 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveFreq: Integrating Active Learning and Frequency Domain Analysis for Interactive Segmentation
Mar 12, 2026Interactive segmentation is commonly used in medical image analysis to obtain precise, pixel-level labeling, typically involving iterative user input to correct mislabeled regions. However, existing approaches often fail to fully utilize user knowledge from interactive inputs and achieve comprehensive feature extraction. Specifically, these methods tend to treat all mislabeled regions equally, selecting them randomly for refinement without evaluating each region's potential impact on segmentation quality. Additionally, most models rely solely on spatial domain features, overlooking frequency domain information that could enhance feature extraction and improve performance. To address these limitations, we propose ActiveFreq, a novel interactive segmentation framework that integrates active learning and frequency domain analysis to minimize human intervention while achieving high-quality labeling. ActiveFreq introduces AcSelect, an autonomous module that prioritizes the most informative mislabeled regions, ensuring maximum performance gain from each click. Moreover, we develop FreqFormer, a segmentation backbone incorporating a Fourier transform module to map features from the spatial to the frequency domain, enabling richer feature extraction. Evaluations on the ISIC-2017 and OAI-ZIB datasets demonstrate that ActiveFreq achieves high performance with reduced user interaction, achieving 3.74 NoC@90 on ISIC-2017 and 9.27 NoC@90 on OAI-ZIB, with 23.5% and 12.8% improvements over previous best results, respectively. Under minimal input conditions, such as two clicks, ActiveFreq reaches mIoU scores of 85.29% and 75.76% on ISIC-2017 and OAI-ZIB, highlighting its efficiency and accuracy in interactive medical segmentation.
* 16 pages, 8 figures, published in Knowledge-Based Systems
Articulat3D: Reconstructing Articulated Digital Twins From Monocular Videos with Geometric and Motion Constraints
Mar 12, 2026Building high-fidelity digital twins of articulated objects from visual data remains a central challenge. Existing approaches depend on multi-view captures of the object in discrete, static states, which severely constrains their real-world scalability. In this paper, we introduce Articulat3D, a novel framework that constructs such digital twins from casually captured monocular videos by jointly enforcing explicit 3D geometric and motion constraints. We first propose Motion Prior-Driven Initialization, which leverages 3D point tracks to exploit the low-dimensional structure of articulated motion. By modeling scene dynamics with a compact set of motion bases, we facilitate soft decomposition of the scene into multiple rigidly-moving groups. Building on this initialization, we introduce Geometric and Motion Constraints Refinement, which enforces physically plausible articulation through learnable kinematic primitives parameterized by a joint axis, a pivot point, and per-frame motion scalars, yielding reconstructions that are both geometrically accurate and temporally coherent. Extensive experiments demonstrate that Articulat3D achieves state-of-the-art performance on synthetic benchmarks and real-world casually captured monocular videos, significantly advancing the feasibility of digital twin creation under uncontrolled real-world conditions. Our project page is at https://maxwell-zhao.github.io/Articulat3D.
Towards Affordance-Aware Robotic Dexterous Grasping with Human-like Priors
Aug 12, 2025A dexterous hand capable of generalizable grasping objects is fundamental for the development of general-purpose embodied AI. However, previous methods focus narrowly on low-level grasp stability metrics, neglecting affordance-aware positioning and human-like poses which are crucial for downstream manipulation. To address these limitations, we propose AffordDex, a novel framework with two-stage training that learns a universal grasping policy with an inherent understanding of both motion priors and object affordances. In the first stage, a trajectory imitator is pre-trained on a large corpus of human hand motions to instill a strong prior for natural movement. In the second stage, a residual module is trained to adapt these general human-like motions to specific object instances. This refinement is critically guided by two components: our Negative Affordance-aware Segmentation (NAA) module, which identifies functionally inappropriate contact regions, and a privileged teacher-student distillation process that ensures the final vision-based policy is highly successful. Extensive experiments demonstrate that AffordDex not only achieves universal dexterous grasping but also remains remarkably human-like in posture and functionally appropriate in contact location. As a result, AffordDex significantly outperforms state-of-the-art baselines across seen objects, unseen instances, and even entirely novel categories.
SMAP: Self-supervised Motion Adaptation for Physically Plausible Humanoid Whole-body Control
May 26, 2025This paper presents a novel framework that enables real-world humanoid robots to maintain stability while performing human-like motion. Current methods train a policy which allows humanoid robots to follow human body using the massive retargeted human data via reinforcement learning. However, due to the heterogeneity between human and humanoid robot motion, directly using retargeted human motion reduces training efficiency and stability. To this end, we introduce SMAP, a novel whole-body tracking framework that bridges the gap between human and humanoid action spaces, enabling accurate motion mimicry by humanoid robots. The core idea is to use a vector-quantized periodic autoencoder to capture generic atomic behaviors and adapt human motion into physically plausible humanoid motion. This adaptation accelerates training convergence and improves stability when handling novel or challenging motions. We then employ a privileged teacher to distill precise mimicry skills into the student policy with a proposed decoupled reward. We conduct experiments in simulation and real world to demonstrate the superiority stability and performance of SMAP over SOTA methods, offering practical guidelines for advancing whole-body control in humanoid robots.
Improving Ad matching via Cluster-Adaptive Keyword Expansion and Relevance tuning
May 24, 2025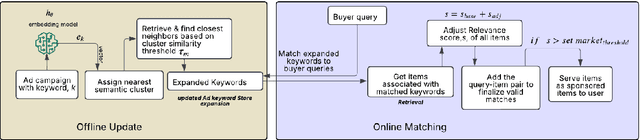

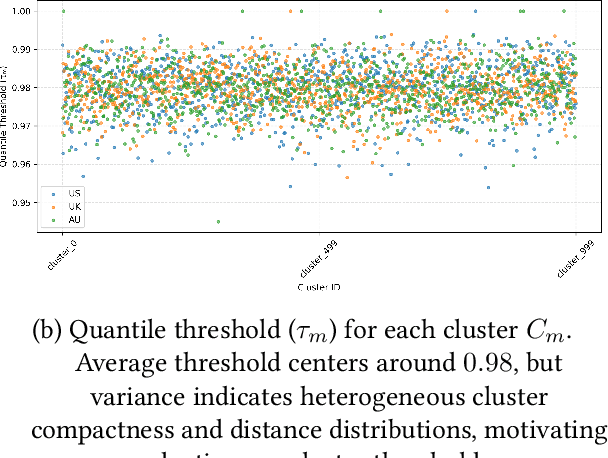
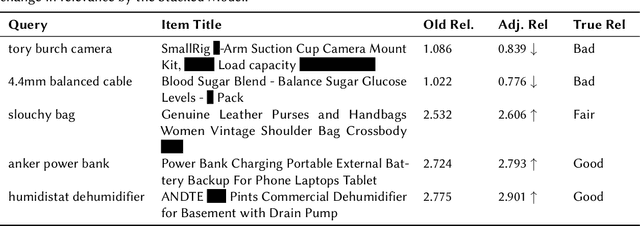
In search advertising, keyword matching connects user queries with relevant ads. While token-based matching increases ad coverage, it can reduce relevance due to overly permissive semantic expansion. This work extends keyword reach through document-side semantic keyword expansion, using a language model to broaden token-level matching without altering queries. We propose a solution using a pre-trained siamese model to generate dense vector representations of ad keywords and identify semantically related variants through nearest neighbor search. To maintain precision, we introduce a cluster-based thresholding mechanism that adjusts similarity cutoffs based on local semantic density. Each expanded keyword maps to a group of seller-listed items, which may only partially align with the original intent. To ensure relevance, we enhance the downstream relevance model by adapting it to the expanded keyword space using an incremental learning strategy with a lightweight decision tree ensemble. This system improves both relevance and click-through rate (CTR), offering a scalable, low-latency solution adaptable to evolving query behavior and advertising inventory.
Exploring Generalized Gait Recognition: Reducing Redundancy and Noise within Indoor and Outdoor Datasets
May 21, 2025Generalized gait recognition, which aims to achieve robust performance across diverse domains, remains a challenging problem due to severe domain shifts in viewpoints, appearances, and environments. While mixed-dataset training is widely used to enhance generalization, it introduces new obstacles including inter-dataset optimization conflicts and redundant or noisy samples, both of which hinder effective representation learning. To address these challenges, we propose a unified framework that systematically improves cross-domain gait recognition. First, we design a disentangled triplet loss that isolates supervision signals across datasets, mitigating gradient conflicts during optimization. Second, we introduce a targeted dataset distillation strategy that filters out the least informative 20\% of training samples based on feature redundancy and prediction uncertainty, enhancing data efficiency. Extensive experiments on CASIA-B, OU-MVLP, Gait3D, and GREW demonstrate that our method significantly improves cross-dataset recognition for both GaitBase and DeepGaitV2 backbones, without sacrificing source-domain accuracy. Code will be released at https://github.com/li1er3/Generalized_Gait.
Automated 3D Physical Simulation of Open-world Scene with Gaussian Splatting
Nov 19, 2024



Recent advancements in 3D generation models have opened new possibilities for simulating dynamic 3D object movements and customizing behaviors, yet creating this content remains challenging. Current methods often require manual assignment of precise physical properties for simulations or rely on video generation models to predict them, which is computationally intensive. In this paper, we rethink the usage of multi-modal large language model (MLLM) in physics-based simulation, and present Sim Anything, a physics-based approach that endows static 3D objects with interactive dynamics. We begin with detailed scene reconstruction and object-level 3D open-vocabulary segmentation, progressing to multi-view image in-painting. Inspired by human visual reasoning, we propose MLLM-based Physical Property Perception (MLLM-P3) to predict mean physical properties of objects in a zero-shot manner. Based on the mean values and the object's geometry, the Material Property Distribution Prediction model (MPDP) model then estimates the full distribution, reformulating the problem as probability distribution estimation to reduce computational costs. Finally, we simulate objects in an open-world scene with particles sampled via the Physical-Geometric Adaptive Sampling (PGAS) strategy, efficiently capturing complex deformations and significantly reducing computational costs. Extensive experiments and user studies demonstrate our Sim Anything achieves more realistic motion than state-of-the-art methods within 2 minutes on a single GPU.