 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-RobotNav Technical Report: A Scalable Navigation Model Designed for an Agentic Navigation System
Jun 18, 2026Agentic navigation systems require a base navigation model whose observation strategy can be externally reconfigured at inference time, because instruction following, object search, target tracking, and autonomous driving share the same perception-planning backbone yet demand fundamentally different strategies for consuming the visual stream. We present Qwen-RobotNav, a scalable navigation model built on Qwen-RobotNav that addresses it through a parameterised interface with two complementary dimensions: multiple task modes that select the navigation behaviour, and controllable observation parameters (e.g., token budget, per-camera weights) that govern how visual history is encoded. With training-time randomization over all parameters, Qwen-RobotNav is robust to any inference-time configuration requiring zero architectural modification to the Qwen-RobotNav backbone. We train Qwen-RobotNav on 15.6M samples; co-training with vision-language data prevents the collapse into reactive action-sequence mappers observed in trajectory-only training. The parameterised interface also makes Qwen-RobotNav a natural building block for agentic systems: for long-horizon scenarios, an upper-level planner decomposes goals into sub-tasks and dynamically switches Qwen-RobotNav's task mode and context strategy mid-episode, composing complex behaviours from repeated calls to the same model. Extensive experiments show that Qwen-RobotNav sets new state-of-the-art results across major navigation benchmarks. The model exhibits favourable scaling from 2B to 8B parameters, with joint multi-task training developing a shared spatial-planning substrate that transfers across task families, and demonstrates strong zero-shot generalisation to real-world robots across diverse environments.
Qwen-RobotManip Technical Report: Alignment Unlocks Scale for Robotic Manipulation Foundation Models
Jun 17, 2026Foundation models in language and multimodality achieve strong generalization by aligning heterogeneous data under a unified formulation and training at scale. In this report, we investigate whether this scaling recipe can be applied to robotic manipulation to achieve genuine generalization. This is challenging because, unlike text, manipulation data is heterogeneous by nature, expensive to collect, and narrow in diversity, making alignment and scale simultaneously difficult. We present Qwen-RobotManip, a generalizable Vision-Language-Action foundation model built on Qwen-VL. Qwen-RobotManip introduces a unified alignment framework across the representation, motion, and behavioral dimensions of manipulation, making large-scale multi-source training coherent rather than conflicting. This alignment capability in turn enables Qwen-RobotManip to absorb manipulation data at a scale that prior training regimes could not sustain. A human-to-robot synthesis pipeline converts egocentric hand demonstrations into robot trajectories across 15 platforms, and a rigorous curation pipeline harmonizes heterogeneous datasets. Using only open-source datasets and human videos without proprietary data collection, Qwen-RobotManip constructs a ~38,100-hour pretraining corpus and exhibits emergent generalization capabilities, including zero-shot instruction following, robustness to perturbations, reactive error recovery, and cross-embodiment transfer. We find that standard benchmarks fail to capture pretraining quality and instead adopt OOD settings including RoboCasa365, LIBERO-Plus, EBench, RoboTwin-Clean2Rand, RoboTwin-IF, and RoboTwin-XE. Qwen-RobotManip substantially outperforms prior state-of-the-art models, including $π$0.5, across all OOD settings, ranks 1st in RoboChallenge with a 20% relative improvement, and is validated on real-robot platforms including AgileX ALOHA, Franka, UR, and ARX.
Qwen-RobotWorld Technical Report: Unifying Embodied World Modeling through Language-Conditioned Video Generation
Jun 17, 2026We introduce Qwen-RobotWorld, a language-conditioned video world model for embodied intelligence. With natural language as a unified action interface, it predicts physically grounded future visual trajectories from current observations across robotic manipulation, autonomous driving, indoor navigation, and human-to-robot transfer. This unified formulation provides three promising application directions: synthetic data generation for policy training augmentation, scalable virtual environments for policy evaluation, and language-guided planning signals for downstream robot control. This is achieved through a three-part design: a) Double-Stream MMDiT with MLLM Action Encoding, where a 60-layer double-stream diffusion transformer couples frozen Qwen2.5-VL semantics with video-VAE latents through layer-wise joint attention; b) Embodied World Knowledge (EWK), an 8.6M video-text corpus (200M+ frames) with action-language mapping over 20+ embodiments and 500+ action categories; and c) General+Expert Progressive Curriculum, a two-stage training strategy that first learns general visual priors and then injects embodied specialization under a shared language interface. Extensive results show strong competitiveness: ranks 1st overall on EWMBench and DreamGen Bench, outperforms all open-source models on WorldModelBench and PBench. Additional zero-shot analyses on RoboTwin-IF benchmark further support robust generalization and multi-view consistency.
ColaVLA: Leveraging Cognitive Latent Reasoning for Hierarchical Parallel Trajectory Planning in Autonomous Driving
Dec 31, 2025Autonomous driving requires generating safe and reliable trajectories from complex multimodal inputs. Traditional modular pipelines separate perception, prediction, and planning, while recent end-to-end (E2E) systems learn them jointly. Vision-language models (VLMs) further enrich this paradigm by introducing cross-modal priors and commonsense reasoning, yet current VLM-based planners face three key challenges: (i) a mismatch between discrete text reasoning and continuous control, (ii) high latency from autoregressive chain-of-thought decoding, and (iii) inefficient or non-causal planners that limit real-time deployment. We propose ColaVLA, a unified vision-language-action framework that transfers reasoning from text to a unified latent space and couples it with a hierarchical, parallel trajectory decoder. The Cognitive Latent Reasoner compresses scene understanding into compact, decision-oriented meta-action embeddings through ego-adaptive selection and only two VLM forward passes. The Hierarchical Parallel Planner then generates multi-scale, causality-consistent trajectories in a single forward pass. Together, these components preserve the generalization and interpretability of VLMs while enabling efficient, accurate and safe trajectory generation. Experiments on the nuScenes benchmark show that ColaVLA achieves state-of-the-art performance in both open-loop and closed-loop settings with favorable efficiency and robustness.
DenseGrounding: Improving Dense Language-Vision Semantics for Ego-Centric 3D Visual Grounding
May 08, 2025Enabling intelligent agents to comprehend and interact with 3D environments through natural language is crucial for advancing robotics and human-computer interaction. A fundamental task in this field is ego-centric 3D visual grounding, where agents locate target objects in real-world 3D spaces based on verbal descriptions. However, this task faces two significant challenges: (1) loss of fine-grained visual semantics due to sparse fusion of point clouds with ego-centric multi-view images, (2) limited textual semantic context due to arbitrary language descriptions. We propose DenseGrounding, a novel approach designed to address these issues by enhancing both visual and textual semantics. For visual features, we introduce the Hierarchical Scene Semantic Enhancer, which retains dense semantics by capturing fine-grained global scene features and facilitating cross-modal alignment. For text descriptions, we propose a Language Semantic Enhancer that leverages large language models to provide rich context and diverse language descriptions with additional context during model training. Extensive experiments show that DenseGrounding significantly outperforms existing methods in overall accuracy, with improvements of 5.81% and 7.56% when trained on the comprehensive full dataset and smaller mini subset, respectively, further advancing the SOTA in egocentric 3D visual grounding. Our method also achieves 1st place and receives the Innovation Award in the CVPR 2024 Autonomous Grand Challenge Multi-view 3D Visual Grounding Track, validating its effectiveness and robustness.
ProxyTransformation: Preshaping Point Cloud Manifold With Proxy Attention For 3D Visual Grounding
Feb 26, 2025Embodied intelligence requires agents to interact with 3D environments in real time based on language instructions. A foundational task in this domain is ego-centric 3D visual grounding. However, the point clouds rendered from RGB-D images retain a large amount of redundant background data and inherent noise, both of which can interfere with the manifold structure of the target regions. Existing point cloud enhancement methods often require a tedious process to improve the manifold, which is not suitable for real-time tasks. We propose Proxy Transformation suitable for multimodal task to efficiently improve the point cloud manifold. Our method first leverages Deformable Point Clustering to identify the point cloud sub-manifolds in target regions. Then, we propose a Proxy Attention module that utilizes multimodal proxies to guide point cloud transformation. Built upon Proxy Attention, we design a submanifold transformation generation module where textual information globally guides translation vectors for different submanifolds, optimizing relative spatial relationships of target regions. Simultaneously, image information guides linear transformations within each submanifold, refining the local point cloud manifold of target regions. Extensive experiments demonstrate that Proxy Transformation significantly outperforms all existing methods, achieving an impressive improvement of 7.49% on easy targets and 4.60% on hard targets, while reducing the computational overhead of attention blocks by 40.6%. These results establish a new SOTA in ego-centric 3D visual grounding, showcasing the effectiveness and robustness of our approach.
Maximum Likelihood CFO Estimation for High-Mobility OFDM Systems: A Chinese Remainder Theorem Based Method
Dec 27, 2023Orthogonal frequency division multiplexing (OFDM) is a widely adopted wireless communication technique but is sensitive to the carrier frequency offset (CFO). For high-mobility environments, severe Doppler shifts cause the CFO to extend well beyond the subcarrier spacing. Traditional algorithms generally estimate the integer and fractional parts of the CFO separately, which is time-consuming and requires high additional computations. To address these issues, this paper proposes a Chinese remainder theorem-based CFO Maximum Likelihood Estimation (CCMLE) approach for jointly estimating the integer and fractional parts. With CCMLE, the MLE of the CFO can be obtained directly from multiple estimates of sequences with varying lengths. This approach can achieve a wide estimation range up to the total number of subcarriers, without significant additional computations. Furthermore, we show that the CCMLE can approach the Cram$\acute{\text{e}}$r-Rao Bound (CRB), and give an analytic expression for the signal-to-noise ratio (SNR) threshold approaching the CRB, enabling an efficient waveform design. Accordingly, a parameter configuration guideline for the CCMLE is presented to achieve a better MSE performance and a lower SNR threshold. Finally, experiments show that our proposed method is highly consistent with the theoretical analysis and advantageous regarding estimated range and error performance compared to baselines.
Channel Capacity and Bounds In Mixed Gaussian-Impulsive Noise
Nov 15, 2023



Communication systems suffer from the mixed noise consisting of both non-Gaussian impulsive noise (IN) and white Gaussian noise (WGN) in many practical applications. However, there is little literature about the channel capacity under mixed noise. In this paper, we prove the existence of the capacity under p-th moment constraint and show that there are only finite mass points in the capacity-achieving distribution. Moreover, we provide lower and upper capacity bounds with closed forms. It is shown that the lower bounds can degenerate to the well-known Shannon formula under special scenarios. In addition, the capacity for specific modulations and the corresponding lower bounds are discussed. Numerical results reveal that the capacity decreases when the impulsiveness of the mixed noise becomes dominant and the obtained capacity bounds are shown to be very tight.
Knowledge Graph Based Waveform Recommendation: A New Communication Waveform Design Paradigm
Jan 24, 2022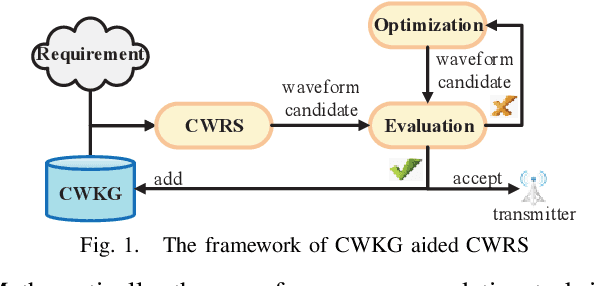
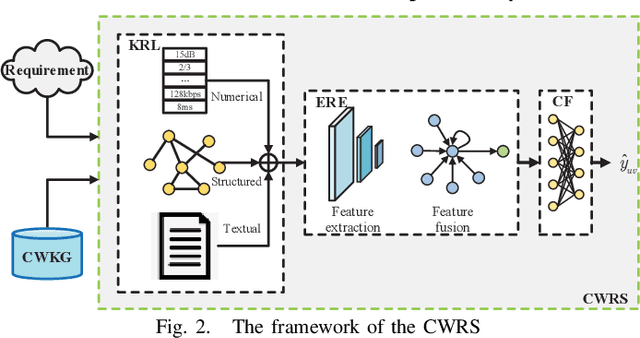
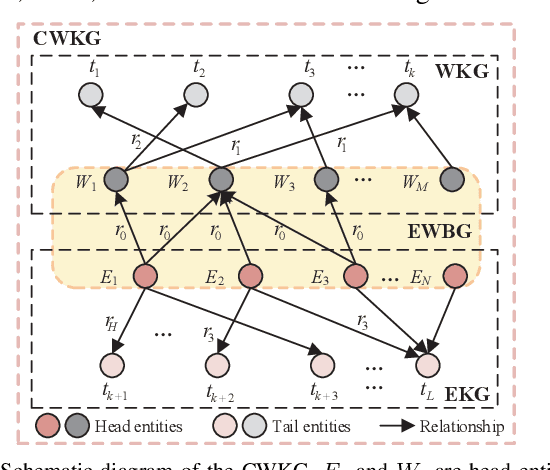
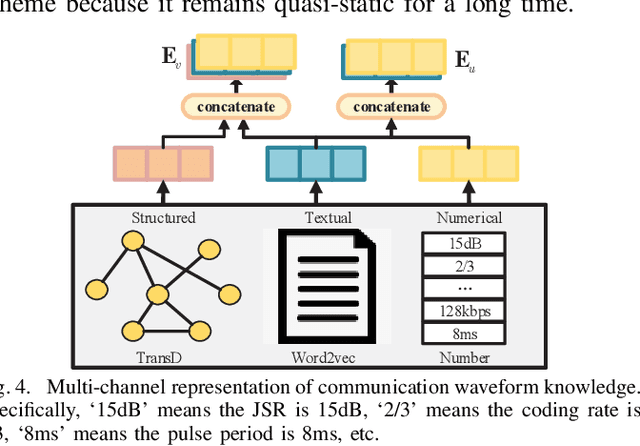
Traditionally, a communication waveform is designed by experts based on communication theory and their experiences on a case-by-case basis, which is usually laborious and time-consuming. In this paper, we investigate the waveform design from a novel perspective and propose a new waveform design paradigm with the knowledge graph (KG)-based intelligent recommendation system. The proposed paradigm aims to improve the design efficiency by structural characterization and representations of existing waveforms and intelligently utilizing the knowledge learned from them. To achieve this goal, we first build a communication waveform knowledge graph (CWKG) with a first-order neighbor node, for which both structured semantic knowledge and numerical parameters of a waveform are integrated by representation learning. Based on the developed CWKG, we further propose an intelligent communication waveform recommendation system (CWRS) to generate waveform candidates. In the CWRS, an improved involution1D operator, which is channel-agnostic and space-specific, is introduced according to the characteristics of KG-based waveform representation for feature extraction, and the multi-head self-attention is adopted to weigh the influence of various components for feature fusion. Meanwhile, multilayer perceptron-based collaborative filtering is used to evaluate the matching degree between the requirement and the waveform candidate. Simulation results show that the proposed CWKG-based CWRS can automatically recommend waveform candidates with high reliability.
A Neural Network Detector for Spectrum Sensing under Uncertainties
Aug 06, 2019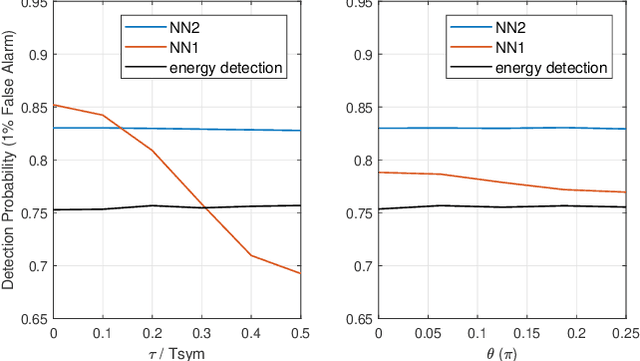
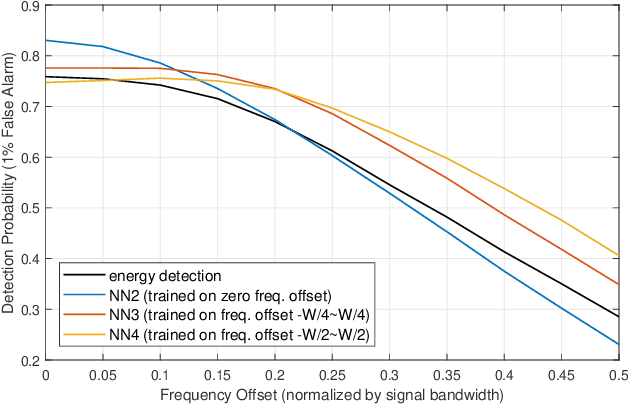
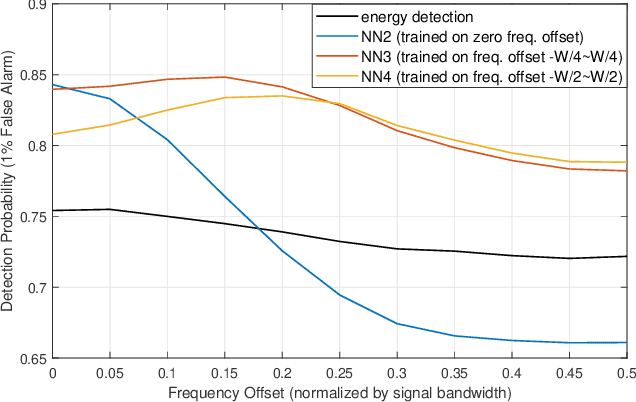
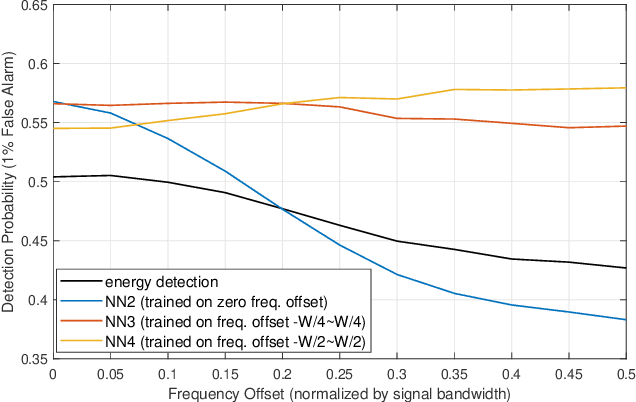
Spectrum sensing is of critical importance in any cognitive radio system. When the primary user's signal has uncertain parameters, the likelihood ratio test, which is the theoretically optimal detector, generally has no closed-form expression. As a result, spectrum sensing under parameter uncertainty remains an open question, though many detectors exploiting specific features of a primary signal have been proposed and have achieved reasonably good performance. In this paper, a neural network is trained as a detector for modulated signals. The result shows by training on an appropriate dataset, the neural network gains robustness under uncertainties in system parameters including the carrier frequency offset, carrier phase offset, and symbol time offset. The result displays the neural network's potential in exploiting implicit and incomplete knowledge about the signal's structure.