 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre My Optimized Prompts Compromised? Exploring Vulnerabilities of LLM-based Optimizers
Oct 16, 2025


Large language model (LLM) systems now underpin everyday AI applications such as chatbots, computer-use assistants, and autonomous robots, where performance often depends on carefully designed prompts. LLM-based prompt optimizers reduce that effort by iteratively refining prompts from scored feedback, yet the security of this optimization stage remains underexamined. We present the first systematic analysis of poisoning risks in LLM-based prompt optimization. Using HarmBench, we find systems are substantially more vulnerable to manipulated feedback than to injected queries: feedback-based attacks raise attack success rate (ASR) by up to $\Delta$ASR = 0.48. We introduce a simple fake-reward attack that requires no access to the reward model and significantly increases vulnerability, and we propose a lightweight highlighting defense that reduces the fake-reward $\Delta$ASR from 0.23 to 0.07 without degrading utility. These results establish prompt optimization pipelines as a first-class attack surface and motivate stronger safeguards for feedback channels and optimization frameworks.
Multimodal Named Entity Recognition for Short Social Media Posts
Feb 22, 2018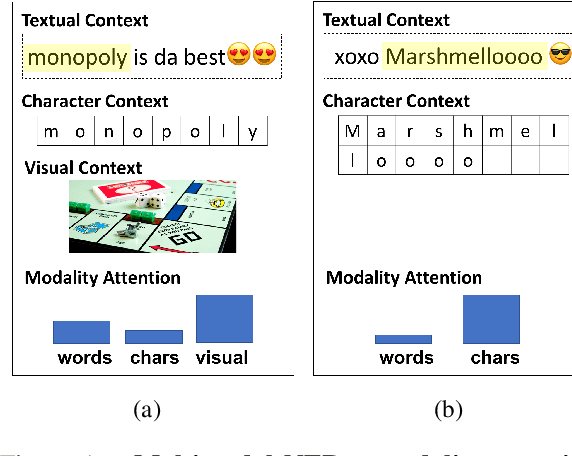

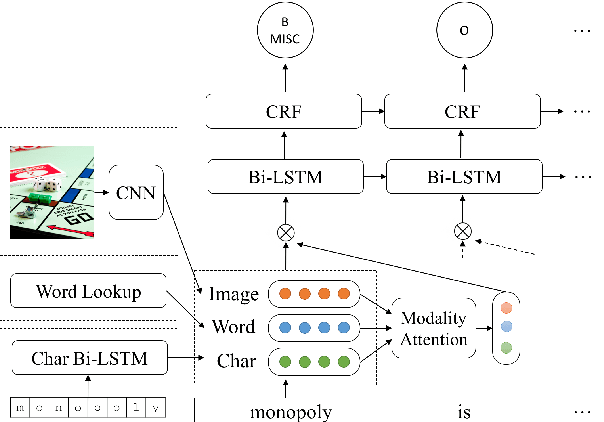

We introduce a new task called Multimodal Named Entity Recognition (MNER) for noisy user-generated data such as tweets or Snapchat captions, which comprise short text with accompanying images. These social media posts often come in inconsistent or incomplete syntax and lexical notations with very limited surrounding textual contexts, bringing significant challenges for NER. To this end, we create a new dataset for MNER called SnapCaptions (Snapchat image-caption pairs submitted to public and crowd-sourced stories with fully annotated named entities). We then build upon the state-of-the-art Bi-LSTM word/character based NER models with 1) a deep image network which incorporates relevant visual context to augment textual information, and 2) a generic modality-attention module which learns to attenuate irrelevant modalities while amplifying the most informative ones to extract contexts from, adaptive to each sample and token. The proposed MNER model with modality attention significantly outperforms the state-of-the-art text-only NER models by successfully leveraging provided visual contexts, opening up potential applications of MNER on myriads of social media platforms.