 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable FB-GNN-MBE Framework for Potential Energy Surfaces: Data-Adaptive Transfer Learning in Deep Learned Many-Body Expansion Theory
Apr 10, 2026Mechanistic understanding and rational design of complex chemical systems depend on fast and accurate predictions of electronic structures beyond individual building blocks. However, if the system exceeds hundreds of atoms, first-principles quantum mechanical (QM) modeling becomes impractical. In this study, we developed FB-GNN-MBE by integrating a fragment-based graph neural network (FB-GNN) into the many-body expansion (MBE) theory and demonstrated its capacity to reproduce first-principles potential energy surfaces (PES) for hierarchically structured systems with manageable accuracy, complexity, and interpretability. Specifically, we divided the entire system into basic building blocks (fragments), evaluated their one-fragment energies using a QM model, and addressed many-fragment interactions using the structure-property relationships trained by FB-GNNs. Our investigation shows that FB-GNN-MBE achieves chemical accuracy in predicting two-body (2B) and three-body (3B) energies across water, phenol, and mixture benchmarks, as well as the one-dimensional dissociation curves of water and phenol dimers. To transfer the success of FB-GNN-MBE across various systems with minimal computational costs and data demands, we developed and validated a teacher-student learning protocol. A heavy-weight FB-GNN trained on a mixed-density water cluster ensemble (teacher) distills its learned knowledge and passes it to a light-weight GNN (student), which is later fine-tuned on a uniform-density (H2O)21 cluster ensemble. This transfer learning strategy resulted in efficient and accurate prediction of 2B and 3B energies for variously sized water clusters without retraining. Our transferable FB-GNN-MBE framework outperformed conventional non-FB-GNN-based models and showed high practicality for large-scale molecular simulations.
Ambig-IaC: Multi-level Disambiguation for Interactive Cloud Infrastructure-as-Code Synthesis
Apr 01, 2026The scale and complexity of modern cloud infrastructure have made Infrastructure-as-Code (IaC) essential for managing deployments. While large Language models (LLMs) are increasingly being used to generate IaC configurations from natural language, user requests are often underspecified. Unlike traditional code generation, IaC configurations cannot be executed cheaply or iteratively repaired, forcing the LLMs into an almost one-shot regime. We observe that ambiguity in IaC exhibits a tractable compositional structure: configurations decompose into three hierarchical axes (resources, topology, attributes) where higher-level decisions constrain lower-level ones. We propose a training-free, disagreement-driven framework that generates diverse candidate specifications, identifies structural disagreements across these axes, ranks them by informativeness, and produces targeted clarification questions that progressively narrow the configuration space. We introduce \textsc{Ambig-IaC}, a benchmark of 300 validated IaC tasks with ambiguous prompts, and an evaluation framework based on graph edit distance and embedding similarity. Our method outperforms the strongest baseline, achieving relative improvements of +18.4\% and +25.4\% on structure and attribute evaluations, respectively.
Atom: Efficient On-Device Video-Language Pipelines Through Modular Reuse
Dec 18, 2025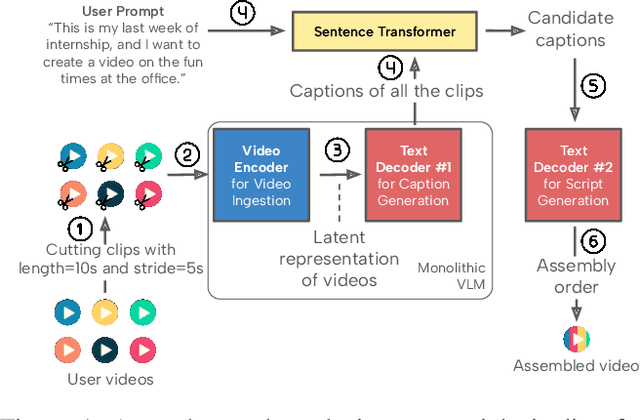

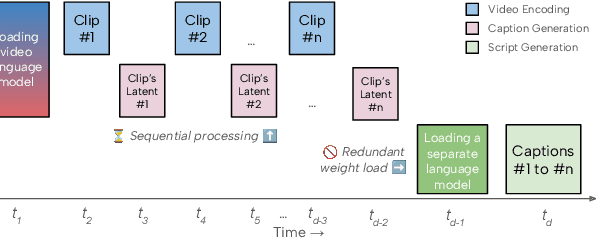

Recent advances in video-language models have enabled powerful applications like video retrieval, captioning, and assembly. However, executing such multi-stage pipelines efficiently on mobile devices remains challenging due to redundant model loads and fragmented execution. We introduce Atom, an on-device system that restructures video-language pipelines for fast and efficient execution. Atom decomposes a billion-parameter model into reusable modules, such as the visual encoder and language decoder, and reuses them across subtasks like captioning, reasoning, and indexing. This reuse-centric design eliminates repeated model loading and enables parallel execution, reducing end-to-end latency without sacrificing performance. On commodity smartphones, Atom achieves 27--33% faster execution compared to non-reuse baselines, with only marginal performance drop ($\leq$ 2.3 Recall@1 in retrieval, $\leq$ 1.5 CIDEr in captioning). These results position Atom as a practical, scalable approach for efficient video-language understanding on edge devices.
Communication-Efficient Multi-Device Inference Acceleration for Transformer Models
May 25, 2025Transformer models power many AI applications but suffer from high inference latency, limiting their use in real-time settings. Multi-device inference can reduce latency by parallelizing computation. Yet, existing methods require high inter-device bandwidth, making them impractical for bandwidth-constrained environments. We propose ASTRA, a communication-efficient framework that accelerates Transformer inference through a novel integration of sequence parallelism and a Mixed-Precision Attention mechanism designed to minimize inter-device communication. ASTRA compresses non-local token embeddings via vector quantization and preserves task accuracy through two optimizations, Noise-Augmented Quantization and Distributed Class Tokens. Experiments on ViT and GPT2 across vision and NLP tasks show that ASTRA achieves up to 2.64X speedups over single-device inference and up to 15.25X speedups over state-of-the-art multi-device inferences, while operating under bandwidths as low as 10 Mbps. ASTRA is open-sourced at https://github.com/xl1990/Astra.
AI-Driven Innovations in Volumetric Video Streaming: A Review
Dec 15, 2024



Recent efforts to enhance immersive and interactive user experiences have driven the development of volumetric video, a form of 3D content that enables 6 DoF. Unlike traditional 2D content, volumetric content can be represented in various ways, such as point clouds, meshes, or neural representations. However, due to its complex structure and large amounts of data size, deploying this new form of 3D data presents significant challenges in transmission and rendering. These challenges have hindered the widespread adoption of volumetric video in daily applications. In recent years, researchers have proposed various AI-driven techniques to address these challenges and improve the efficiency and quality of volumetric content streaming. This paper provides a comprehensive overview of recent advances in AI-driven approaches to facilitate volumetric content streaming. Through this review, we aim to offer insights into the current state-of-the-art and suggest potential future directions for advancing the deployment of volumetric video streaming in real-world applications.
Aligned Vector Quantization for Edge-Cloud Collabrative Vision-Language Models
Nov 08, 2024



Vision Language Models (VLMs) are central to Visual Question Answering (VQA) systems and are typically deployed in the cloud due to their high computational demands. However, this cloud-only approach underutilizes edge computational resources and requires significant bandwidth for transmitting raw images. In this paper, we introduce an edge-cloud collaborative VQA system, called LLaVA-AlignedVQ, which features a novel Aligned Vector Quantization algorithm (AlignedVQ) that efficiently compress intermediate features without compromising accuracy to support partitioned execution. Our experiments demonstrate that LLaVA-AlignedVQ achieves approximately 1365x compression rate of intermediate features, reducing data transmission overhead by 96.8% compared to transmitting JPEG90-compressed images to the cloud. LLaVA-AlignedVQ achieves an inference speedup of 2-15x while maintaining high accuracy, remaining within -2.23% to +1.6% of the original model's accuracy performance across eight VQA datasets, compared to the cloud-only solution.
Integrating Graph Neural Networks and Many-Body Expansion Theory for Potential Energy Surfaces
Nov 03, 2024



Rational design of next-generation functional materials relied on quantitative predictions of their electronic structures beyond single building blocks. First-principles quantum mechanical (QM) modeling became infeasible as the size of a material grew beyond hundreds of atoms. In this study, we developed a new computational tool integrating fragment-based graph neural networks (FBGNN) into the fragment-based many-body expansion (MBE) theory, referred to as FBGNN-MBE, and demonstrated its capacity to reproduce full-dimensional potential energy surfaces (FD-PES) for hierarchic chemical systems with manageable accuracy, complexity, and interpretability. In particular, we divided the entire system into basic building blocks (fragments), evaluated their single-fragment energies using a first-principles QM model and attacked many-fragment interactions using the structure-property relationships trained by FBGNNs. Our development of FBGNN-MBE demonstrated the potential of a new framework integrating deep learning models into fragment-based QM methods, and marked a significant step towards computationally aided design of large functional materials.
Understanding and Alleviating Memory Consumption in RLHF for LLMs
Oct 21, 2024


Fine-tuning with Reinforcement Learning with Human Feedback (RLHF) is essential for aligning large language models (LLMs). However, RLHF often encounters significant memory challenges. This study is the first to examine memory usage in the RLHF context, exploring various memory management strategies and unveiling the reasons behind excessive memory consumption. Additionally, we introduce a simple yet effective approach that substantially reduces the memory required for RLHF fine-tuning.
In-Situ Fine-Tuning of Wildlife Models in IoT-Enabled Camera Traps for Efficient Adaptation
Sep 12, 2024



Wildlife monitoring via camera traps has become an essential tool in ecology, but the deployment of machine learning models for on-device animal classification faces significant challenges due to domain shifts and resource constraints. This paper introduces WildFit, a novel approach that reconciles the conflicting goals of achieving high domain generalization performance and ensuring efficient inference for camera trap applications. WildFit leverages continuous background-aware model fine-tuning to deploy ML models tailored to the current location and time window, allowing it to maintain robust classification accuracy in the new environment without requiring significant computational resources. This is achieved by background-aware data synthesis, which generates training images representing the new domain by blending background images with animal images from the source domain. We further enhance fine-tuning effectiveness through background drift detection and class distribution drift detection, which optimize the quality of synthesized data and improve generalization performance. Our extensive evaluation across multiple camera trap datasets demonstrates that WildFit achieves significant improvements in classification accuracy and computational efficiency compared to traditional approaches.
AdapMTL: Adaptive Pruning Framework for Multitask Learning Model
Aug 07, 2024In the domain of multimedia and multimodal processing, the efficient handling of diverse data streams such as images, video, and sensor data is paramount. Model compression and multitask learning (MTL) are crucial in this field, offering the potential to address the resource-intensive demands of processing and interpreting multiple forms of media simultaneously. However, effectively compressing a multitask model presents significant challenges due to the complexities of balancing sparsity allocation and accuracy performance across multiple tasks. To tackle these challenges, we propose AdapMTL, an adaptive pruning framework for MTL models. AdapMTL leverages multiple learnable soft thresholds independently assigned to the shared backbone and the task-specific heads to capture the nuances in different components' sensitivity to pruning. During training, it co-optimizes the soft thresholds and MTL model weights to automatically determine the suitable sparsity level at each component to achieve both high task accuracy and high overall sparsity. It further incorporates an adaptive weighting mechanism that dynamically adjusts the importance of task-specific losses based on each task's robustness to pruning. We demonstrate the effectiveness of AdapMTL through comprehensive experiments on popular multitask datasets, namely NYU-v2 and Tiny-Taskonomy, with different architectures, showcasing superior performance compared to state-of-the-art pruning methods.