 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowThyself: An Agentic Assistant for LLM Interpretability
Nov 05, 2025We develop KnowThyself, an agentic assistant that advances large language model (LLM) interpretability. Existing tools provide useful insights but remain fragmented and code-intensive. KnowThyself consolidates these capabilities into a chat-based interface, where users can upload models, pose natural language questions, and obtain interactive visualizations with guided explanations. At its core, an orchestrator LLM first reformulates user queries, an agent router further directs them to specialized modules, and the outputs are finally contextualized into coherent explanations. This design lowers technical barriers and provides an extensible platform for LLM inspection. By embedding the whole process into a conversational workflow, KnowThyself offers a robust foundation for accessible LLM interpretability.
Beyond the Uncanny Valley: A Mixed-Method Investigation of Anthropomorphism in Protective Responses to Robot Abuse
Oct 30, 2025Robots with anthropomorphic features are increasingly shaping how humans perceive and morally engage with them. Our research investigates how different levels of anthropomorphism influence protective responses to robot abuse, extending the Computers as Social Actors (CASA) and uncanny valley theories into a moral domain. In an experiment, we invite 201 participants to view videos depicting abuse toward a robot with low (Spider), moderate (Two-Foot), or high (Humanoid) anthropomorphism. To provide a comprehensive analysis, we triangulate three modalities: self-report surveys measuring emotions and uncanniness, physiological data from automated facial expression analysis, and qualitative reflections. Findings indicate that protective responses are not linear. The moderately anthropomorphic Two-Foot robot, rated highest in eeriness and "spine-tingling" sensations consistent with the uncanny valley, elicited the strongest physiological anger expressions. Self-reported anger and guilt are significantly higher for both the Two-Foot and Humanoid robots compared to the Spider. Qualitative findings further reveal that as anthropomorphism increases, moral reasoning shifts from technical assessments of property damage to condemnation of the abuser's character, while governance proposals expand from property law to calls for quasi-animal rights and broader societal responsibility. These results suggest that the uncanny valley does not dampen moral concern but paradoxically heightens protective impulses, offering critical implications for robot design, policy, and future legal frameworks.
I don't Want You to Die: A Shared Responsibility Framework for Safeguarding Child-Robot Companionship
Oct 30, 2025Social robots like Moxie are designed to form strong emotional bonds with children, but their abrupt discontinuation can cause significant struggles and distress to children. When these services end, the resulting harm raises complex questions of who bears responsibility when children's emotional bonds are broken. Using the Moxie shutdown as a case study through a qualitative survey of 72 U.S. participants, our findings show that the responsibility is viewed as a shared duty across the robot company, parents, developers, and government. However, these attributions varied by political ideology and parental status of whether they have children. Participants' perceptions of whether the robot service should continue are highly polarized; supporters propose technical, financial, and governmental pathways for continuity, while opponents cite business realities and risks of unhealthy emotional dependency. Ultimately, this research contributes an empirically grounded shared responsibility framework for safeguarding child-robot companionship by detailing how accountability is distributed and contested, informing concrete design and policy implications to mitigate the emotional harm of robot discontinuation.
Diffusing Trajectory Optimization Problems for Recovery During Multi-Finger Manipulation
Oct 08, 2025Multi-fingered hands are emerging as powerful platforms for performing fine manipulation tasks, including tool use. However, environmental perturbations or execution errors can impede task performance, motivating the use of recovery behaviors that enable normal task execution to resume. In this work, we take advantage of recent advances in diffusion models to construct a framework that autonomously identifies when recovery is necessary and optimizes contact-rich trajectories to recover. We use a diffusion model trained on the task to estimate when states are not conducive to task execution, framed as an out-of-distribution detection problem. We then use diffusion sampling to project these states in-distribution and use trajectory optimization to plan contact-rich recovery trajectories. We also propose a novel diffusion-based approach that distills this process to efficiently diffuse the full parameterization, including constraints, goal state, and initialization, of the recovery trajectory optimization problem, saving time during online execution. We compare our method to a reinforcement learning baseline and other methods that do not explicitly plan contact interactions, including on a hardware screwdriver-turning task where we show that recovering using our method improves task performance by 96% and that ours is the only method evaluated that can attempt recovery without causing catastrophic task failure. Videos can be found at https://dtourrecovery.github.io/.
What Matters in RL-Based Methods for Object-Goal Navigation? An Empirical Study and A Unified Framework
Oct 02, 2025



Object-Goal Navigation (ObjectNav) is a critical component toward deploying mobile robots in everyday, uncontrolled environments such as homes, schools, and workplaces. In this context, a robot must locate target objects in previously unseen environments using only its onboard perception. Success requires the integration of semantic understanding, spatial reasoning, and long-horizon planning, which is a combination that remains extremely challenging. While reinforcement learning (RL) has become the dominant paradigm, progress has spanned a wide range of design choices, yet the field still lacks a unifying analysis to determine which components truly drive performance. In this work, we conduct a large-scale empirical study of modular RL-based ObjectNav systems, decomposing them into three key components: perception, policy, and test-time enhancement. Through extensive controlled experiments, we isolate the contribution of each and uncover clear trends: perception quality and test-time strategies are decisive drivers of performance, whereas policy improvements with current methods yield only marginal gains. Building on these insights, we propose practical design guidelines and demonstrate an enhanced modular system that surpasses State-of-the-Art (SotA) methods by 6.6% on SPL and by a 2.7% success rate. We also introduce a human baseline under identical conditions, where experts achieve an average 98% success, underscoring the gap between RL agents and human-level navigation. Our study not only sets the SotA performance but also provides principled guidance for future ObjectNav development and evaluation.
From Seeing to Predicting: A Vision-Language Framework for Trajectory Forecasting and Controlled Video Generation
Oct 01, 2025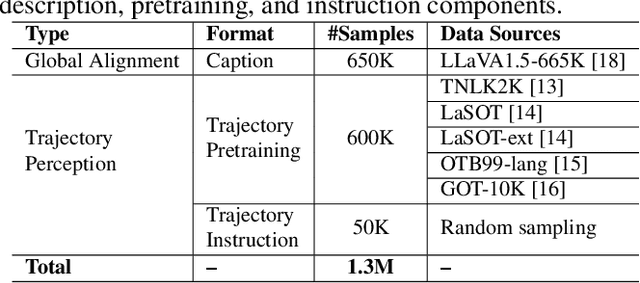
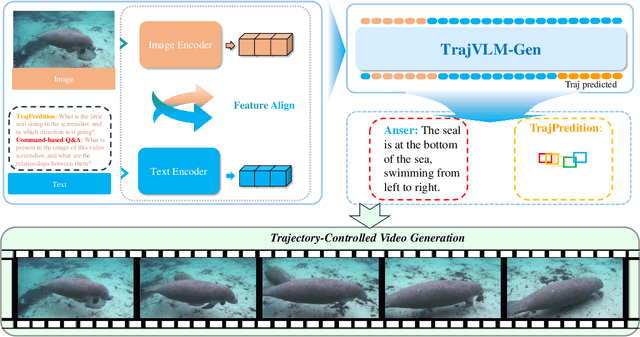


Current video generation models produce physically inconsistent motion that violates real-world dynamics. We propose TrajVLM-Gen, a two-stage framework for physics-aware image-to-video generation. First, we employ a Vision Language Model to predict coarse-grained motion trajectories that maintain consistency with real-world physics. Second, these trajectories guide video generation through attention-based mechanisms for fine-grained motion refinement. We build a trajectory prediction dataset based on video tracking data with realistic motion patterns. Experiments on UCF-101 and MSR-VTT demonstrate that TrajVLM-Gen outperforms existing methods, achieving competitive FVD scores of 545 on UCF-101 and 539 on MSR-VTT.
AnoF-Diff: One-Step Diffusion-Based Anomaly Detection for Forceful Tool Use
Sep 18, 2025Multivariate time-series anomaly detection, which is critical for identifying unexpected events, has been explored in the field of machine learning for several decades. However, directly applying these methods to data from forceful tool use tasks is challenging because streaming sensor data in the real world tends to be inherently noisy, exhibits non-stationary behavior, and varies across different tasks and tools. To address these challenges, we propose a method, AnoF-Diff, based on the diffusion model to extract force-torque features from time-series data and use force-torque features to detect anomalies. We compare our method with other state-of-the-art methods in terms of F1-score and Area Under the Receiver Operating Characteristic curve (AUROC) on four forceful tool-use tasks, demonstrating that our method has better performance and is more robust to a noisy dataset. We also propose the method of parallel anomaly score evaluation based on one-step diffusion and demonstrate how our method can be used for online anomaly detection in several forceful tool use experiments.
From Orthomosaics to Raw UAV Imagery: Enhancing Palm Detection and Crown-Center Localization
Sep 15, 2025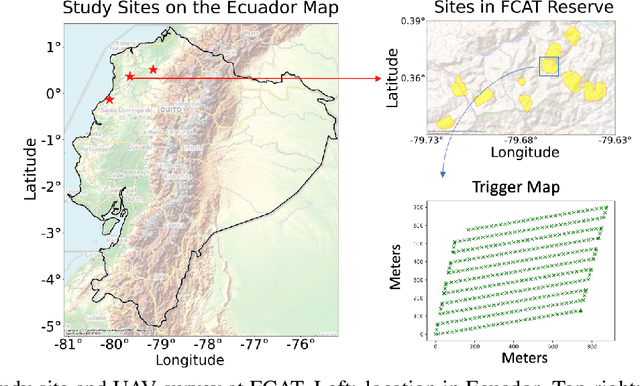
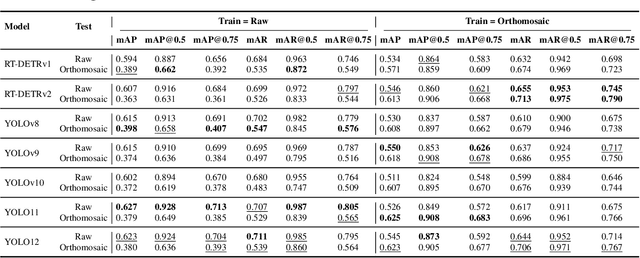
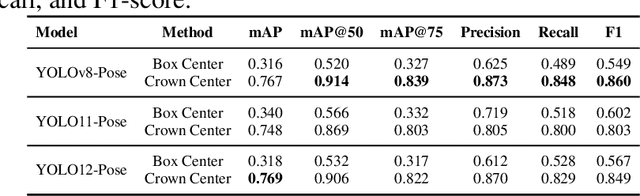

Accurate mapping of individual trees is essential for ecological monitoring and forest management. Orthomosaic imagery from unmanned aerial vehicles (UAVs) is widely used, but stitching artifacts and heavy preprocessing limit its suitability for field deployment. This study explores the use of raw UAV imagery for palm detection and crown-center localization in tropical forests. Two research questions are addressed: (1) how detection performance varies across orthomosaic and raw imagery, including within-domain and cross-domain transfer, and (2) to what extent crown-center annotations improve localization accuracy beyond bounding-box centroids. Using state-of-the-art detectors and keypoint models, we show that raw imagery yields superior performance in deployment-relevant scenarios, while orthomosaics retain value for robust cross-domain generalization. Incorporating crown-center annotations in training further improves localization and provides precise tree positions for downstream ecological analyses. These findings offer practical guidance for UAV-based biodiversity and conservation monitoring.
rStar2-Agent: Agentic Reasoning Technical Report
Aug 28, 2025We introduce rStar2-Agent, a 14B math reasoning model trained with agentic reinforcement learning to achieve frontier-level performance. Beyond current long CoT, the model demonstrates advanced cognitive behaviors, such as thinking carefully before using Python coding tools and reflecting on code execution feedback to autonomously explore, verify, and refine intermediate steps in complex problem-solving. This capability is enabled through three key innovations that makes agentic RL effective at scale: (i) an efficient RL infrastructure with a reliable Python code environment that supports high-throughput execution and mitigates the high rollout costs, enabling training on limited GPU resources (64 MI300X GPUs); (ii) GRPO-RoC, an agentic RL algorithm with a Resample-on-Correct rollout strategy that addresses the inherent environment noises from coding tools, allowing the model to reason more effectively in a code environment; (iii) An efficient agent training recipe that starts with non-reasoning SFT and progresses through multi-RL stages, yielding advanced cognitive abilities with minimal compute cost. To this end, rStar2-Agent boosts a pre-trained 14B model to state of the art in only 510 RL steps within one week, achieving average pass@1 scores of 80.6% on AIME24 and 69.8% on AIME25, surpassing DeepSeek-R1 (671B) with significantly shorter responses. Beyond mathematics, rStar2-Agent-14B also demonstrates strong generalization to alignment, scientific reasoning, and agentic tool-use tasks. Code and training recipes are available at https://github.com/microsoft/rStar.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.