 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProc3D: Procedural 3D Generation and Parametric Editing of 3D Shapes with Large Language Models
Jan 18, 2026Generating 3D models has traditionally been a complex task requiring specialized expertise. While recent advances in generative AI have sought to automate this process, existing methods produce non-editable representation, such as meshes or point clouds, limiting their adaptability for iterative design. In this paper, we introduce Proc3D, a system designed to generate editable 3D models while enabling real-time modifications. At its core, Proc3D introduces procedural compact graph (PCG), a graph representation of 3D models, that encodes the algorithmic rules and structures necessary for generating the model. This representation exposes key parameters, allowing intuitive manual adjustments via sliders and checkboxes, as well as real-time, automated modifications through natural language prompts using Large Language Models (LLMs). We demonstrate Proc3D's capabilities using two generative approaches: GPT-4o with in-context learning (ICL) and a fine-tuned LLAMA-3 model. Experimental results show that Proc3D outperforms existing methods in editing efficiency, achieving more than 400x speedup over conventional approaches that require full regeneration for each modification. Additionally, Proc3D improves ULIP scores by 28%, a metric that evaluates the alignment between generated 3D models and text prompts. By enabling text-aligned 3D model generation along with precise, real-time parametric edits, Proc3D facilitates highly accurate text-based image editing applications.
UDPNet: Unleashing Depth-based Priors for Robust Image Dehazing
Jan 11, 2026Image dehazing has witnessed significant advancements with the development of deep learning models. However, a few methods predominantly focus on single-modal RGB features, neglecting the inherent correlation between scene depth and haze distribution. Even those that jointly optimize depth estimation and image dehazing often suffer from suboptimal performance due to inadequate utilization of accurate depth information. In this paper, we present UDPNet, a general framework that leverages depth-based priors from large-scale pretrained depth estimation model DepthAnything V2 to boost existing image dehazing models. Specifically, our architecture comprises two typical components: the Depth-Guided Attention Module (DGAM) adaptively modulates features via lightweight depth-guided channel attention, and the Depth Prior Fusion Module (DPFM) enables hierarchical fusion of multi-scale depth map features by dual sliding-window multi-head cross-attention mechanism. These modules ensure both computational efficiency and effective integration of depth priors. Moreover, the intrinsic robustness of depth priors empowers the network to dynamically adapt to varying haze densities, illumination conditions, and domain gaps across synthetic and real-world data. Extensive experimental results demonstrate the effectiveness of our UDPNet, outperforming the state-of-the-art methods on popular dehazing datasets, such as 0.85 dB PSNR improvement on the SOTS dataset, 1.19 dB on the Haze4K dataset and 1.79 dB PSNR on the NHR dataset. Our proposed solution establishes a new benchmark for depth-aware dehazing across various scenarios. Pretrained models and codes will be released at our project https://github.com/Harbinzzy/UDPNet.
Atom: Efficient On-Device Video-Language Pipelines Through Modular Reuse
Dec 18, 2025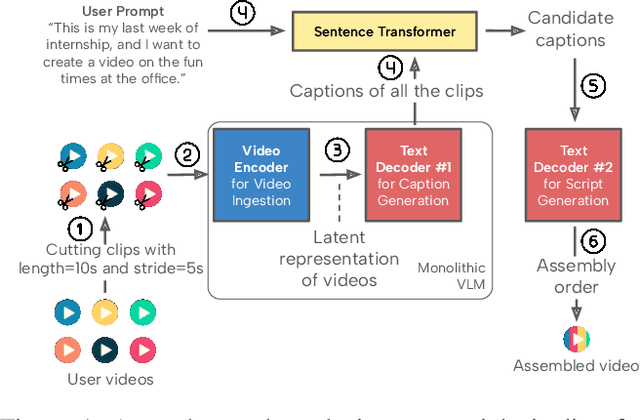

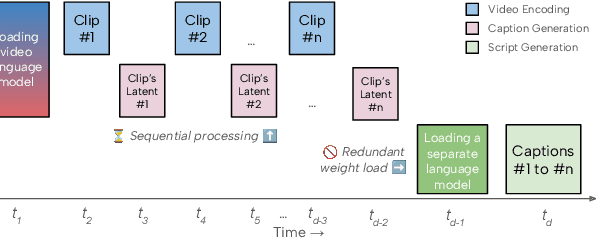

Recent advances in video-language models have enabled powerful applications like video retrieval, captioning, and assembly. However, executing such multi-stage pipelines efficiently on mobile devices remains challenging due to redundant model loads and fragmented execution. We introduce Atom, an on-device system that restructures video-language pipelines for fast and efficient execution. Atom decomposes a billion-parameter model into reusable modules, such as the visual encoder and language decoder, and reuses them across subtasks like captioning, reasoning, and indexing. This reuse-centric design eliminates repeated model loading and enables parallel execution, reducing end-to-end latency without sacrificing performance. On commodity smartphones, Atom achieves 27--33% faster execution compared to non-reuse baselines, with only marginal performance drop ($\leq$ 2.3 Recall@1 in retrieval, $\leq$ 1.5 CIDEr in captioning). These results position Atom as a practical, scalable approach for efficient video-language understanding on edge devices.
MedGEN-Bench: Contextually entangled benchmark for open-ended multimodal medical generation
Nov 18, 2025As Vision-Language Models (VLMs) increasingly gain traction in medical applications, clinicians are progressively expecting AI systems not only to generate textual diagnoses but also to produce corresponding medical images that integrate seamlessly into authentic clinical workflows. Despite the growing interest, existing medical visual benchmarks present notable limitations. They often rely on ambiguous queries that lack sufficient relevance to image content, oversimplify complex diagnostic reasoning into closed-ended shortcuts, and adopt a text-centric evaluation paradigm that overlooks the importance of image generation capabilities. To address these challenges, we introduce MedGEN-Bench, a comprehensive multimodal benchmark designed to advance medical AI research. MedGEN-Bench comprises 6,422 expert-validated image-text pairs spanning six imaging modalities, 16 clinical tasks, and 28 subtasks. It is structured into three distinct formats: Visual Question Answering, Image Editing, and Contextual Multimodal Generation. What sets MedGEN-Bench apart is its focus on contextually intertwined instructions that necessitate sophisticated cross-modal reasoning and open-ended generative outputs, moving beyond the constraints of multiple-choice formats. To evaluate the performance of existing systems, we employ a novel three-tier assessment framework that integrates pixel-level metrics, semantic text analysis, and expert-guided clinical relevance scoring. Using this framework, we systematically assess 10 compositional frameworks, 3 unified models, and 5 VLMs.
Exploring the Global-to-Local Attention Scheme in Graph Transformers: An Empirical Study
Sep 18, 2025Graph Transformers (GTs) show considerable potential in graph representation learning. The architecture of GTs typically integrates Graph Neural Networks (GNNs) with global attention mechanisms either in parallel or as a precursor to attention mechanisms, yielding a local-and-global or local-to-global attention scheme. However, as the global attention mechanism primarily captures long-range dependencies between nodes, these integration schemes may suffer from information loss, where the local neighborhood information learned by GNN could be diluted by the attention mechanism. Therefore, we propose G2LFormer, featuring a novel global-to-local attention scheme where the shallow network layers use attention mechanisms to capture global information, while the deeper layers employ GNN modules to learn local structural information, thereby preventing nodes from ignoring their immediate neighbors. An effective cross-layer information fusion strategy is introduced to allow local layers to retain beneficial information from global layers and alleviate information loss, with acceptable trade-offs in scalability. To validate the feasibility of the global-to-local attention scheme, we compare G2LFormer with state-of-the-art linear GTs and GNNs on node-level and graph-level tasks. The results indicate that G2LFormer exhibits excellent performance while keeping linear complexity.
A Survey on Long-Video Storytelling Generation: Architectures, Consistency, and Cinematic Quality
Jul 09, 2025

Despite the significant progress that has been made in video generative models, existing state-of-the-art methods can only produce videos lasting 5-16 seconds, often labeled "long-form videos". Furthermore, videos exceeding 16 seconds struggle to maintain consistent character appearances and scene layouts throughout the narrative. In particular, multi-subject long videos still fail to preserve character consistency and motion coherence. While some methods can generate videos up to 150 seconds long, they often suffer from frame redundancy and low temporal diversity. Recent work has attempted to produce long-form videos featuring multiple characters, narrative coherence, and high-fidelity detail. We comprehensively studied 32 papers on video generation to identify key architectural components and training strategies that consistently yield these qualities. We also construct a comprehensive novel taxonomy of existing methods and present comparative tables that categorize papers by their architectural designs and performance characteristics.
Boosting All-in-One Image Restoration via Self-Improved Privilege Learning
May 30, 2025Unified image restoration models for diverse and mixed degradations often suffer from unstable optimization dynamics and inter-task conflicts. This paper introduces Self-Improved Privilege Learning (SIPL), a novel paradigm that overcomes these limitations by innovatively extending the utility of privileged information (PI) beyond training into the inference stage. Unlike conventional Privilege Learning, where ground-truth-derived guidance is typically discarded after training, SIPL empowers the model to leverage its own preliminary outputs as pseudo-privileged signals for iterative self-refinement at test time. Central to SIPL is Proxy Fusion, a lightweight module incorporating a learnable Privileged Dictionary. During training, this dictionary distills essential high-frequency and structural priors from privileged feature representations. Critically, at inference, the same learned dictionary then interacts with features derived from the model's initial restoration, facilitating a self-correction loop. SIPL can be seamlessly integrated into various backbone architectures, offering substantial performance improvements with minimal computational overhead. Extensive experiments demonstrate that SIPL significantly advances the state-of-the-art on diverse all-in-one image restoration benchmarks. For instance, when integrated with the PromptIR model, SIPL achieves remarkable PSNR improvements of +4.58 dB on composite degradation tasks and +1.28 dB on diverse five-task benchmarks, underscoring its effectiveness and broad applicability. Codes are available at our project page https://github.com/Aitical/SIPL.
Exploring Generalized Gait Recognition: Reducing Redundancy and Noise within Indoor and Outdoor Datasets
May 21, 2025Generalized gait recognition, which aims to achieve robust performance across diverse domains, remains a challenging problem due to severe domain shifts in viewpoints, appearances, and environments. While mixed-dataset training is widely used to enhance generalization, it introduces new obstacles including inter-dataset optimization conflicts and redundant or noisy samples, both of which hinder effective representation learning. To address these challenges, we propose a unified framework that systematically improves cross-domain gait recognition. First, we design a disentangled triplet loss that isolates supervision signals across datasets, mitigating gradient conflicts during optimization. Second, we introduce a targeted dataset distillation strategy that filters out the least informative 20\% of training samples based on feature redundancy and prediction uncertainty, enhancing data efficiency. Extensive experiments on CASIA-B, OU-MVLP, Gait3D, and GREW demonstrate that our method significantly improves cross-dataset recognition for both GaitBase and DeepGaitV2 backbones, without sacrificing source-domain accuracy. Code will be released at https://github.com/li1er3/Generalized_Gait.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Skill Discovery for Software Scripting Automation via Offline Simulations with LLMs
Apr 29, 2025Scripting interfaces enable users to automate tasks and customize software workflows, but creating scripts traditionally requires programming expertise and familiarity with specific APIs, posing barriers for many users. While Large Language Models (LLMs) can generate code from natural language queries, runtime code generation is severely limited due to unverified code, security risks, longer response times, and higher computational costs. To bridge the gap, we propose an offline simulation framework to curate a software-specific skillset, a collection of verified scripts, by exploiting LLMs and publicly available scripting guides. Our framework comprises two components: (1) task creation, using top-down functionality guidance and bottom-up API synergy exploration to generate helpful tasks; and (2) skill generation with trials, refining and validating scripts based on execution feedback. To efficiently navigate the extensive API landscape, we introduce a Graph Neural Network (GNN)-based link prediction model to capture API synergy, enabling the generation of skills involving underutilized APIs and expanding the skillset's diversity. Experiments with Adobe Illustrator demonstrate that our framework significantly improves automation success rates, reduces response time, and saves runtime token costs compared to traditional runtime code generation. This is the first attempt to use software scripting interfaces as a testbed for LLM-based systems, highlighting the advantages of leveraging execution feedback in a controlled environment and offering valuable insights into aligning AI capabilities with user needs in specialized software domains.