRM to achieve a 13.1% performance gain across various guidance strategies. Notably, our GRPO-aligned policy model based on Qwen2.5-Coder-7B-Instruct achieves 68.9% accuracy on the BIRD development set, outperforming all baseline methods under the same model size. These results demonstrate the effectiveness of Reward-SQL in leveraging reward-based supervision for Text-to-SQL reasoning. Our code is publicly available.
AutoPrep: Natural Language Question-Aware Data Preparation with a Multi-Agent Framework
Dec 10, 2024Answering natural language (NL) questions about tables, which is referred to as Tabular Question Answering (TQA), is important because it enables users to extract meaningful insights quickly and efficiently from structured data, bridging the gap between human language and machine-readable formats. Many of these tables originate from web sources or real-world scenarios, necessitating careful data preparation (or data prep for short) to ensure accurate answers. However, unlike traditional data prep, question-aware data prep introduces new requirements, which include tasks such as column augmentation and filtering for given questions, and question-aware value normalization or conversion. Because each of the above tasks is unique, a single model (or agent) may not perform effectively across all scenarios. In this paper, we propose AUTOPREP, a large language model (LLM)-based multi-agent framework that leverages the strengths of multiple agents, each specialized in a certain type of data prep, ensuring more accurate and contextually relevant responses. Given an NL question over a table, AUTOPREP performs data prep through three key components. Planner: Determines a logical plan, outlining a sequence of high-level operations. Programmer: Translates this logical plan into a physical plan by generating the corresponding low-level code. Executor: Iteratively executes and debugs the generated code to ensure correct outcomes. To support this multi-agent framework, we design a novel chain-of-thought reasoning mechanism for high-level operation suggestion, and a tool-augmented method for low-level code generation. Extensive experiments on real-world TQA datasets demonstrate that AUTOPREP can significantly improve the SOTA TQA solutions through question-aware data prep.