 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation
Jun 16, 2022
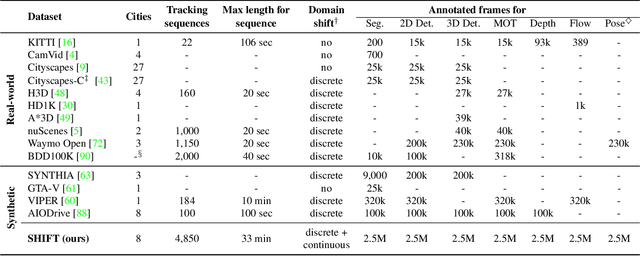
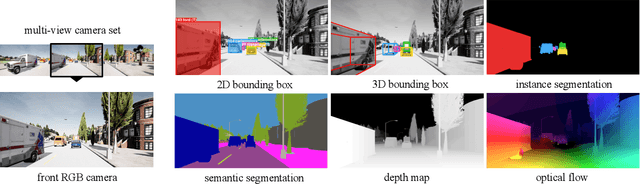

Adapting to a continuously evolving environment is a safety-critical challenge inevitably faced by all autonomous driving systems. Existing image and video driving datasets, however, fall short of capturing the mutable nature of the real world. In this paper, we introduce the largest multi-task synthetic dataset for autonomous driving, SHIFT. It presents discrete and continuous shifts in cloudiness, rain and fog intensity, time of day, and vehicle and pedestrian density. Featuring a comprehensive sensor suite and annotations for several mainstream perception tasks, SHIFT allows investigating the degradation of a perception system performance at increasing levels of domain shift, fostering the development of continuous adaptation strategies to mitigate this problem and assess model robustness and generality. Our dataset and benchmark toolkit are publicly available at www.vis.xyz/shift.
SoftPool++: An Encoder-Decoder Network for Point Cloud Completion
May 08, 2022
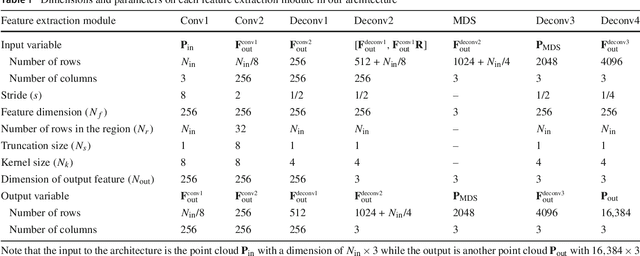
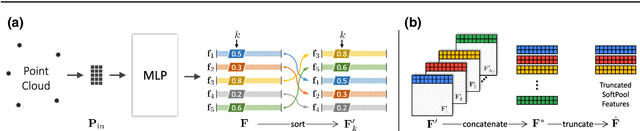
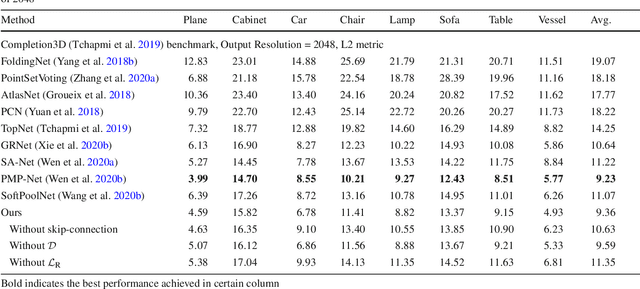
We propose a novel convolutional operator for the task of point cloud completion. One striking characteristic of our approach is that, conversely to related work it does not require any max-pooling or voxelization operation. Instead, the proposed operator used to learn the point cloud embedding in the encoder extracts permutation-invariant features from the point cloud via a soft-pooling of feature activations, which are able to preserve fine-grained geometric details. These features are then passed on to a decoder architecture. Due to the compression in the encoder, a typical limitation of this type of architectures is that they tend to lose parts of the input shape structure. We propose to overcome this limitation by using skip connections specifically devised for point clouds, where links between corresponding layers in the encoder and the decoder are established. As part of these connections, we introduce a transformation matrix that projects the features from the encoder to the decoder and vice-versa. The quantitative and qualitative results on the task of object completion from partial scans on the ShapeNet dataset show that incorporating our approach achieves state-of-the-art performance in shape completion both at low and high resolutions.
* Accepted in International Journal of Computer Vision
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
Apr 01, 2022
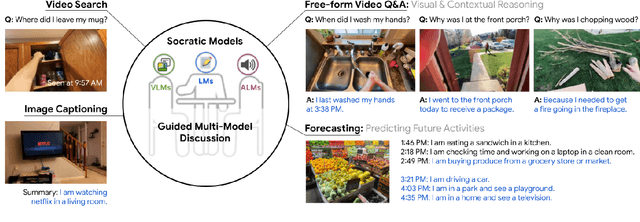
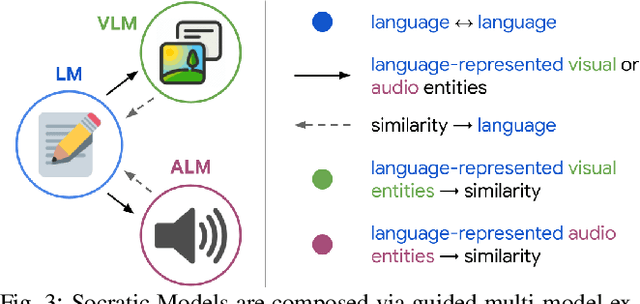
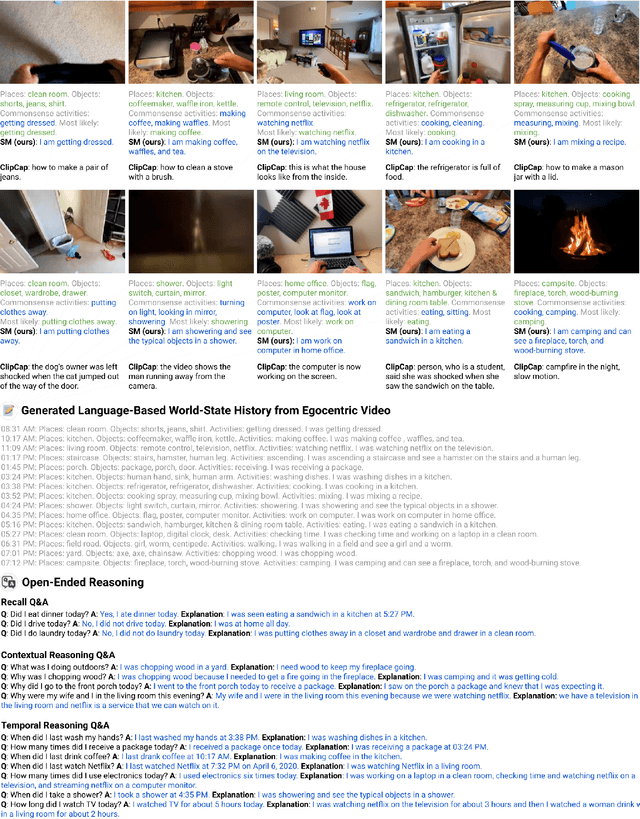
Large foundation models can exhibit unique capabilities depending on the domain of data they are trained on. While these domains are generic, they may only barely overlap. For example, visual-language models (VLMs) are trained on Internet-scale image captions, but large language models (LMs) are further trained on Internet-scale text with no images (e.g. from spreadsheets, to SAT questions). As a result, these models store different forms of commonsense knowledge across different domains. In this work, we show that this model diversity is symbiotic, and can be leveraged to build AI systems with structured Socratic dialogue -- in which new multimodal tasks are formulated as a guided language-based exchange between different pre-existing foundation models, without additional finetuning. In the context of egocentric perception, we present a case study of Socratic Models (SMs) that can provide meaningful results for complex tasks such as generating free-form answers to contextual questions about egocentric video, by formulating video Q&A as short story Q&A, i.e. summarizing the video into a short story, then answering questions about it. Additionally, SMs can generate captions for Internet images, and are competitive with state-of-the-art on zero-shot video-to-text retrieval with 42.8 R@1 on MSR-VTT 1k-A. SMs demonstrate how to compose foundation models zero-shot to capture new multimodal functionalities, without domain-specific data collection. Prototypes are available at socraticmodels.github.io.
Learning Local Displacements for Point Cloud Completion
Mar 30, 2022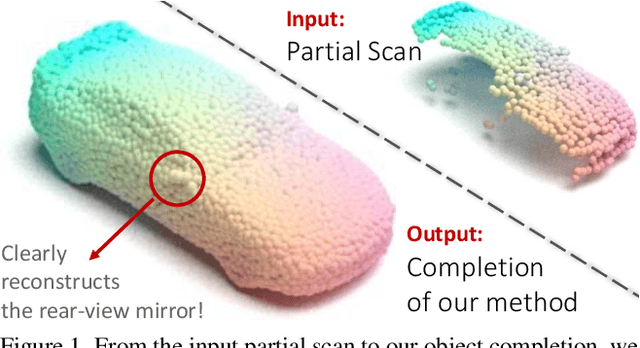
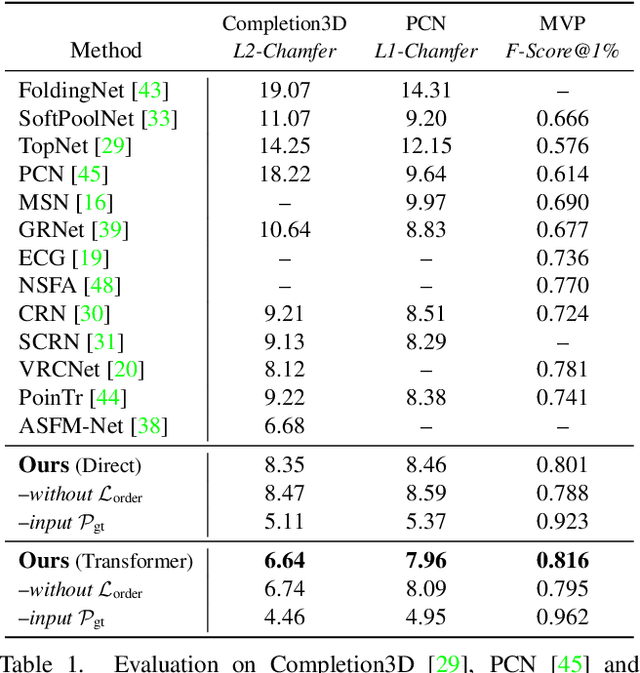
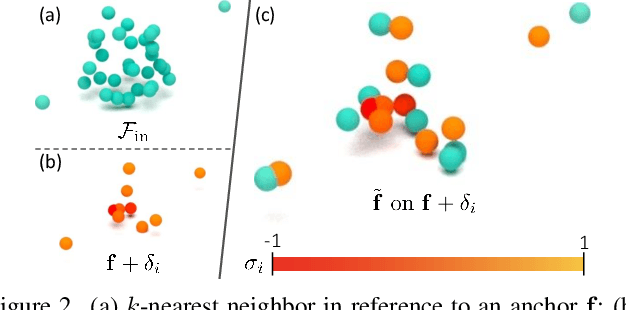
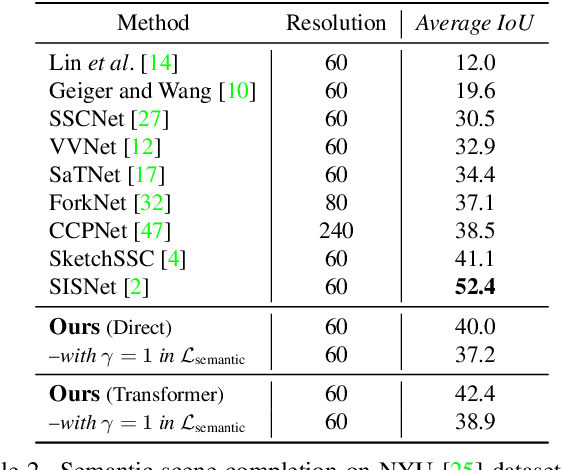
We propose a novel approach aimed at object and semantic scene completion from a partial scan represented as a 3D point cloud. Our architecture relies on three novel layers that are used successively within an encoder-decoder structure and specifically developed for the task at hand. The first one carries out feature extraction by matching the point features to a set of pre-trained local descriptors. Then, to avoid losing individual descriptors as part of standard operations such as max-pooling, we propose an alternative neighbor-pooling operation that relies on adopting the feature vectors with the highest activations. Finally, up-sampling in the decoder modifies our feature extraction in order to increase the output dimension. While this model is already able to achieve competitive results with the state of the art, we further propose a way to increase the versatility of our approach to process point clouds. To this aim, we introduce a second model that assembles our layers within a transformer architecture. We evaluate both architectures on object and indoor scene completion tasks, achieving state-of-the-art performance.
ZebraPose: Coarse to Fine Surface Encoding for 6DoF Object Pose Estimation
Mar 29, 2022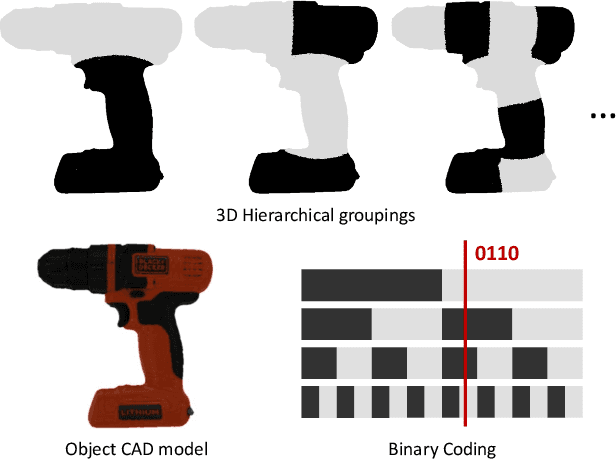
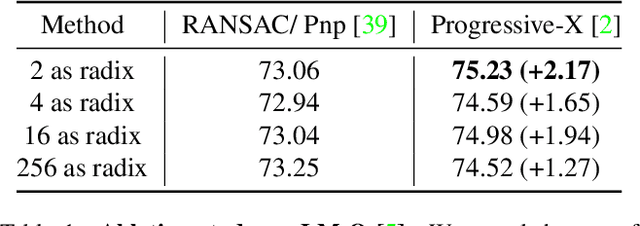
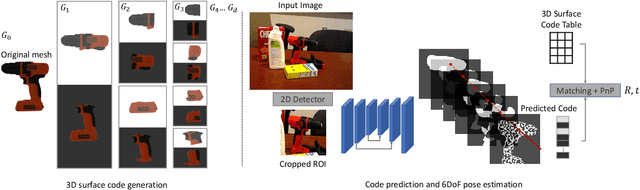

Establishing correspondences from image to 3D has been a key task of 6DoF object pose estimation for a long time. To predict pose more accurately, deeply learned dense maps replaced sparse templates. Dense methods also improved pose estimation in the presence of occlusion. More recently researchers have shown improvements by learning object fragments as segmentation. In this work, we present a discrete descriptor, which can represent the object surface densely. By incorporating a hierarchical binary grouping, we can encode the object surface very efficiently. Moreover, we propose a coarse to fine training strategy, which enables fine-grained correspondence prediction. Finally, by matching predicted codes with object surface and using a PnP solver, we estimate the 6DoF pose. Results on the public LM-O and YCB-V datasets show major improvement over the state of the art w.r.t. ADD(-S) metric, even surpassing RGB-D based methods in some cases.
4D-OR: Semantic Scene Graphs for OR Domain Modeling
Mar 22, 2022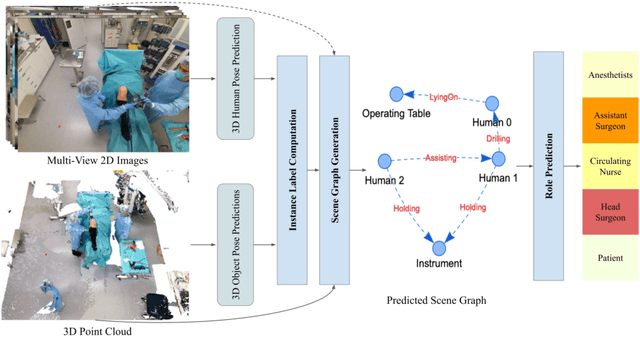


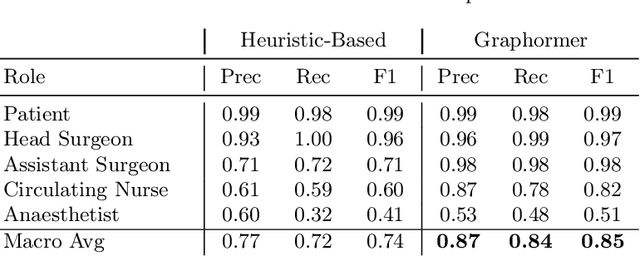
Surgical procedures are conducted in highly complex operating rooms (OR), comprising different actors, devices, and interactions. To date, only medically trained human experts are capable of understanding all the links and interactions in such a demanding environment. This paper aims to bring the community one step closer to automated, holistic and semantic understanding and modeling of OR domain. Towards this goal, for the first time, we propose using semantic scene graphs (SSG) to describe and summarize the surgical scene. The nodes of the scene graphs represent different actors and objects in the room, such as medical staff, patients, and medical equipment, whereas edges are the relationships between them. To validate the possibilities of the proposed representation, we create the first publicly available 4D surgical SSG dataset, 4D-OR, containing ten simulated total knee replacement surgeries recorded with six RGB-D sensors in a realistic OR simulation center. 4D-OR includes 6734 frames and is richly annotated with SSGs, human and object poses, and clinical roles. We propose an end-to-end neural network-based SSG generation pipeline, with a rate of success of 0.75 macro F1, indeed being able to infer semantic reasoning in the OR. We further demonstrate the representation power of our scene graphs by using it for the problem of clinical role prediction, where we achieve 0.85 macro F1. The code and dataset will be made available upon acceptance.
Occlusion-Aware Self-Supervised Monocular 6D Object Pose Estimation
Mar 19, 2022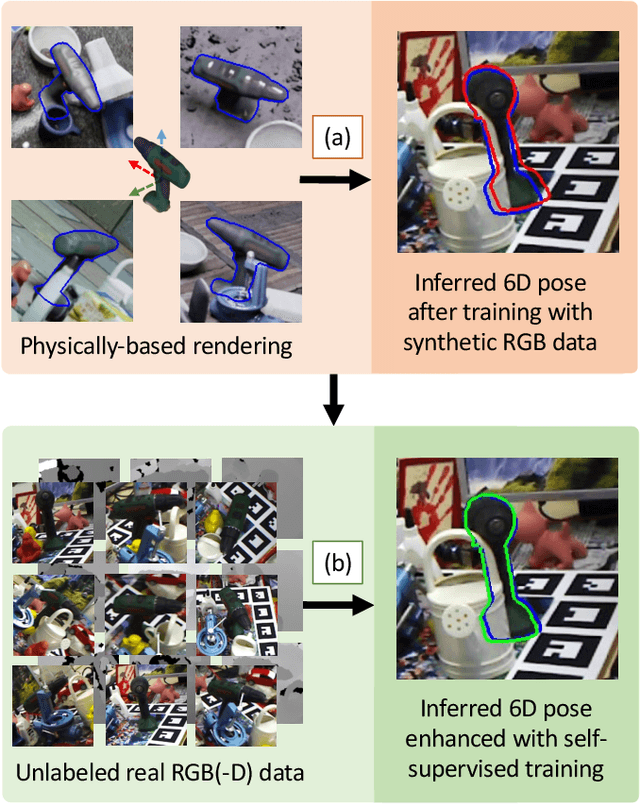

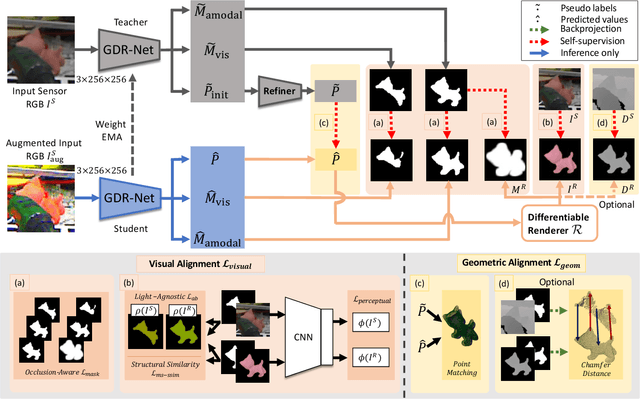

6D object pose estimation is a fundamental yet challenging problem in computer vision. Convolutional Neural Networks (CNNs) have recently proven to be capable of predicting reliable 6D pose estimates even under monocular settings. Nonetheless, CNNs are identified as being extremely data-driven, and acquiring adequate annotations is oftentimes very time-consuming and labor intensive. To overcome this limitation, we propose a novel monocular 6D pose estimation approach by means of self-supervised learning, removing the need for real annotations. After training our proposed network fully supervised with synthetic RGB data, we leverage current trends in noisy student training and differentiable rendering to further self-supervise the model on these unsupervised real RGB(-D) samples, seeking for a visually and geometrically optimal alignment. Moreover, employing both visible and amodal mask information, our self-supervision becomes very robust towards challenging scenarios such as occlusion. Extensive evaluations demonstrate that our proposed self-supervision outperforms all other methods relying on synthetic data or employing elaborate techniques from the domain adaptation realm. Noteworthy, our self-supervised approach consistently improves over its synthetically trained baseline and often almost closes the gap towards its fully supervised counterpart. The code and models are publicly available at https://github.com/THU-DA-6D-Pose-Group/self6dpp.git.
GPV-Pose: Category-level Object Pose Estimation via Geometry-guided Point-wise Voting
Mar 17, 2022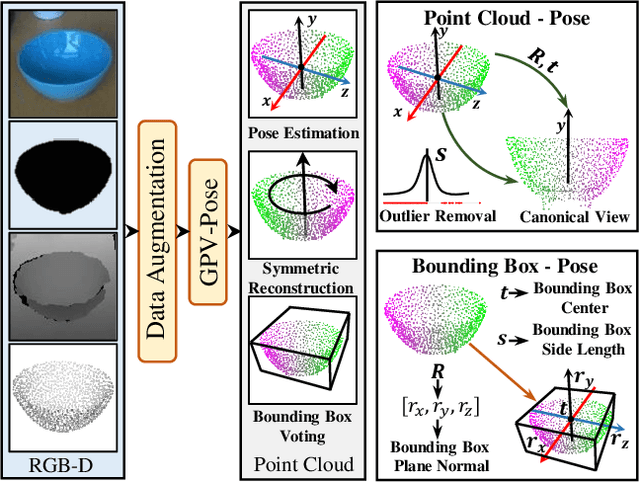
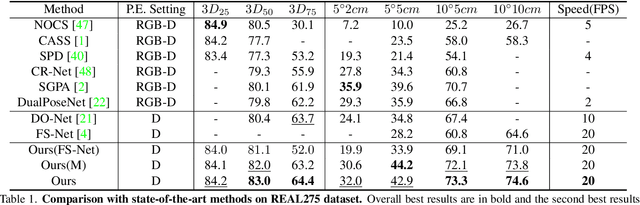
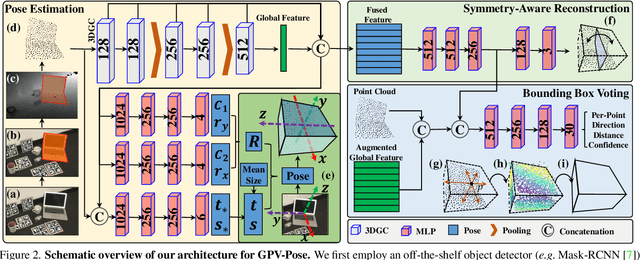
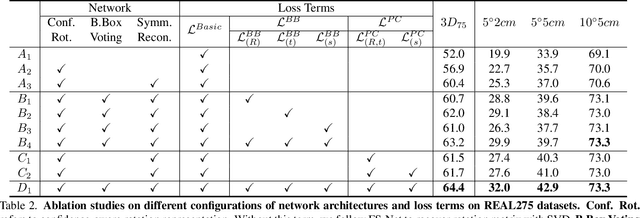
While 6D object pose estimation has recently made a huge leap forward, most methods can still only handle a single or a handful of different objects, which limits their applications. To circumvent this problem, category-level object pose estimation has recently been revamped, which aims at predicting the 6D pose as well as the 3D metric size for previously unseen instances from a given set of object classes. This is, however, a much more challenging task due to severe intra-class shape variations. To address this issue, we propose GPV-Pose, a novel framework for robust category-level pose estimation, harnessing geometric insights to enhance the learning of category-level pose-sensitive features. First, we introduce a decoupled confidence-driven rotation representation, which allows geometry-aware recovery of the associated rotation matrix. Second, we propose a novel geometry-guided point-wise voting paradigm for robust retrieval of the 3D object bounding box. Finally, leveraging these different output streams, we can enforce several geometric consistency terms, further increasing performance, especially for non-symmetric categories. GPV-Pose produces superior results to state-of-the-art competitors on common public benchmarks, whilst almost achieving real-time inference speed at 20 FPS.
From 2D to 3D: Re-thinking Benchmarking of Monocular Depth Prediction
Mar 15, 2022
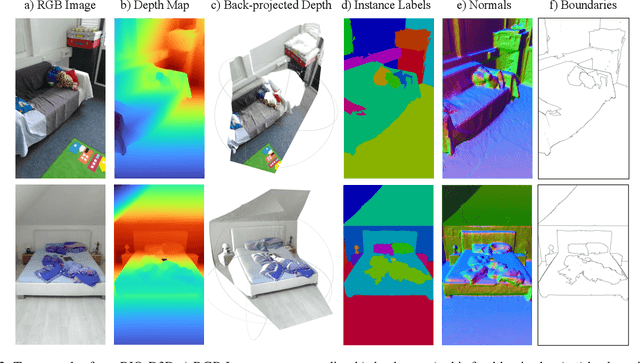
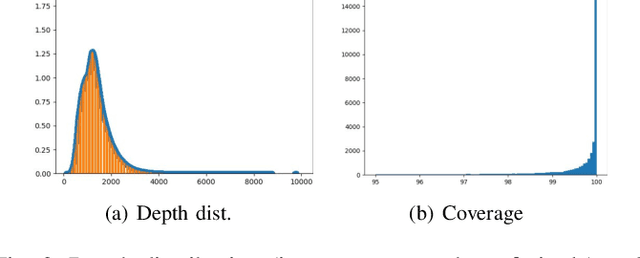

There have been numerous recently proposed methods for monocular depth prediction (MDP) coupled with the equally rapid evolution of benchmarking tools. However, we argue that MDP is currently witnessing benchmark over-fitting and relying on metrics that are only partially helpful to gauge the usefulness of the predictions for 3D applications. This limits the design and development of novel methods that are truly aware of - and improving towards estimating - the 3D structure of the scene rather than optimizing 2D-based distances. In this work, we aim to bring structural awareness to MDP, an inherently 3D task, by exhibiting the limits of evaluation metrics towards assessing the quality of the 3D geometry. We propose a set of metrics well suited to evaluate the 3D geometry of MDP approaches and a novel indoor benchmark, RIO-D3D, crucial for the proposed evaluation methodology. Our benchmark is based on a real-world dataset featuring high-quality rendered depth maps obtained from RGB-D reconstructions. We further demonstrate this to help benchmark the closely-tied task of 3D scene completion.
Time-to-Label: Temporal Consistency for Self-Supervised Monocular 3D Object Detection
Mar 04, 2022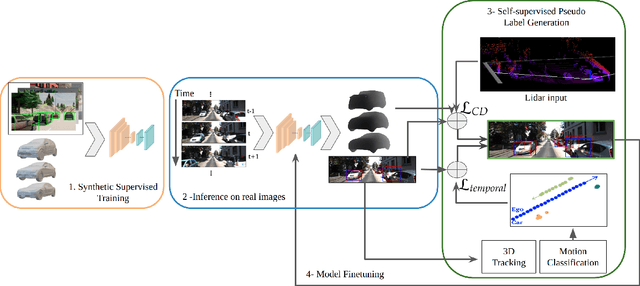
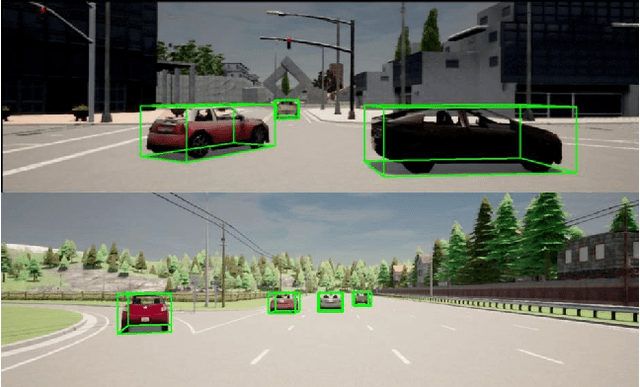
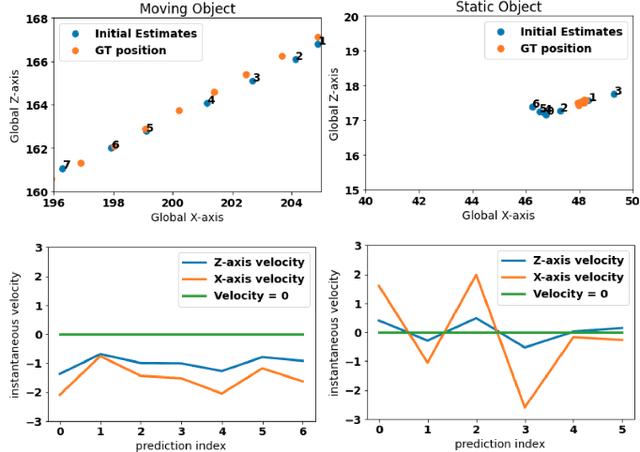

Monocular 3D object detection continues to attract attention due to the cost benefits and wider availability of RGB cameras. Despite the recent advances and the ability to acquire data at scale, annotation cost and complexity still limit the size of 3D object detection datasets in the supervised settings. Self-supervised methods, on the other hand, aim at training deep networks relying on pretext tasks or various consistency constraints. Moreover, other 3D perception tasks (such as depth estimation) have shown the benefits of temporal priors as a self-supervision signal. In this work, we argue that the temporal consistency on the level of object poses, provides an important supervision signal given the strong prior on physical motion. Specifically, we propose a self-supervised loss which uses this consistency, in addition to render-and-compare losses, to refine noisy pose predictions and derive high-quality pseudo labels. To assess the effectiveness of the proposed method, we finetune a synthetically trained monocular 3D object detection model using the pseudo-labels that we generated on real data. Evaluation on the standard KITTI3D benchmark demonstrates that our method reaches competitive performance compared to other monocular self-supervised and supervised methods.