 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
May 12, 2026Recent large vision-language models (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
Focus-dLLM: Accelerating Long-Context Diffusion LLM Inference via Confidence-Guided Context Focusing
Feb 02, 2026Diffusion Large Language Models (dLLMs) deliver strong long-context processing capability in a non-autoregressive decoding paradigm. However, the considerable computational cost of bidirectional full attention limits the inference efficiency. Although sparse attention is promising, existing methods remain ineffective. This stems from the need to estimate attention importance for tokens yet to be decoded, while the unmasked token positions are unknown during diffusion. In this paper, we present Focus-dLLM, a novel training-free attention sparsification framework tailored for accurate and efficient long-context dLLM inference. Based on the finding that token confidence strongly correlates across adjacent steps, we first design a past confidence-guided indicator to predict unmasked regions. Built upon this, we propose a sink-aware pruning strategy to accurately estimate and remove redundant attention computation, while preserving highly influential attention sinks. To further reduce overhead, this strategy reuses identified sink locations across layers, leveraging the observed cross-layer consistency. Experimental results show that our method offers more than $29\times$ lossless speedup under $32K$ context length. The code is publicly available at: https://github.com/Longxmas/Focus-dLLM
Pre$^3$: Enabling Deterministic Pushdown Automata for Faster Structured LLM Generation
Jun 04, 2025Extensive LLM applications demand efficient structured generations, particularly for LR(1) grammars, to produce outputs in specified formats (e.g., JSON). Existing methods primarily parse LR(1) grammars into a pushdown automaton (PDA), leading to runtime execution overhead for context-dependent token processing, especially inefficient under large inference batches. To address these issues, we propose Pre$^3$ that exploits deterministic pushdown automata (DPDA) to optimize the constrained LLM decoding efficiency. First, by precomputing prefix-conditioned edges during the preprocessing, Pre$^3$ enables ahead-of-time edge analysis and thus makes parallel transition processing possible. Second, by leveraging the prefix-conditioned edges, Pre$^3$ introduces a novel approach that transforms LR(1) transition graphs into DPDA, eliminating the need for runtime path exploration and achieving edge transitions with minimal overhead. Pre$^3$ can be seamlessly integrated into standard LLM inference frameworks, reducing time per output token (TPOT) by up to 40% and increasing throughput by up to 36% in our experiments. Our code is available at https://github.com/ModelTC/lightllm.
Lossy and Lossless Post-training Model Size Compression
Aug 08, 2023



Deep neural networks have delivered remarkable performance and have been widely used in various visual tasks. However, their huge size causes significant inconvenience for transmission and storage. Many previous studies have explored model size compression. However, these studies often approach various lossy and lossless compression methods in isolation, leading to challenges in achieving high compression ratios efficiently. This work proposes a post-training model size compression method that combines lossy and lossless compression in a unified way. We first propose a unified parametric weight transformation, which ensures different lossy compression methods can be performed jointly in a post-training manner. Then, a dedicated differentiable counter is introduced to guide the optimization of lossy compression to arrive at a more suitable point for later lossless compression. Additionally, our method can easily control a desired global compression ratio and allocate adaptive ratios for different layers. Finally, our method can achieve a stable $10\times$ compression ratio without sacrificing accuracy and a $20\times$ compression ratio with minor accuracy loss in a short time. Our code is available at https://github.com/ModelTC/L2_Compression .
Hierarchical Rule Induction Network for Abstract Visual Reasoning
Feb 17, 2020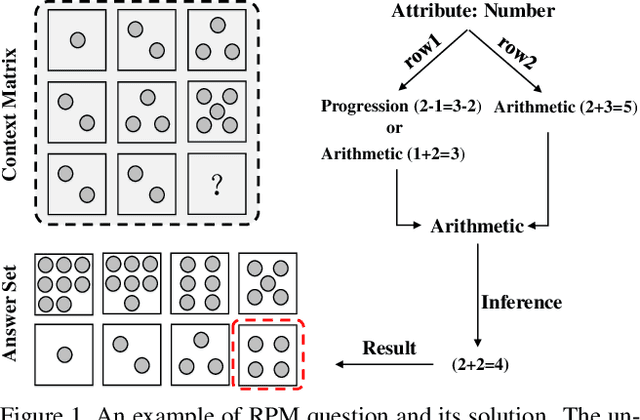
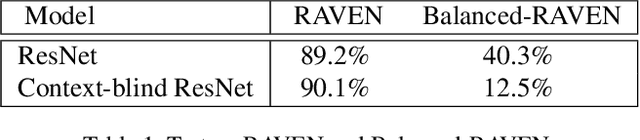
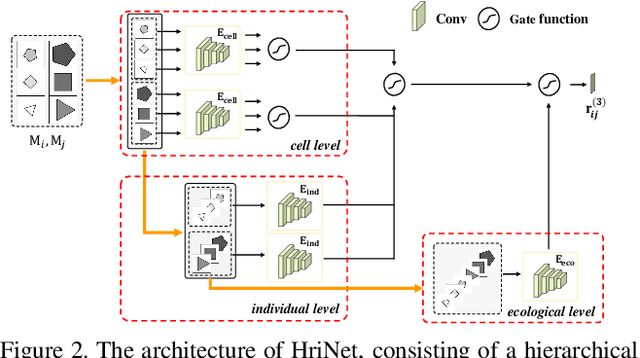

Abstract reasoning refers to the ability to analyze information, discover rules at an intangible level, and solve problems in innovative ways. Raven's Progressive Matrices (RPM) test is typically used to examine the capability of abstract reasoning. In the test, the subject is asked to identify the correct choice from the answer set to fill the missing panel at the bottom right of RPM (e.g., a 3$\times$3 matrix), following the underlying rules inside the matrix. Recent studies, taking advantage of Convolutional Neural Networks (CNNs), have achieved encouraging progress to accomplish the RPM test problems. Unfortunately, simply relying on the relation extraction at the matrix level, they fail to recognize the complex attribute patterns inside or across rows/columns of RPM. To address this problem, in this paper we propose a Hierarchical Rule Induction Network (HriNet), by intimating human induction strategies. HriNet extracts multiple granularity rule embeddings at different levels and integrates them through a gated embedding fusion module. We further introduce a rule similarity metric based on the embeddings, so that HriNet can not only be trained using a tuplet loss but also infer the best answer according to the similarity score. To comprehensively evaluate HriNet, we first fix the defects contained in the very recent RAVEN dataset and generate a new one named Balanced-RAVEN. Then extensive experiments are conducted on the large-scale dataset PGM and our Balanced-RAVEN, the results of which show that HriNet outperforms the state-of-the-art models by a large margin.
Region-wise Generative Adversarial ImageInpainting for Large Missing Areas
Sep 27, 2019

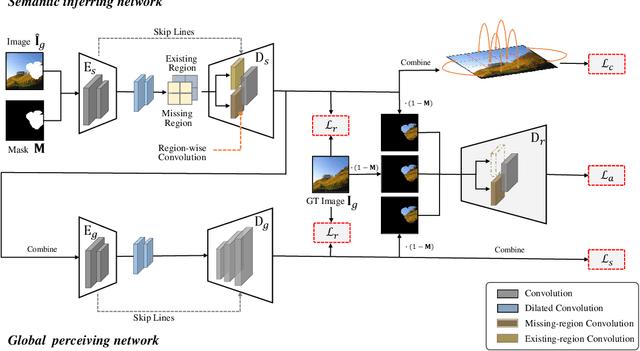
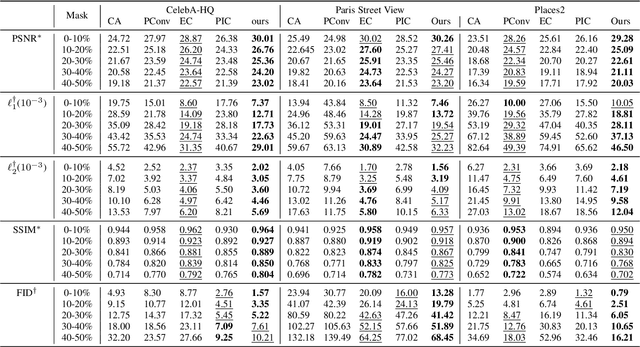
Recently deep neutral networks have achieved promising performance for filling large missing regions in image inpainting tasks. They usually adopted the standard convolutional architecture over the corrupted image, leading to meaningless contents, such as color discrepancy, blur and artifacts. Moreover, most inpainting approaches cannot well handle the large continuous missing area cases. To address these problems, we propose a generic inpainting framework capable of handling with incomplete images on both continuous and discontinuous large missing areas, in an adversarial manner. From which, region-wise convolution is deployed in both generator and discriminator to separately handle with the different regions, namely existing regions and missing ones. Moreover, a correlation loss is introduced to capture the non-local correlations between different patches, and thus guides the generator to obtain more information during inference. With the help of our proposed framework, we can restore semantically reasonable and visually realistic images. Extensive experiments on three widely-used datasets for image inpainting tasks have been conducted, and both qualitative and quantitative experimental results demonstrate that the proposed model significantly outperforms the state-of-the-art approaches, both on the large continuous and discontinuous missing areas.