 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEM-Vid: Training-Free Entity-Centric Memory for Efficient and Consistent Multi-Shot Video Generation
May 22, 2026Multi-shot video generation requires maintaining a consistent appearance of recurring entities across shots while remaining faithful to shot-specific text prompts. Recent autoregressive methods reuse previously generated frames as memory. However, full-frame storage entangles persistent entity information with transient scene context, leading to irrelevant information leakage and high computational cost. We propose an entity-centric memory in the form of an entity-indexed bank of latent patches. We introduce sparse token conditioning compatible with pretrained models, restricting self-attention to entity-relevant tokens and reducing computational cost. To support this, we introduce a structured multi-shot script format. We additionally propose a budgeted memory update strategy to maintain a compact, evolving memory. Finally, we equip the entity representation with a noise-injection mechanism that enables fine-grained appearance control, preventing leakage of irrelevant information. Our method improves prompt adherence and efficiency while preserving subject consistency.
ViPS: Video-informed Pose Spaces for Auto-Rigged Meshes
Apr 19, 2026Kinematic rigs provide a structured interface for articulating 3D meshes, but they lack an inherent representation of the plausible manifold of joint configurations for a given asset. Without such a pose space, stochastic sampling or manual manipulation of raw rig parameters often leads to semantic or geometric violations, such as anatomical hyperextension and non-physical self-intersections. We propose Video-informed Pose Spaces (ViPS), a feed-forward framework that discovers the latent distribution of valid articulations for auto-rigged meshes by distilling motion priors from a pretrained video diffusion model. Unlike existing methods that rely on scarce artist-authored 4D datasets, ViPS transfers generative video priors into a universal distribution over a given rig parameterization. Differentiable geometric validators applied to the skinned mesh enforce asset-specific validity without requiring manual regularizers. Our model learns a smooth, compact, and controllable pose space that supports diverse sampling, manifold projection for inverse kinematics, and temporally coherent trajectories for keyframing. Furthermore, the distilled 3D pose samples serve as precise semantic proxies for guiding video diffusion, effectively closing the loop between generative 2D priors and structured 3D kinematic control. Our evaluations show that ViPS, trained solely on video priors, matches the performance of state-of-the-art methods trained on synthetic artist-created 4D data in both plausibility and diversity. Most importantly, as a universal model, ViPS demonstrates robust zero-shot generalization to out-of-distribution species and unseen skeletal topologies.
Material Magic Wand: Material-Aware Grouping of 3D Parts in Untextured Meshes
Mar 18, 2026We introduce the problem of material-aware part grouping in untextured meshes. Many real-world shapes, such as scales of pinecones or windows of buildings, contain repeated structures that share the same material but exhibit geometric variations. When assigning materials to such meshes, these repeated parts often require piece-by-piece manual identification and selection, which is tedious and time-consuming. To address this, we propose Material Magic Wand, a tool that allows artists to select part groups based on their estimated material properties -- when one part is selected, our algorithm automatically retrieves all other parts likely to share the same material. The key component of our approach is a part encoder that generates a material-aware embedding for each 3D part, accounting for both local geometry and global context. We train our model with a supervised contrastive loss that brings embeddings of material-consistent parts closer while separating those of different materials; therefore, part grouping can be achieved by retrieving embeddings that are close to the embedding of the selected part. To benchmark this task, we introduce a curated dataset of 100 shapes with 241 part-level queries. We verify the effectiveness of our method through extensive experiments and demonstrate its practical value in an interactive material assignment application.
Seeing Through Clutter: Structured 3D Scene Reconstruction via Iterative Object Removal
Feb 03, 2026We present SeeingThroughClutter, a method for reconstructing structured 3D representations from single images by segmenting and modeling objects individually. Prior approaches rely on intermediate tasks such as semantic segmentation and depth estimation, which often underperform in complex scenes, particularly in the presence of occlusion and clutter. We address this by introducing an iterative object removal and reconstruction pipeline that decomposes complex scenes into a sequence of simpler subtasks. Using VLMs as orchestrators, foreground objects are removed one at a time via detection, segmentation, object removal, and 3D fitting. We show that removing objects allows for cleaner segmentations of subsequent objects, even in highly occluded scenes. Our method requires no task-specific training and benefits directly from ongoing advances in foundation models. We demonstrate stateof-the-art robustness on 3D-Front and ADE20K datasets. Project Page: https://rioak.github.io/seeingthroughclutter/
3D Space as a Scratchpad for Editable Text-to-Image Generation
Jan 21, 2026Recent progress in large language models (LLMs) has shown that reasoning improves when intermediate thoughts are externalized into explicit workspaces, such as chain-of-thought traces or tool-augmented reasoning. Yet, visual language models (VLMs) lack an analogous mechanism for spatial reasoning, limiting their ability to generate images that accurately reflect geometric relations, object identities, and compositional intent. We introduce the concept of a spatial scratchpad -- a 3D reasoning substrate that bridges linguistic intent and image synthesis. Given a text prompt, our framework parses subjects and background elements, instantiates them as editable 3D meshes, and employs agentic scene planning for placement, orientation, and viewpoint selection. The resulting 3D arrangement is rendered back into the image domain with identity-preserving cues, enabling the VLM to generate spatially consistent and visually coherent outputs. Unlike prior 2D layout-based methods, our approach supports intuitive 3D edits that propagate reliably into final images. Empirically, it achieves a 32% improvement in text alignment on GenAI-Bench, demonstrating the benefit of explicit 3D reasoning for precise, controllable image generation. Our results highlight a new paradigm for vision-language models that deliberate not only in language, but also in space. Code and visualizations at https://oindrilasaha.github.io/3DScratchpad/
Proc3D: Procedural 3D Generation and Parametric Editing of 3D Shapes with Large Language Models
Jan 18, 2026Generating 3D models has traditionally been a complex task requiring specialized expertise. While recent advances in generative AI have sought to automate this process, existing methods produce non-editable representation, such as meshes or point clouds, limiting their adaptability for iterative design. In this paper, we introduce Proc3D, a system designed to generate editable 3D models while enabling real-time modifications. At its core, Proc3D introduces procedural compact graph (PCG), a graph representation of 3D models, that encodes the algorithmic rules and structures necessary for generating the model. This representation exposes key parameters, allowing intuitive manual adjustments via sliders and checkboxes, as well as real-time, automated modifications through natural language prompts using Large Language Models (LLMs). We demonstrate Proc3D's capabilities using two generative approaches: GPT-4o with in-context learning (ICL) and a fine-tuned LLAMA-3 model. Experimental results show that Proc3D outperforms existing methods in editing efficiency, achieving more than 400x speedup over conventional approaches that require full regeneration for each modification. Additionally, Proc3D improves ULIP scores by 28%, a metric that evaluates the alignment between generated 3D models and text prompts. By enabling text-aligned 3D model generation along with precise, real-time parametric edits, Proc3D facilitates highly accurate text-based image editing applications.
GimbalDiffusion: Gravity-Aware Camera Control for Video Generation
Dec 09, 2025


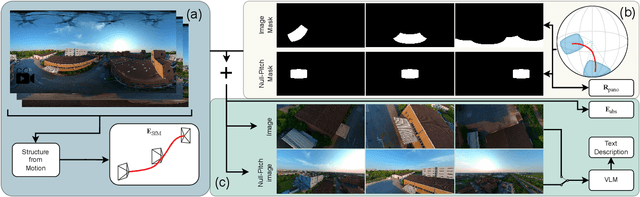
Recent progress in text-to-video generation has achieved remarkable realism, yet fine-grained control over camera motion and orientation remains elusive. Existing approaches typically encode camera trajectories through relative or ambiguous representations, limiting explicit geometric control. We introduce GimbalDiffusion, a framework that enables camera control grounded in physical-world coordinates, using gravity as a global reference. Instead of describing motion relative to previous frames, our method defines camera trajectories in an absolute coordinate system, allowing precise and interpretable control over camera parameters without requiring an initial reference frame. We leverage panoramic 360-degree videos to construct a wide variety of camera trajectories, well beyond the predominantly straight, forward-facing trajectories seen in conventional video data. To further enhance camera guidance, we introduce null-pitch conditioning, an annotation strategy that reduces the model's reliance on text content when conflicting with camera specifications (e.g., generating grass while the camera points towards the sky). Finally, we establish a benchmark for camera-aware video generation by rebalancing SpatialVID-HQ for comprehensive evaluation under wide camera pitch variation. Together, these contributions advance the controllability and robustness of text-to-video models, enabling precise, gravity-aligned camera manipulation within generative frameworks.
Residual Primitive Fitting of 3D Shapes with SuperFrusta
Dec 09, 2025We introduce a framework for converting 3D shapes into compact and editable assemblies of analytic primitives, directly addressing the persistent trade-off between reconstruction fidelity and parsimony. Our approach combines two key contributions: a novel primitive, termed SuperFrustum, and an iterative fiting algorithm, Residual Primitive Fitting (ResFit). SuperFrustum is an analytical primitive that is simultaneously (1) expressive, being able to model various common solids such as cylinders, spheres, cones & their tapered and bent forms, (2) editable, being compactly parameterized with 8 parameters, and (3) optimizable, with a sign distance field differentiable w.r.t. its parameters almost everywhere. ResFit is an unsupervised procedure that interleaves global shape analysis with local optimization, iteratively fitting primitives to the unexplained residual of a shape to discover a parsimonious yet accurate decompositions for each input shape. On diverse 3D benchmarks, our method achieves state-of-the-art results, improving IoU by over 9 points while using nearly half as many primitives as prior work. The resulting assemblies bridge the gap between dense 3D data and human-controllable design, producing high-fidelity and editable shape programs.
Reusing Computation in Text-to-Image Diffusion for Efficient Generation of Image Sets
Aug 28, 2025Text-to-image diffusion models enable high-quality image generation but are computationally expensive. While prior work optimizes per-inference efficiency, we explore an orthogonal approach: reducing redundancy across correlated prompts. Our method leverages the coarse-to-fine nature of diffusion models, where early denoising steps capture shared structures among similar prompts. We propose a training-free approach that clusters prompts based on semantic similarity and shares computation in early diffusion steps. Experiments show that for models trained conditioned on image embeddings, our approach significantly reduces compute cost while improving image quality. By leveraging UnClip's text-to-image prior, we enhance diffusion step allocation for greater efficiency. Our method seamlessly integrates with existing pipelines, scales with prompt sets, and reduces the environmental and financial burden of large-scale text-to-image generation. Project page: https://ddecatur.github.io/hierarchical-diffusion/
Frame In-N-Out: Unbounded Controllable Image-to-Video Generation
May 27, 2025Controllability, temporal coherence, and detail synthesis remain the most critical challenges in video generation. In this paper, we focus on a commonly used yet underexplored cinematic technique known as Frame In and Frame Out. Specifically, starting from image-to-video generation, users can control the objects in the image to naturally leave the scene or provide breaking new identity references to enter the scene, guided by user-specified motion trajectory. To support this task, we introduce a new dataset curated semi-automatically, a comprehensive evaluation protocol targeting this setting, and an efficient identity-preserving motion-controllable video Diffusion Transformer architecture. Our evaluation shows that our proposed approach significantly outperforms existing baselines.