 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Mask Transfiner for High-Quality Video Instance Segmentation
Jul 28, 2022
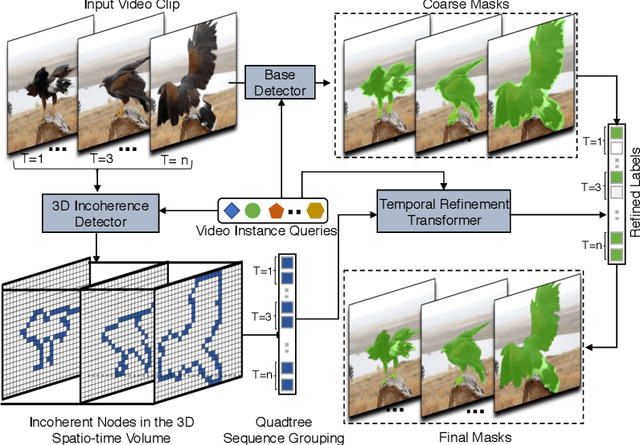


While Video Instance Segmentation (VIS) has seen rapid progress, current approaches struggle to predict high-quality masks with accurate boundary details. Moreover, the predicted segmentations often fluctuate over time, suggesting that temporal consistency cues are neglected or not fully utilized. In this paper, we set out to tackle these issues, with the aim of achieving highly detailed and more temporally stable mask predictions for VIS. We first propose the Video Mask Transfiner (VMT) method, capable of leveraging fine-grained high-resolution features thanks to a highly efficient video transformer structure. Our VMT detects and groups sparse error-prone spatio-temporal regions of each tracklet in the video segment, which are then refined using both local and instance-level cues. Second, we identify that the coarse boundary annotations of the popular YouTube-VIS dataset constitute a major limiting factor. Based on our VMT architecture, we therefore design an automated annotation refinement approach by iterative training and self-correction. To benchmark high-quality mask predictions for VIS, we introduce the HQ-YTVIS dataset, consisting of a manually re-annotated test set and our automatically refined training data. We compare VMT with the most recent state-of-the-art methods on the HQ-YTVIS, as well as the Youtube-VIS, OVIS and BDD100K MOTS benchmarks. Experimental results clearly demonstrate the efficacy and effectiveness of our method on segmenting complex and dynamic objects, by capturing precise details.
Tracking Every Thing in the Wild
Jul 26, 2022


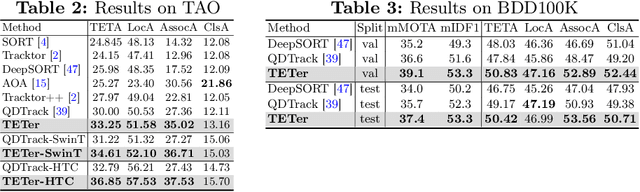
Current multi-category Multiple Object Tracking (MOT) metrics use class labels to group tracking results for per-class evaluation. Similarly, MOT methods typically only associate objects with the same class predictions. These two prevalent strategies in MOT implicitly assume that the classification performance is near-perfect. However, this is far from the case in recent large-scale MOT datasets, which contain large numbers of classes with many rare or semantically similar categories. Therefore, the resulting inaccurate classification leads to sub-optimal tracking and inadequate benchmarking of trackers. We address these issues by disentangling classification from tracking. We introduce a new metric, Track Every Thing Accuracy (TETA), breaking tracking measurement into three sub-factors: localization, association, and classification, allowing comprehensive benchmarking of tracking performance even under inaccurate classification. TETA also deals with the challenging incomplete annotation problem in large-scale tracking datasets. We further introduce a Track Every Thing tracker (TETer), that performs association using Class Exemplar Matching (CEM). Our experiments show that TETA evaluates trackers more comprehensively, and TETer achieves significant improvements on the challenging large-scale datasets BDD100K and TAO compared to the state-of-the-art.
SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation
Jun 16, 2022
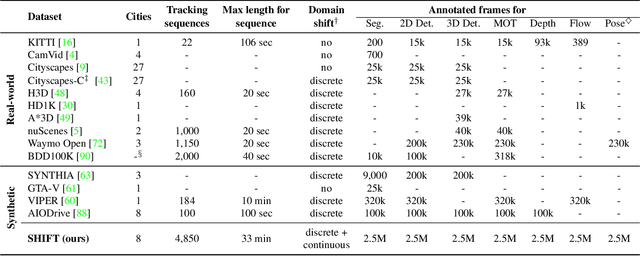
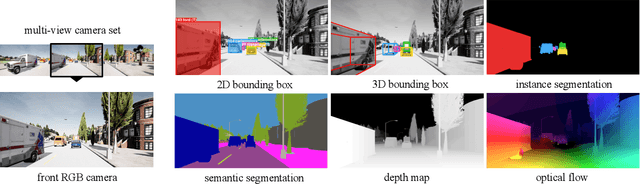

Adapting to a continuously evolving environment is a safety-critical challenge inevitably faced by all autonomous driving systems. Existing image and video driving datasets, however, fall short of capturing the mutable nature of the real world. In this paper, we introduce the largest multi-task synthetic dataset for autonomous driving, SHIFT. It presents discrete and continuous shifts in cloudiness, rain and fog intensity, time of day, and vehicle and pedestrian density. Featuring a comprehensive sensor suite and annotations for several mainstream perception tasks, SHIFT allows investigating the degradation of a perception system performance at increasing levels of domain shift, fostering the development of continuous adaptation strategies to mitigate this problem and assess model robustness and generality. Our dataset and benchmark toolkit are publicly available at www.vis.xyz/shift.
Learning Online Multi-Sensor Depth Fusion
Apr 07, 2022

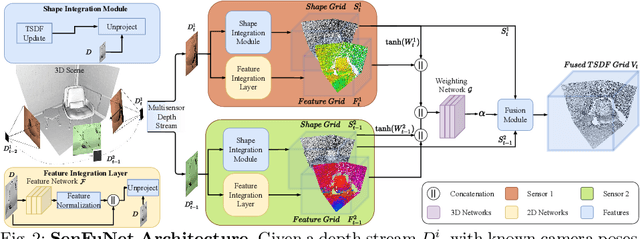
Many hand-held or mixed reality devices are used with a single sensor for 3D reconstruction, although they often comprise multiple sensors. Multi-sensor depth fusion is able to substantially improve the robustness and accuracy of 3D reconstruction methods, but existing techniques are not robust enough to handle sensors which operate with diverse value ranges as well as noise and outlier statistics. To this end, we introduce SenFuNet, a depth fusion approach that learns sensor-specific noise and outlier statistics and combines the data streams of depth frames from different sensors in an online fashion. Our method fuses multi-sensor depth streams regardless of time synchronization and calibration and generalizes well with little training data. We conduct experiments with various sensor combinations on the real-world CoRBS and Scene3D datasets, as well as the Replica dataset. Experiments demonstrate that our fusion strategy outperforms traditional and recent online depth fusion approaches. In addition, the combination of multiple sensors yields more robust outlier handling and precise surface reconstruction than the use of a single sensor.
LiDAR Snowfall Simulation for Robust 3D Object Detection
Mar 28, 2022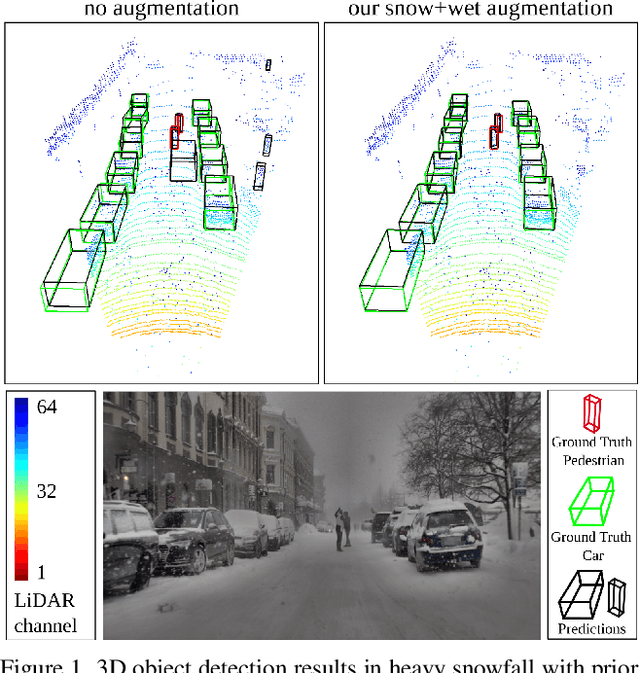
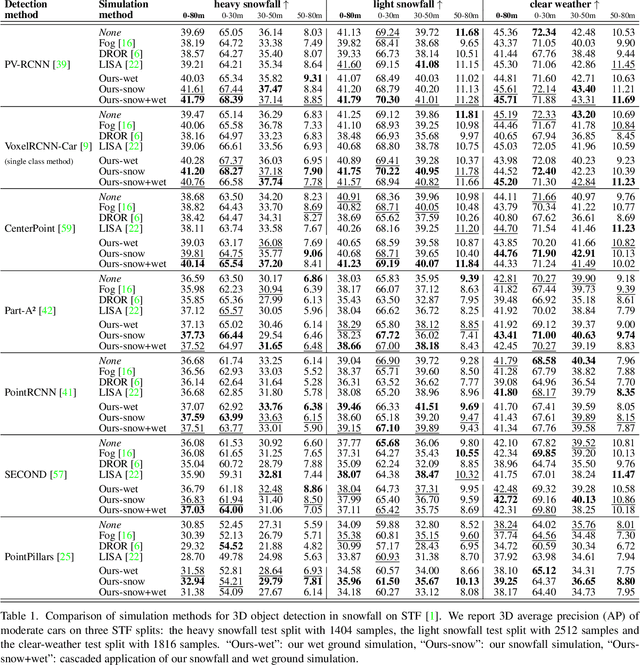
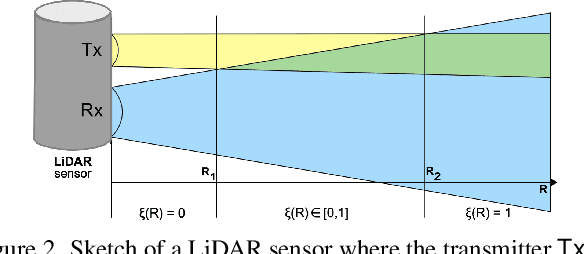
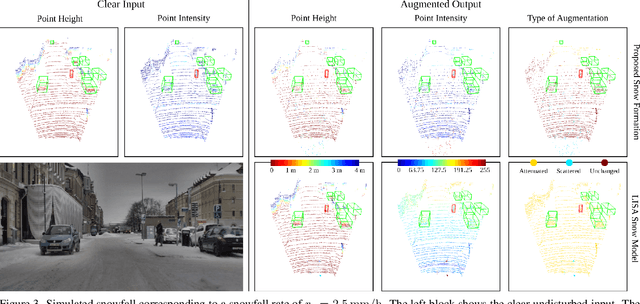
3D object detection is a central task for applications such as autonomous driving, in which the system needs to localize and classify surrounding traffic agents, even in the presence of adverse weather. In this paper, we address the problem of LiDAR-based 3D object detection under snowfall. Due to the difficulty of collecting and annotating training data in this setting, we propose a physically based method to simulate the effect of snowfall on real clear-weather LiDAR point clouds. Our method samples snow particles in 2D space for each LiDAR line and uses the induced geometry to modify the measurement for each LiDAR beam accordingly. Moreover, as snowfall often causes wetness on the ground, we also simulate ground wetness on LiDAR point clouds. We use our simulation to generate partially synthetic snowy LiDAR data and leverage these data for training 3D object detection models that are robust to snowfall. We conduct an extensive evaluation using several state-of-the-art 3D object detection methods and show that our simulation consistently yields significant performance gains on the real snowy STF dataset compared to clear-weather baselines and competing simulation approaches, while not sacrificing performance in clear weather. Our code is available at www.github.com/SysCV/LiDAR_snow_sim.
Transforming Model Prediction for Tracking
Mar 21, 2022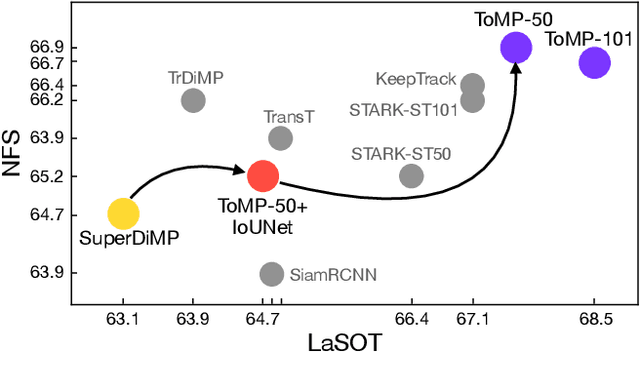
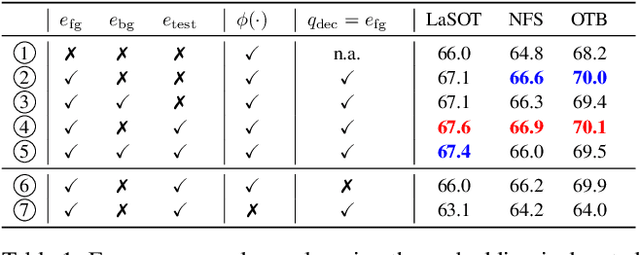
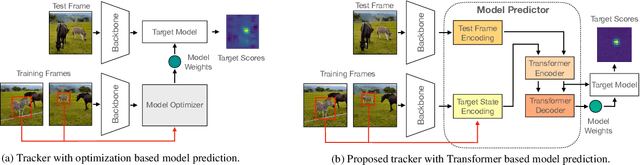
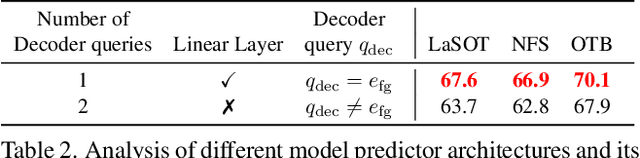
Optimization based tracking methods have been widely successful by integrating a target model prediction module, providing effective global reasoning by minimizing an objective function. While this inductive bias integrates valuable domain knowledge, it limits the expressivity of the tracking network. In this work, we therefore propose a tracker architecture employing a Transformer-based model prediction module. Transformers capture global relations with little inductive bias, allowing it to learn the prediction of more powerful target models. We further extend the model predictor to estimate a second set of weights that are applied for accurate bounding box regression. The resulting tracker relies on training and on test frame information in order to predict all weights transductively. We train the proposed tracker end-to-end and validate its performance by conducting comprehensive experiments on multiple tracking datasets. Our tracker sets a new state of the art on three benchmarks, achieving an AUC of 68.5% on the challenging LaSOT dataset.
Probabilistic Warp Consistency for Weakly-Supervised Semantic Correspondences
Mar 08, 2022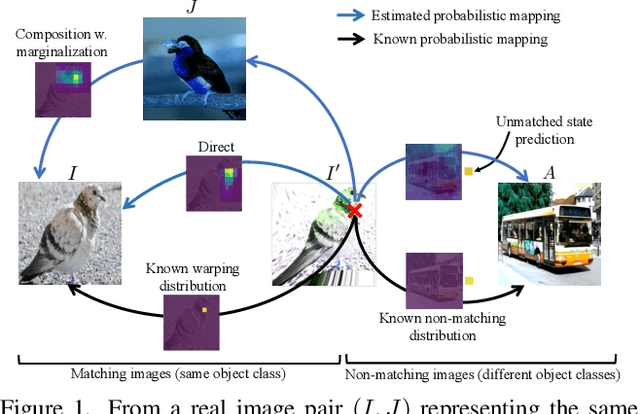
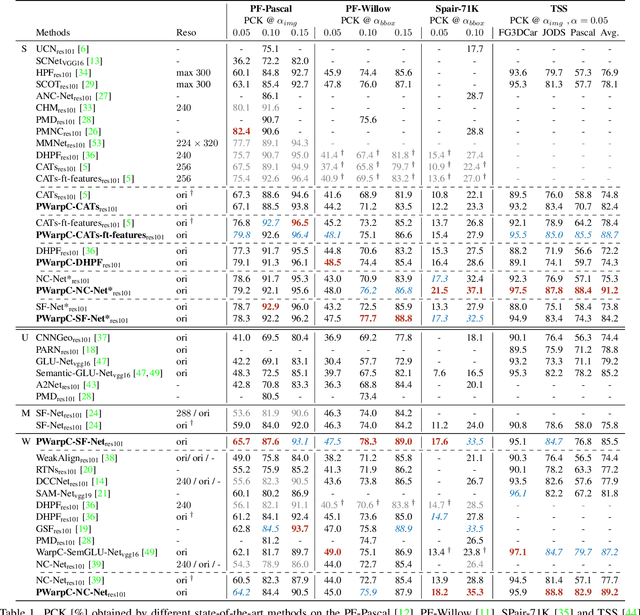
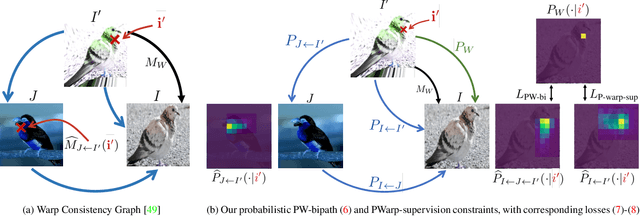
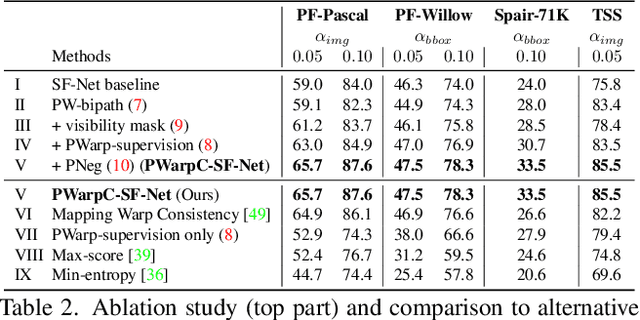
We propose Probabilistic Warp Consistency, a weakly-supervised learning objective for semantic matching. Our approach directly supervises the dense matching scores predicted by the network, encoded as a conditional probability distribution. We first construct an image triplet by applying a known warp to one of the images in a pair depicting different instances of the same object class. Our probabilistic learning objectives are then derived using the constraints arising from the resulting image triplet. We further account for occlusion and background clutter present in real image pairs by extending our probabilistic output space with a learnable unmatched state. To supervise it, we design an objective between image pairs depicting different object classes. We validate our method by applying it to four recent semantic matching architectures. Our weakly-supervised approach sets a new state-of-the-art on four challenging semantic matching benchmarks. Lastly, we demonstrate that our objective also brings substantial improvements in the strongly-supervised regime, when combined with keypoint annotations.
* Accepted at CVPR 2022 code: https://github.com/PruneTruong/DenseMatching
Generative Cooperative Learning for Unsupervised Video Anomaly Detection
Mar 08, 2022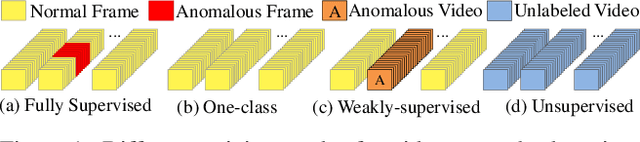
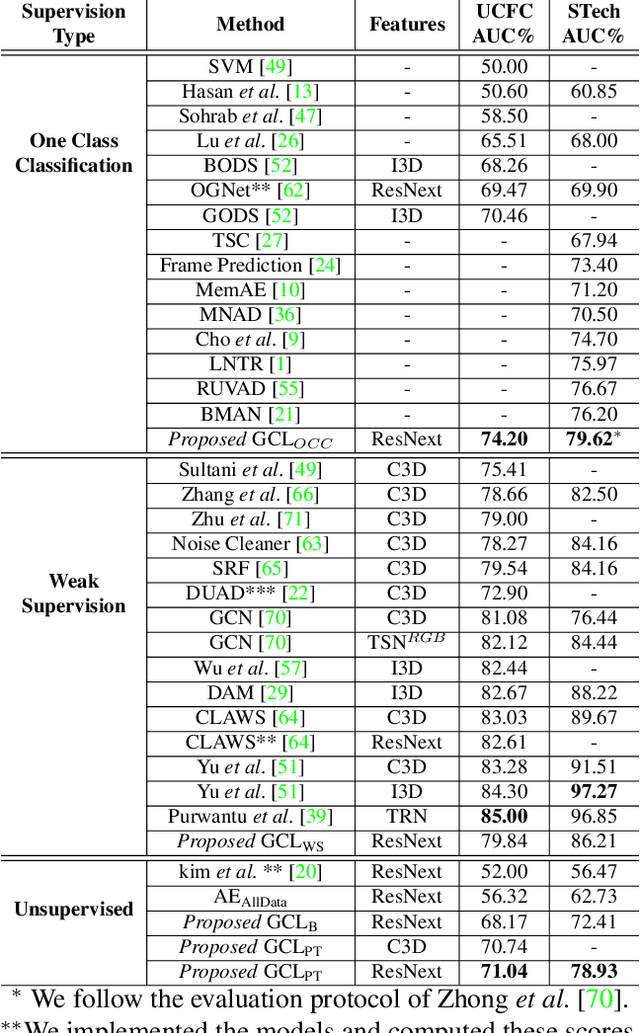
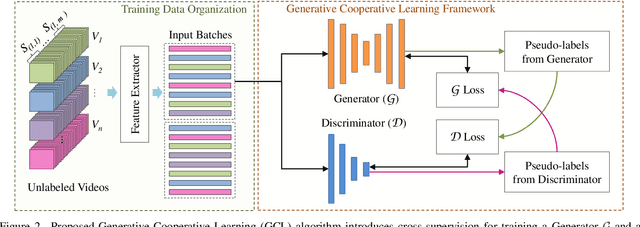
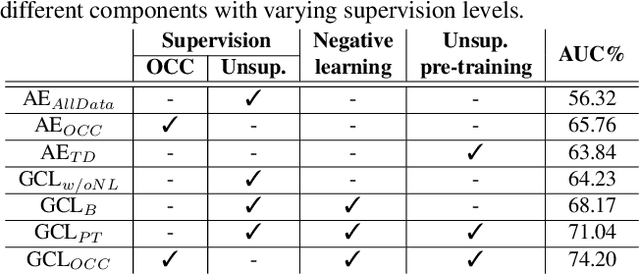
Video anomaly detection is well investigated in weakly-supervised and one-class classification (OCC) settings. However, unsupervised video anomaly detection methods are quite sparse, likely because anomalies are less frequent in occurrence and usually not well-defined, which when coupled with the absence of ground truth supervision, could adversely affect the performance of the learning algorithms. This problem is challenging yet rewarding as it can completely eradicate the costs of obtaining laborious annotations and enable such systems to be deployed without human intervention. To this end, we propose a novel unsupervised Generative Cooperative Learning (GCL) approach for video anomaly detection that exploits the low frequency of anomalies towards building a cross-supervision between a generator and a discriminator. In essence, both networks get trained in a cooperative fashion, thereby allowing unsupervised learning. We conduct extensive experiments on two large-scale video anomaly detection datasets, UCF crime, and ShanghaiTech. Consistent improvement over the existing state-of-the-art unsupervised and OCC methods corroborate the effectiveness of our approach.
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
Feb 07, 2022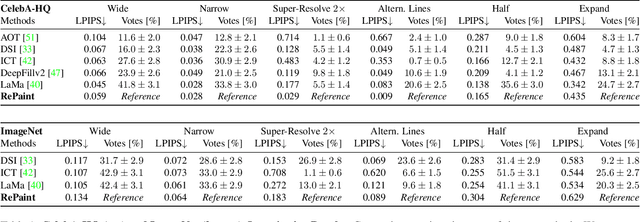
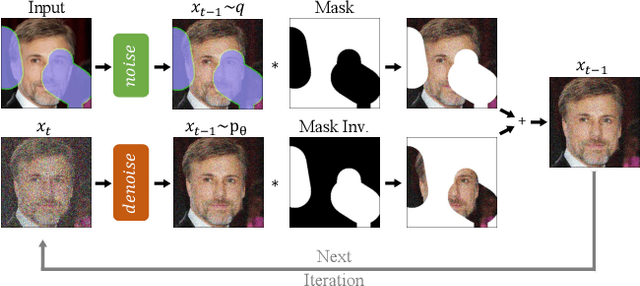


Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks. RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions. Github Repository: git.io/RePaint
SAGA: Stochastic Whole-Body Grasping with Contact
Dec 19, 2021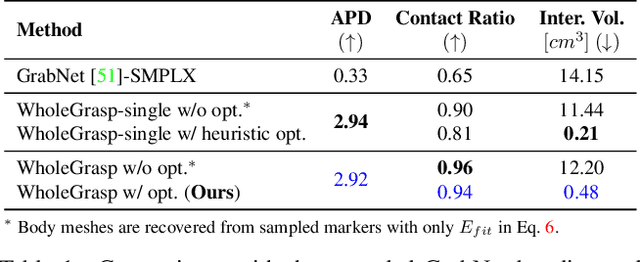

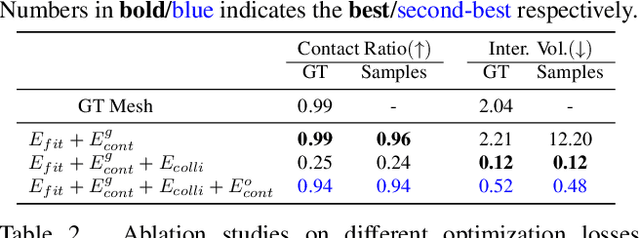
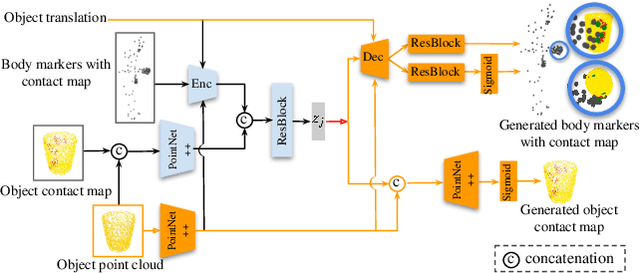
Human grasping synthesis has numerous applications including AR/VR, video games, and robotics. While some methods have been proposed to generate realistic hand-object interaction for object grasping and manipulation, they typically only consider the hand interacting with objects. In this work, our goal is to synthesize whole-body grasping motion. Given a 3D object, we aim to generate diverse and natural whole-body human motions that approach and grasp the object. This task is challenging as it requires modeling both whole-body dynamics and dexterous finger movements. To this end, we propose SAGA (StochAstic whole-body Grasping with contAct) which consists of two key components: (a) Static whole-body grasping pose generation. Specifically, we propose a multi-task generative model, to jointly learn static whole-body grasping poses and human-object contacts. (b) Grasping motion infilling. Given an initial pose and the generated whole-body grasping pose as the starting and ending poses of the motion respectively, we design a novel contact-aware generative motion infilling module to generate a diverse set of grasp-oriented motions. We demonstrate the effectiveness of our method being the first generative framework to synthesize realistic and expressive whole-body motions that approach and grasp randomly placed unseen objects. The code and videos are available at: https://jiahaoplus.github.io/SAGA/saga.html.