 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Need an Encoder for Native Position-Independent Caching
Feb 02, 2026The Key-Value (KV) cache of Large Language Models (LLMs) is prefix-based, making it highly inefficient for processing contexts retrieved in arbitrary order. Position-Independent Caching (PIC) has been proposed to enable KV reuse without positional constraints; however, existing approaches often incur substantial accuracy degradation, limiting their practical adoption. To address this issue, we propose native PIC by reintroducing the encoder to prevalent decoder-only LLMs and explicitly training it to support PIC. We further develop COMB, a PIC-aware caching system that integrates seamlessly with existing inference frameworks. Experimental results show that COMB reduces Time-to-First-Token (TTFT) by 51-94% and increases throughput by 3$\times$ with comparable accuracy. Furthermore, the quality improvement when using DeepSeek-V2-Lite-Chat demonstrates the applicability of COMB to other types of decoder-only LLMs. Our code is available at https://github.com/shijuzhao/Comb.
Guiding the Recommender: Information-Aware Auto-Bidding for Content Promotion
Jan 28, 2026Modern content platforms offer paid promotion to mitigate cold start by allocating exposure via auctions. Our empirical analysis reveals a counterintuitive flaw in this paradigm: while promotion rescues low-to-medium quality content, it can harm high-quality content by forcing exposure to suboptimal audiences, polluting engagement signals and downgrading future recommendation. We recast content promotion as a dual-objective optimization that balances short-term value acquisition with long-term model improvement. To make this tractable at bid time in content promotion, we introduce a decomposable surrogate objective, gradient coverage, and establish its formal connection to Fisher Information and optimal experimental design. We design a two-stage auto-bidding algorithm based on Lagrange duality that dynamically paces budget through a shadow price and optimizes impression-level bids using per-impression marginal utilities. To address missing labels at bid time, we propose a confidence-gated gradient heuristic, paired with a zeroth-order variant for black-box models that reliably estimates learning signals in real time. We provide theoretical guarantees, proving monotone submodularity of the composite objective, sublinear regret in online auction, and budget feasibility. Extensive offline experiments on synthetic and real-world datasets validate the framework: it outperforms baselines, achieves superior final AUC/LogLoss, adheres closely to budget targets, and remains effective when gradients are approximated zeroth-order. These results show that strategic, information-aware promotion can improve long-term model performance and organic outcomes beyond naive impression-maximization strategies.
OrchANN: A Unified I/O Orchestration Framework for Skewed Out-of-Core Vector Search
Dec 28, 2025Approximate nearest neighbor search (ANNS) at billion scale is fundamentally an out-of-core problem: vectors and indexes live on SSD, so performance is dominated by I/O rather than compute. Under skewed semantic embeddings, existing out-of-core systems break down: a uniform local index mismatches cluster scales, static routing misguides queries and inflates the number of probed partitions, and pruning is incomplete at the cluster level and lossy at the vector level, triggering "fetch-to-discard" reranking on raw vectors. We present OrchANN, an out-of-core ANNS engine that uses an I/O orchestration model for unified I/O governance along the route-access-verify pipeline. OrchANN selects a heterogeneous local index per cluster via offline auto-profiling, maintains a query-aware in-memory navigation graph that adapts to skewed workloads, and applies multi-level pruning with geometric bounds to filter both clusters and vectors before issuing SSD reads. Across five standard datasets under strict out-of-core constraints, OrchANN outperforms four baselines including DiskANN, Starling, SPANN, and PipeANN in both QPS and latency while reducing SSD accesses. Furthermore, OrchANN delivers up to 17.2x higher QPS and 25.0x lower latency than competing systems without sacrificing accuracy.
PAF-Net: Phase-Aligned Frequency Decoupling Network for Multi-Process Manufacturing Quality Prediction
Jul 30, 2025



Accurate quality prediction in multi-process manufacturing is critical for industrial efficiency but hindered by three core challenges: time-lagged process interactions, overlapping operations with mixed periodicity, and inter-process dependencies in shared frequency bands. To address these, we propose PAF-Net, a frequency decoupled time series prediction framework with three key innovations: (1) A phase-correlation alignment method guided by frequency domain energy to synchronize time-lagged quality series, resolving temporal misalignment. (2) A frequency independent patch attention mechanism paired with Discrete Cosine Transform (DCT) decomposition to capture heterogeneous operational features within individual series. (3) A frequency decoupled cross attention module that suppresses noise from irrelevant frequencies, focusing exclusively on meaningful dependencies within shared bands. Experiments on 4 real-world datasets demonstrate PAF-Net's superiority. It outperforms 10 well-acknowledged baselines by 7.06% lower MSE and 3.88% lower MAE. Our code is available at https://github.com/StevenLuan904/PAF-Net-Official.
Pre$^3$: Enabling Deterministic Pushdown Automata for Faster Structured LLM Generation
Jun 04, 2025Extensive LLM applications demand efficient structured generations, particularly for LR(1) grammars, to produce outputs in specified formats (e.g., JSON). Existing methods primarily parse LR(1) grammars into a pushdown automaton (PDA), leading to runtime execution overhead for context-dependent token processing, especially inefficient under large inference batches. To address these issues, we propose Pre$^3$ that exploits deterministic pushdown automata (DPDA) to optimize the constrained LLM decoding efficiency. First, by precomputing prefix-conditioned edges during the preprocessing, Pre$^3$ enables ahead-of-time edge analysis and thus makes parallel transition processing possible. Second, by leveraging the prefix-conditioned edges, Pre$^3$ introduces a novel approach that transforms LR(1) transition graphs into DPDA, eliminating the need for runtime path exploration and achieving edge transitions with minimal overhead. Pre$^3$ can be seamlessly integrated into standard LLM inference frameworks, reducing time per output token (TPOT) by up to 40% and increasing throughput by up to 36% in our experiments. Our code is available at https://github.com/ModelTC/lightllm.
B2LoRa: Boosting LoRa Transmission for Satellite-IoT Systems with Blind Coherent Combining
May 30, 2025With the rapid growth of Low Earth Orbit (LEO) satellite networks, satellite-IoT systems using the LoRa technique have been increasingly deployed to provide widespread Internet services to low-power and low-cost ground devices. However, the long transmission distance and adverse environments from IoT satellites to ground devices pose a huge challenge to link reliability, as evidenced by the measurement results based on our real-world setup. In this paper, we propose a blind coherent combining design named B2LoRa to boost LoRa transmission performance. The intuition behind B2LoRa is to leverage the repeated broadcasting mechanism inherent in satellite-IoT systems to achieve coherent combining under the low-power and low-cost constraints, where each re-transmission at different times is regarded as the same packet transmitted from different antenna elements within an antenna array. Then, the problem is translated into aligning these packets at a fine granularity despite the time, frequency, and phase offsets between packets in the case of frequent packet loss. To overcome this challenge, we present three designs - joint packet sniffing, frequency shift alignment, and phase drift mitigation to deal with ultra-low SNRs and Doppler shifts featured in satellite-IoT systems, respectively. Finally, experiment results based on our real-world deployments demonstrate the high efficiency of B2LoRa.
Query Routing for Retrieval-Augmented Language Models
May 29, 2025Retrieval-Augmented Generation (RAG) significantly improves the performance of Large Language Models (LLMs) on knowledge-intensive tasks. However, varying response quality across LLMs under RAG necessitates intelligent routing mechanisms, which select the most suitable model for each query from multiple retrieval-augmented LLMs via a dedicated router model. We observe that external documents dynamically affect LLMs' ability to answer queries, while existing routing methods, which rely on static parametric knowledge representations, exhibit suboptimal performance in RAG scenarios. To address this, we formally define the new retrieval-augmented LLM routing problem, incorporating the influence of retrieved documents into the routing framework. We propose RAGRouter, a RAG-aware routing design, which leverages document embeddings and RAG capability embeddings with contrastive learning to capture knowledge representation shifts and enable informed routing decisions. Extensive experiments on diverse knowledge-intensive tasks and retrieval settings show that RAGRouter outperforms the best individual LLM by 3.61% on average and existing routing methods by 3.29%-9.33%. With an extended score-threshold-based mechanism, it also achieves strong performance-efficiency trade-offs under low-latency constraints.
Automated Privacy Information Annotation in Large Language Model Interactions
May 27, 2025Users interacting with large language models (LLMs) under their real identifiers often unknowingly risk disclosing private information. Automatically notifying users whether their queries leak privacy and which phrases leak what private information has therefore become a practical need. Existing privacy detection methods, however, were designed for different objectives and application scenarios, typically tagging personally identifiable information (PII) in anonymous content. In this work, to support the development and evaluation of privacy detection models for LLM interactions that are deployable on local user devices, we construct a large-scale multilingual dataset with 249K user queries and 154K annotated privacy phrases. In particular, we build an automated privacy annotation pipeline with cloud-based strong LLMs to automatically extract privacy phrases from dialogue datasets and annotate leaked information. We also design evaluation metrics at the levels of privacy leakage, extracted privacy phrase, and privacy information. We further establish baseline methods using light-weight LLMs with both tuning-free and tuning-based methods, and report a comprehensive evaluation of their performance. Evaluation results reveal a gap between current performance and the requirements of real-world LLM applications, motivating future research into more effective local privacy detection methods grounded in our dataset.
DVD-Quant: Data-free Video Diffusion Transformers Quantization
May 24, 2025Diffusion Transformers (DiTs) have emerged as the state-of-the-art architecture for video generation, yet their computational and memory demands hinder practical deployment. While post-training quantization (PTQ) presents a promising approach to accelerate Video DiT models, existing methods suffer from two critical limitations: (1) dependence on lengthy, computation-heavy calibration procedures, and (2) considerable performance deterioration after quantization. To address these challenges, we propose DVD-Quant, a novel Data-free quantization framework for Video DiTs. Our approach integrates three key innovations: (1) Progressive Bounded Quantization (PBQ) and (2) Auto-scaling Rotated Quantization (ARQ) for calibration data-free quantization error reduction, as well as (3) $\delta$-Guided Bit Switching ($\delta$-GBS) for adaptive bit-width allocation. Extensive experiments across multiple video generation benchmarks demonstrate that DVD-Quant achieves an approximately 2$\times$ speedup over full-precision baselines on HunyuanVideo while maintaining visual fidelity. Notably, DVD-Quant is the first to enable W4A4 PTQ for Video DiTs without compromising video quality. Code and models will be available at https://github.com/lhxcs/DVD-Quant.
FlashForge: Ultra-Efficient Prefix-Aware Attention for LLM Decoding
May 23, 2025
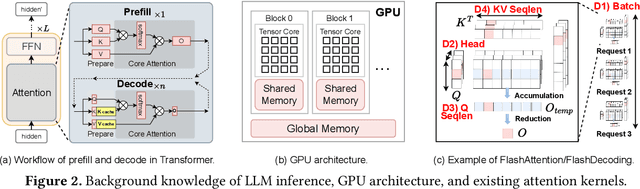

Prefix-sharing among multiple prompts presents opportunities to combine the operations of the shared prefix, while attention computation in the decode stage, which becomes a critical bottleneck with increasing context lengths, is a memory-intensive process requiring heavy memory access on the key-value (KV) cache of the prefixes. Therefore, in this paper, we explore the potential of prefix-sharing in the attention computation of the decode stage. However, the tree structure of the prefix-sharing mechanism presents significant challenges for attention computation in efficiently processing shared KV cache access patterns while managing complex dependencies and balancing irregular workloads. To address the above challenges, we propose a dedicated attention kernel to combine the memory access of shared prefixes in the decoding stage, namely FlashForge. FlashForge delivers two key innovations: a novel shared-prefix attention kernel that optimizes memory hierarchy and exploits both intra-block and inter-block parallelism, and a comprehensive workload balancing mechanism that efficiently estimates cost, divides tasks, and schedules execution. Experimental results show that FlashForge achieves an average 1.9x speedup and 120.9x memory access reduction compared to the state-of-the-art FlashDecoding kernel regarding attention computation in the decode stage and 3.8x end-to-end time per output token compared to the vLLM.