 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBudgetDraft: Acceptance-Aware Multi-View Training for Sparse-KV Speculative Decoding
May 29, 2026Speculative decoding speeds up autoregressive decoding by using a drafter to propose multiple tokens that a verifier validates in parallel. In resource-constrained deployments, the drafter uses a sparse KV cache to limit peak GPU memory and end-to-end latency under a fixed KV budget, while the verifier keeps a full KV cache. Mid-to-long context inference (4K--16K context length) is common in real applications. However, naive sparse/full speculative decoding suffers from the sparse/full mismatch as context length grows, causing the acceptance rate to drop quickly. We propose BudgetDraft, a multi-view sparse training method for sparse drafting in mid-to-long inference. The drafter is exposed to multiple sampled KV budgets during training and learns to align each sparse view with one shared full-cache teacher target. BudgetDraft combines an acceptance-aware loss on a full-cache branch with a multi-view loss on a sparse-cache branch, producing a single budget-robust drafter that recovers acceptance across sparsity levels without extra inference-time components. Experimental results on PG-19, LongBench, and LWM show that BudgetDraft achieves up to 6.55x, 4.46x, and 2.10x end-to-end speedup vs AR at 4K, 8K, and 16K context lengths, while keeping the inference pipeline memory-friendly.
Beyond Text Prompts: Visual-to-Visual Generation as A Unified Paradigm
May 12, 2026Humans often specify and create through visual artifacts: typography sheets, sketches, reference images, and annotated scenes. Yet modern visual generators still ask users to serialize this intent into text, a bottleneck that compresses signals like spatial structure, exact appearance, and glyph shape. We propose \textbf{\emph{visual-to-visual} (V2V)} generation, in which the user conditions a generative model with a visual specification page rather than a text prompt. The page is not an edit target, but a visual document that specifies the desired output. We introduce \textbf{V2V-Zero}, a training-free framework that exposes this interface in existing vision-language model (VLM) conditioned generators by replacing text-only conditioning with final-layer hidden states extracted from visual pages, exploiting the fact that the frozen VLM already maps both text and images into the generator's conditioning space. On GenEval, V2V-Zero reaches 0.85 with a frozen Qwen-Image backbone, closely matching its optimized text-to-image performance without fine-tuning. To evaluate the broader V2V space, we introduce \textbf{Simple-V2V Bench}, spanning seven visual-conditioning tasks and seven models, including GPT Image 2, Nano Banana 2, Seedream 5.0 Lite, open-weight baselines, and a video extension. V2V-Zero scores 32.7/100, outperforming evaluated open-weight image baselines and revealing a clear capability hierarchy: attribute binding is strong, content generation is unreliable, and structural control remains hard even for commercial systems. A HunyuanVideo-1.5 extension scores 20.2/100, showing the interface transfers beyond images. Mechanistic analysis shows the default reasoning path is primarily visually routed, with 95.0\% of conditioning-token attention mass on visual-page hidden states.
Learning Where to Embed: Noise-Aware Positional Embedding for Query Retrieval in Small-Object Detection
Apr 16, 2026Transformer-based detectors have advanced small-object detection, but they often remain inefficient and vulnerable to background-induced query noise, which motivates deep decoders to refine low-quality queries. We present HELP (Heatmap-guided Embedding Learning Paradigm), a noise-aware positional-semantic fusion framework that studies where to embed positional information by selectively preserving positional encodings in foreground-salient regions while suppressing background clutter. Within HELP, we introduce Heatmap-guided Positional Embedding (HPE) as the core embedding mechanism and visualize it with a heatbar for interpretable diagnosis and fine-tuning. HPE is integrated into both the encoder and decoder: it guides noise-suppressed feature encoding by injecting heatmap-aware positional encoding, and it enables high-quality query retrieval by filtering background-dominant embeddings via a gradient-based mask filter before decoding. To address feature sparsity in complex small targets, we integrate Linear-Snake Convolution to enrich retrieval-relevant representations. The gradient-based heatmap supervision is used during training only, incurring no additional gradient computation at inference. As a result, our design reduces decoder layers from eight to three and achieves a 59.4% parameter reduction (66.3M vs. 163M) while maintaining consistent accuracy gains under a reduced compute budget across benchmarks. Code Repository: https://github.com/yidimopozhibai/Noise-Suppressed-Query-Retrieval
SphUnc: Hyperspherical Uncertainty Decomposition and Causal Identification via Information Geometry
Mar 01, 2026Reliable decision-making in complex multi-agent systems requires calibrated predictions and interpretable uncertainty. We introduce SphUnc, a unified framework combining hyperspherical representation learning with structural causal modeling. The model maps features to unit hypersphere latents using von Mises-Fisher distributions, decomposing uncertainty into epistemic and aleatoric components through information-geometric fusion. A structural causal model on spherical latents enables directed influence identification and interventional reasoning via sample-based simulation. Empirical evaluations on social and affective benchmarks demonstrate improved accuracy, better calibration, and interpretable causal signals, establishing a geometric-causal foundation for uncertainty-aware reasoning in multi-agent settings with higher-order interactions.
NeuroSymActive: Differentiable Neural-Symbolic Reasoning with Active Exploration for Knowledge Graph Question Answering
Feb 17, 2026Large pretrained language models and neural reasoning systems have advanced many natural language tasks, yet they remain challenged by knowledge-intensive queries that require precise, structured multi-hop inference. Knowledge graphs provide a compact symbolic substrate for factual grounding, but integrating graph structure with neural models is nontrivial: naively embedding graph facts into prompts leads to inefficiency and fragility, while purely symbolic or search-heavy approaches can be costly in retrievals and lack gradient-based refinement. We introduce NeuroSymActive, a modular framework that combines a differentiable neural-symbolic reasoning layer with an active, value-guided exploration controller for Knowledge Graph Question Answering. The method couples soft-unification style symbolic modules with a neural path evaluator and a Monte-Carlo style exploration policy that prioritizes high-value path expansions. Empirical results on standard KGQA benchmarks show that NeuroSymActive attains strong answer accuracy while reducing the number of expensive graph lookups and model calls compared to common retrieval-augmented baselines.
StoryState: Agent-Based State Control for Consistent and Editable Storybooks
Feb 01, 2026Large multimodal models have enabled one-click storybook generation, where users provide a short description and receive a multi-page illustrated story. However, the underlying story state, such as characters, world settings, and page-level objects, remains implicit, making edits coarse-grained and often breaking visual consistency. We present StoryState, an agent-based orchestration layer that introduces an explicit and editable story state on top of training-free text-to-image generation. StoryState represents each story as a structured object composed of a character sheet, global settings, and per-page scene constraints, and employs a small set of LLM agents to maintain this state and derive 1Prompt1Story-style prompts for generation and editing. Operating purely through prompts, StoryState is model-agnostic and compatible with diverse generation backends. System-level experiments on multi-page editing tasks show that StoryState enables localized page edits, improves cross-page consistency, and reduces unintended changes, interaction turns, and editing time compared to 1Prompt1Story, while approaching the one-shot consistency of Gemini Storybook. Code is available at https://github.com/YuZhenyuLindy/StoryState
ReDiStory: Region-Disentangled Diffusion for Consistent Visual Story Generation
Feb 01, 2026Generating coherent visual stories requires maintaining subject identity across multiple images while preserving frame-specific semantics. Recent training-free methods concatenate identity and frame prompts into a unified representation, but this often introduces inter-frame semantic interference that weakens identity preservation in complex stories. We propose ReDiStory, a training-free framework that improves multi-frame story generation via inference-time prompt embedding reorganization. ReDiStory explicitly decomposes text embeddings into identity-related and frame-specific components, then decorrelates frame embeddings by suppressing shared directions across frames. This reduces cross-frame interference without modifying diffusion parameters or requiring additional supervision. Under identical diffusion backbones and inference settings, ReDiStory improves identity consistency while maintaining prompt fidelity. Experiments on the ConsiStory+ benchmark show consistent gains over 1Prompt1Story on multiple identity consistency metrics. Code is available at: https://github.com/YuZhenyuLindy/ReDiStory
From Orthomosaics to Raw UAV Imagery: Enhancing Palm Detection and Crown-Center Localization
Sep 15, 2025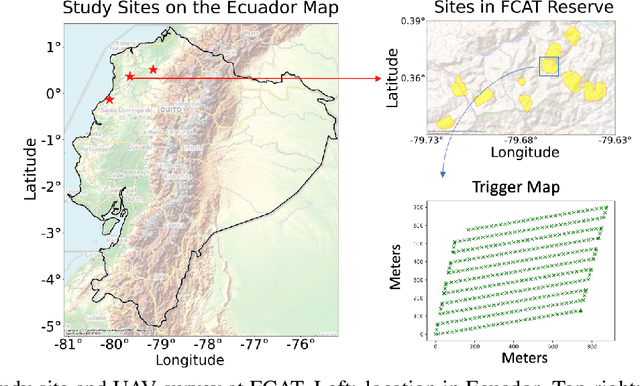
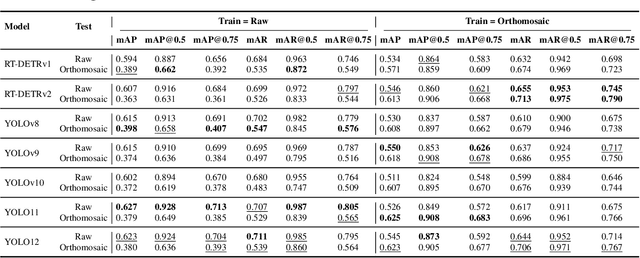
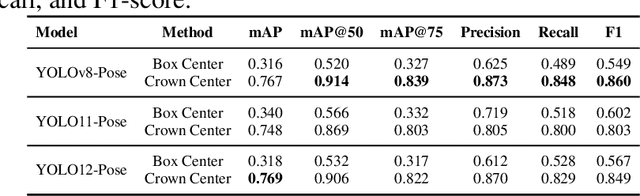

Accurate mapping of individual trees is essential for ecological monitoring and forest management. Orthomosaic imagery from unmanned aerial vehicles (UAVs) is widely used, but stitching artifacts and heavy preprocessing limit its suitability for field deployment. This study explores the use of raw UAV imagery for palm detection and crown-center localization in tropical forests. Two research questions are addressed: (1) how detection performance varies across orthomosaic and raw imagery, including within-domain and cross-domain transfer, and (2) to what extent crown-center annotations improve localization accuracy beyond bounding-box centroids. Using state-of-the-art detectors and keypoint models, we show that raw imagery yields superior performance in deployment-relevant scenarios, while orthomosaics retain value for robust cross-domain generalization. Incorporating crown-center annotations in training further improves localization and provides precise tree positions for downstream ecological analyses. These findings offer practical guidance for UAV-based biodiversity and conservation monitoring.
Cott-ADNet: Lightweight Real-Time Cotton Boll and Flower Detection Under Field Conditions
Sep 15, 2025



Cotton is one of the most important natural fiber crops worldwide, yet harvesting remains limited by labor-intensive manual picking, low efficiency, and yield losses from missing the optimal harvest window. Accurate recognition of cotton bolls and their maturity is therefore essential for automation, yield estimation, and breeding research. We propose Cott-ADNet, a lightweight real-time detector tailored to cotton boll and flower recognition under complex field conditions. Building on YOLOv11n, Cott-ADNet enhances spatial representation and robustness through improved convolutional designs, while introducing two new modules: a NeLU-enhanced Global Attention Mechanism to better capture weak and low-contrast features, and a Dilated Receptive Field SPPF to expand receptive fields for more effective multi-scale context modeling at low computational cost. We curate a labeled dataset of 4,966 images, and release an external validation set of 1,216 field images to support future research. Experiments show that Cott-ADNet achieves 91.5% Precision, 89.8% Recall, 93.3% mAP50, 71.3% mAP, and 90.6% F1-Score with only 7.5 GFLOPs, maintaining stable performance under multi-scale and rotational variations. These results demonstrate Cott-ADNet as an accurate and efficient solution for in-field deployment, and thus provide a reliable basis for automated cotton harvesting and high-throughput phenotypic analysis. Code and dataset is available at https://github.com/SweefongWong/Cott-ADNet.
Blind Restoration of High-Resolution Ultrasound Video
May 20, 2025Ultrasound imaging is widely applied in clinical practice, yet ultrasound videos often suffer from low signal-to-noise ratios (SNR) and limited resolutions, posing challenges for diagnosis and analysis. Variations in equipment and acquisition settings can further exacerbate differences in data distribution and noise levels, reducing the generalizability of pre-trained models. This work presents a self-supervised ultrasound video super-resolution algorithm called Deep Ultrasound Prior (DUP). DUP employs a video-adaptive optimization process of a neural network that enhances the resolution of given ultrasound videos without requiring paired training data while simultaneously removing noise. Quantitative and visual evaluations demonstrate that DUP outperforms existing super-resolution algorithms, leading to substantial improvements for downstream applications.