 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Step Distillation for Text-to-Image Generation: A Practical Guide
Dec 15, 2025Diffusion distillation has dramatically accelerated class-conditional image synthesis, but its applicability to open-ended text-to-image (T2I) generation is still unclear. We present the first systematic study that adapts and compares state-of-the-art distillation techniques on a strong T2I teacher model, FLUX.1-lite. By casting existing methods into a unified framework, we identify the key obstacles that arise when moving from discrete class labels to free-form language prompts. Beyond a thorough methodological analysis, we offer practical guidelines on input scaling, network architecture, and hyperparameters, accompanied by an open-source implementation and pretrained student models. Our findings establish a solid foundation for deploying fast, high-fidelity, and resource-efficient diffusion generators in real-world T2I applications. Code is available on github.com/alibaba-damo-academy/T2I-Distill.
UltraDP: Generalizable Carotid Ultrasound Scanning with Force-Aware Diffusion Policy
Nov 19, 2025



Ultrasound scanning is a critical imaging technique for real-time, non-invasive diagnostics. However, variations in patient anatomy and complex human-in-the-loop interactions pose significant challenges for autonomous robotic scanning. Existing ultrasound scanning robots are commonly limited to relatively low generalization and inefficient data utilization. To overcome these limitations, we present UltraDP, a Diffusion-Policy-based method that receives multi-sensory inputs (ultrasound images, wrist camera images, contact wrench, and probe pose) and generates actions that are fit for multi-modal action distributions in autonomous ultrasound scanning of carotid artery. We propose a specialized guidance module to enable the policy to output actions that center the artery in ultrasound images. To ensure stable contact and safe interaction between the robot and the human subject, a hybrid force-impedance controller is utilized to drive the robot to track such trajectories. Also, we have built a large-scale training dataset for carotid scanning comprising 210 scans with 460k sample pairs from 21 volunteers of both genders. By exploring our guidance module and DP's strong generalization ability, UltraDP achieves a 95% success rate in transverse scanning on previously unseen subjects, demonstrating its effectiveness.
Step by Step Network
Nov 18, 2025Scaling up network depth is a fundamental pursuit in neural architecture design, as theory suggests that deeper models offer exponentially greater capability. Benefiting from the residual connections, modern neural networks can scale up to more than one hundred layers and enjoy wide success. However, as networks continue to deepen, current architectures often struggle to realize their theoretical capacity improvements, calling for more advanced designs to further unleash the potential of deeper networks. In this paper, we identify two key barriers that obstruct residual models from scaling deeper: shortcut degradation and limited width. Shortcut degradation hinders deep-layer learning, while the inherent depth-width trade-off imposes limited width. To mitigate these issues, we propose a generalized residual architecture dubbed Step by Step Network (StepsNet) to bridge the gap between theoretical potential and practical performance of deep models. Specifically, we separate features along the channel dimension and let the model learn progressively via stacking blocks with increasing width. The resulting method mitigates the two identified problems and serves as a versatile macro design applicable to various models. Extensive experiments show that our method consistently outperforms residual models across diverse tasks, including image classification, object detection, semantic segmentation, and language modeling. These results position StepsNet as a superior generalization of the widely adopted residual architecture.
SpatialActor: Exploring Disentangled Spatial Representations for Robust Robotic Manipulation
Nov 12, 2025Robotic manipulation requires precise spatial understanding to interact with objects in the real world. Point-based methods suffer from sparse sampling, leading to the loss of fine-grained semantics. Image-based methods typically feed RGB and depth into 2D backbones pre-trained on 3D auxiliary tasks, but their entangled semantics and geometry are sensitive to inherent depth noise in real-world that disrupts semantic understanding. Moreover, these methods focus on high-level geometry while overlooking low-level spatial cues essential for precise interaction. We propose SpatialActor, a disentangled framework for robust robotic manipulation that explicitly decouples semantics and geometry. The Semantic-guided Geometric Module adaptively fuses two complementary geometry from noisy depth and semantic-guided expert priors. Also, a Spatial Transformer leverages low-level spatial cues for accurate 2D-3D mapping and enables interaction among spatial features. We evaluate SpatialActor on multiple simulation and real-world scenarios across 50+ tasks. It achieves state-of-the-art performance with 87.4% on RLBench and improves by 13.9% to 19.4% under varying noisy conditions, showing strong robustness. Moreover, it significantly enhances few-shot generalization to new tasks and maintains robustness under various spatial perturbations. Project Page: https://shihao1895.github.io/SpatialActor
Are My Optimized Prompts Compromised? Exploring Vulnerabilities of LLM-based Optimizers
Oct 16, 2025


Large language model (LLM) systems now underpin everyday AI applications such as chatbots, computer-use assistants, and autonomous robots, where performance often depends on carefully designed prompts. LLM-based prompt optimizers reduce that effort by iteratively refining prompts from scored feedback, yet the security of this optimization stage remains underexamined. We present the first systematic analysis of poisoning risks in LLM-based prompt optimization. Using HarmBench, we find systems are substantially more vulnerable to manipulated feedback than to injected queries: feedback-based attacks raise attack success rate (ASR) by up to $\Delta$ASR = 0.48. We introduce a simple fake-reward attack that requires no access to the reward model and significantly increases vulnerability, and we propose a lightweight highlighting defense that reduces the fake-reward $\Delta$ASR from 0.23 to 0.07 without degrading utility. These results establish prompt optimization pipelines as a first-class attack surface and motivate stronger safeguards for feedback channels and optimization frameworks.
Emulating Human-like Adaptive Vision for Efficient and Flexible Machine Visual Perception
Sep 18, 2025Human vision is highly adaptive, efficiently sampling intricate environments by sequentially fixating on task-relevant regions. In contrast, prevailing machine vision models passively process entire scenes at once, resulting in excessive resource demands scaling with spatial-temporal input resolution and model size, yielding critical limitations impeding both future advancements and real-world application. Here we introduce AdaptiveNN, a general framework aiming to drive a paradigm shift from 'passive' to 'active, adaptive' vision models. AdaptiveNN formulates visual perception as a coarse-to-fine sequential decision-making process, progressively identifying and attending to regions pertinent to the task, incrementally combining information across fixations, and actively concluding observation when sufficient. We establish a theory integrating representation learning with self-rewarding reinforcement learning, enabling end-to-end training of the non-differentiable AdaptiveNN without additional supervision on fixation locations. We assess AdaptiveNN on 17 benchmarks spanning 9 tasks, including large-scale visual recognition, fine-grained discrimination, visual search, processing images from real driving and medical scenarios, language-driven embodied AI, and side-by-side comparisons with humans. AdaptiveNN achieves up to 28x inference cost reduction without sacrificing accuracy, flexibly adapts to varying task demands and resource budgets without retraining, and provides enhanced interpretability via its fixation patterns, demonstrating a promising avenue toward efficient, flexible, and interpretable computer vision. Furthermore, AdaptiveNN exhibits closely human-like perceptual behaviors in many cases, revealing its potential as a valuable tool for investigating visual cognition. Code is available at https://github.com/LeapLabTHU/AdaptiveNN.
UltraHiT: A Hierarchical Transformer Architecture for Generalizable Internal Carotid Artery Robotic Ultrasonography
Sep 17, 2025Carotid ultrasound is crucial for the assessment of cerebrovascular health, particularly the internal carotid artery (ICA). While previous research has explored automating carotid ultrasound, none has tackled the challenging ICA. This is primarily due to its deep location, tortuous course, and significant individual variations, which greatly increase scanning complexity. To address this, we propose a Hierarchical Transformer-based decision architecture, namely UltraHiT, that integrates high-level variation assessment with low-level action decision. Our motivation stems from conceptualizing individual vascular structures as morphological variations derived from a standard vascular model. The high-level module identifies variation and switches between two low-level modules: an adaptive corrector for variations, or a standard executor for normal cases. Specifically, both the high-level module and the adaptive corrector are implemented as causal transformers that generate predictions based on the historical scanning sequence. To ensure generalizability, we collected the first large-scale ICA scanning dataset comprising 164 trajectories and 72K samples from 28 subjects of both genders. Based on the above innovations, our approach achieves a 95% success rate in locating the ICA on unseen individuals, outperforming baselines and demonstrating its effectiveness. Our code will be released after acceptance.
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Aug 26, 2025



Temporal context is essential for robotic manipulation because such tasks are inherently non-Markovian, yet mainstream VLA models typically overlook it and struggle with long-horizon, temporally dependent tasks. Cognitive science suggests that humans rely on working memory to buffer short-lived representations for immediate control, while the hippocampal system preserves verbatim episodic details and semantic gist of past experience for long-term memory. Inspired by these mechanisms, we propose MemoryVLA, a Cognition-Memory-Action framework for long-horizon robotic manipulation. A pretrained VLM encodes the observation into perceptual and cognitive tokens that form working memory, while a Perceptual-Cognitive Memory Bank stores low-level details and high-level semantics consolidated from it. Working memory retrieves decision-relevant entries from the bank, adaptively fuses them with current tokens, and updates the bank by merging redundancies. Using these tokens, a memory-conditioned diffusion action expert yields temporally aware action sequences. We evaluate MemoryVLA on 150+ simulation and real-world tasks across three robots. On SimplerEnv-Bridge, Fractal, and LIBERO-5 suites, it achieves 71.9%, 72.7%, and 96.5% success rates, respectively, all outperforming state-of-the-art baselines CogACT and pi-0, with a notable +14.6 gain on Bridge. On 12 real-world tasks spanning general skills and long-horizon temporal dependencies, MemoryVLA achieves 84.0% success rate, with long-horizon tasks showing a +26 improvement over state-of-the-art baseline. Project Page: https://shihao1895.github.io/MemoryVLA
Video Perception Models for 3D Scene Synthesis
Jun 25, 2025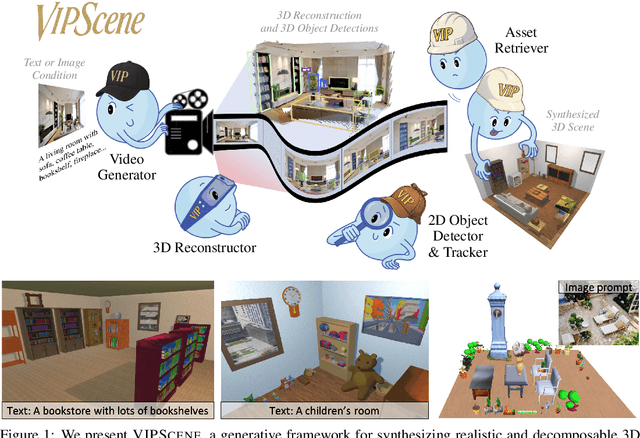



Traditionally, 3D scene synthesis requires expert knowledge and significant manual effort. Automating this process could greatly benefit fields such as architectural design, robotics simulation, virtual reality, and gaming. Recent approaches to 3D scene synthesis often rely on the commonsense reasoning of large language models (LLMs) or strong visual priors of modern image generation models. However, current LLMs demonstrate limited 3D spatial reasoning ability, which restricts their ability to generate realistic and coherent 3D scenes. Meanwhile, image generation-based methods often suffer from constraints in viewpoint selection and multi-view inconsistencies. In this work, we present Video Perception models for 3D Scene synthesis (VIPScene), a novel framework that exploits the encoded commonsense knowledge of the 3D physical world in video generation models to ensure coherent scene layouts and consistent object placements across views. VIPScene accepts both text and image prompts and seamlessly integrates video generation, feedforward 3D reconstruction, and open-vocabulary perception models to semantically and geometrically analyze each object in a scene. This enables flexible scene synthesis with high realism and structural consistency. For more precise analysis, we further introduce First-Person View Score (FPVScore) for coherence and plausibility evaluation, utilizing continuous first-person perspective to capitalize on the reasoning ability of multimodal large language models. Extensive experiments show that VIPScene significantly outperforms existing methods and generalizes well across diverse scenarios. The code will be released.
DenseGrounding: Improving Dense Language-Vision Semantics for Ego-Centric 3D Visual Grounding
May 08, 2025Enabling intelligent agents to comprehend and interact with 3D environments through natural language is crucial for advancing robotics and human-computer interaction. A fundamental task in this field is ego-centric 3D visual grounding, where agents locate target objects in real-world 3D spaces based on verbal descriptions. However, this task faces two significant challenges: (1) loss of fine-grained visual semantics due to sparse fusion of point clouds with ego-centric multi-view images, (2) limited textual semantic context due to arbitrary language descriptions. We propose DenseGrounding, a novel approach designed to address these issues by enhancing both visual and textual semantics. For visual features, we introduce the Hierarchical Scene Semantic Enhancer, which retains dense semantics by capturing fine-grained global scene features and facilitating cross-modal alignment. For text descriptions, we propose a Language Semantic Enhancer that leverages large language models to provide rich context and diverse language descriptions with additional context during model training. Extensive experiments show that DenseGrounding significantly outperforms existing methods in overall accuracy, with improvements of 5.81% and 7.56% when trained on the comprehensive full dataset and smaller mini subset, respectively, further advancing the SOTA in egocentric 3D visual grounding. Our method also achieves 1st place and receives the Innovation Award in the CVPR 2024 Autonomous Grand Challenge Multi-view 3D Visual Grounding Track, validating its effectiveness and robustness.