 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLUME: Probabilistic Latent Unified World Modeling and Parameter Estimation for Multi-Finger Manipulation
Jun 09, 2026Dexterous manipulation with multi-finger hands can be sensitive to physical parameters such as object shape, pose, and friction coefficients. While simulation enables large-scale data collection with known parameter values, simulation-trained policies must still handle uncertainty at deployment, where the true parameters and therefore the true dynamics are unknown. Standard domain randomization strategies may be insufficient for precise tasks like screwdriver turning, as manipulation strategies may need to change depending on specific parameter values. To address this, we propose Probabilistic Latent Unified world Modeling and parameter Estimation (PLUME), a world model that jointly learns to evolve a belief over parameter values as well as the system dynamics conditioned on those parameters. We learn a latent space to jointly represent multiple qualitatively different physical parameters along with rewards, themselves functions of partially-observable variables, to inform planning. Our novel learning framework leads to efficient alignment of the world model to true dynamics through online parameter inference as opposed to re-training or fine-tuning. We evaluate our method on simulated screwdriver turning, valve turning, bucket lifting, and disk flicking tasks, as well as a hardware screwdriver turning task, where we achieve successful zero-shot transfer of our simulation-trained policy and outperform state-of-the-art offline reinforcement learning and world-model-augmented behavior cloning baselines. Please see our website at https://plume-world-model.github.io for videos.
Bidirectional Human-Robot Communication for Physical Human-Robot Interaction
Jan 15, 2026Effective physical human-robot interaction requires systems that are not only adaptable to user preferences but also transparent about their actions. This paper introduces BRIDGE, a system for bidirectional human-robot communication in physical assistance. Our method allows users to modify a robot's planned trajectory -- position, velocity, and force -- in real time using natural language. We utilize a large language model (LLM) to interpret any trajectory modifications implied by user commands in the context of the planned motion and conversation history. Importantly, our system provides verbal feedback in response to the user, either assuring any resulting changes or posing a clarifying question. We evaluated our method in a user study with 18 older adults across three assistive tasks, comparing BRIDGE to an ablation without verbal feedback and a baseline. Results show that participants successfully used the system to modify trajectories in real time. Moreover, the bidirectional feedback led to significantly higher ratings of interactivity and transparency, demonstrating that the robot's verbal response is critical for a more intuitive user experience. Videos and code can be found on our project website: https://bidir-comm.github.io/
Diffusing Trajectory Optimization Problems for Recovery During Multi-Finger Manipulation
Oct 08, 2025Multi-fingered hands are emerging as powerful platforms for performing fine manipulation tasks, including tool use. However, environmental perturbations or execution errors can impede task performance, motivating the use of recovery behaviors that enable normal task execution to resume. In this work, we take advantage of recent advances in diffusion models to construct a framework that autonomously identifies when recovery is necessary and optimizes contact-rich trajectories to recover. We use a diffusion model trained on the task to estimate when states are not conducive to task execution, framed as an out-of-distribution detection problem. We then use diffusion sampling to project these states in-distribution and use trajectory optimization to plan contact-rich recovery trajectories. We also propose a novel diffusion-based approach that distills this process to efficiently diffuse the full parameterization, including constraints, goal state, and initialization, of the recovery trajectory optimization problem, saving time during online execution. We compare our method to a reinforcement learning baseline and other methods that do not explicitly plan contact interactions, including on a hardware screwdriver-turning task where we show that recovering using our method improves task performance by 96% and that ours is the only method evaluated that can attempt recovery without causing catastrophic task failure. Videos can be found at https://dtourrecovery.github.io/.
CoRI: Synthesizing Communication of Robot Intent for Physical Human-Robot Interaction
May 26, 2025Clear communication of robot intent fosters transparency and interpretability in physical human-robot interaction (pHRI), particularly during assistive tasks involving direct human-robot contact. We introduce CoRI, a pipeline that automatically generates natural language communication of a robot's upcoming actions directly from its motion plan and visual perception. Our pipeline first processes the robot's image view to identify human poses and key environmental features. It then encodes the planned 3D spatial trajectory (including velocity and force) onto this view, visually grounding the path and its dynamics. CoRI queries a vision-language model with this visual representation to interpret the planned action within the visual context before generating concise, user-directed statements, without relying on task-specific information. Results from a user study involving robot-assisted feeding, bathing, and shaving tasks across two different robots indicate that CoRI leads to statistically significant difference in communication clarity compared to a baseline communication strategy. Specifically, CoRI effectively conveys not only the robot's high-level intentions but also crucial details about its motion and any collaborative user action needed.
GeoDEx: A Unified Geometric Framework for Tactile Dexterous and Extrinsic Manipulation under Force Uncertainty
May 01, 2025Sense of touch that allows robots to detect contact and measure interaction forces enables them to perform challenging tasks such as grasping fragile objects or using tools. Tactile sensors in theory can equip the robots with such capabilities. However, accuracy of the measured forces is not on a par with those of the force sensors due to the potential calibration challenges and noise. This has limited the values these sensors can offer in manipulation applications that require force control. In this paper, we introduce GeoDEx, a unified estimation, planning, and control framework using geometric primitives such as plane, cone and ellipsoid, which enables dexterous as well as extrinsic manipulation in the presence of uncertain force readings. Through various experimental results, we show that while relying on direct inaccurate and noisy force readings from tactile sensors results in unstable or failed manipulation, our method enables successful grasping and extrinsic manipulation of different objects. Additionally, compared to directly running optimization using SOCP (Second Order Cone Programming), planning and force estimation using our framework achieves a 14x speed-up.
On the Feasibility of A Mixed-Method Approach for Solving Long Horizon Task-Oriented Dexterous Manipulation
Oct 09, 2024



In-hand manipulation of tools using dexterous hands in real-world is an underexplored problem in the literature. In addition to more complex geometry and larger size of the tools compared to more commonly used objects like cubes or cylinders, task oriented in-hand tool manipulation involves many sub-tasks to be performed sequentially. This may involve reaching to the tool, picking it up, reorienting it in hand with or without regrasping to reach to a desired final grasp appropriate for the tool usage, and carrying the tool to the desired pose. Research on long-horizon manipulation using dexterous hands is rather limited and the existing work focus on learning the individual sub-tasks using a method like reinforcement learning (RL) and combine the policies for different subtasks to perform a long horizon task. However, in general a single method may not be the best for all the sub-tasks, and this can be more pronounced when dealing with multi-fingered hands manipulating objects with complex geometry like tools. In this paper, we investigate the use of a mixed-method approach to solve for the long-horizon task of tool usage and we use imitation learning, reinforcement learning and model based control. We also discuss a new RL-based teacher-student framework that combines real world data into offline training. We show that our proposed approach for each subtask outperforms the commonly adopted reinforcement learning approach across different subtasks and in performing the long horizon task in simulation. Finally we show the successful transferability to real world.
Diffusion-Informed Probabilistic Contact Search for Multi-Finger Manipulation
Oct 01, 2024



Planning contact-rich interactions for multi-finger manipulation is challenging due to the high-dimensionality and hybrid nature of dynamics. Recent advances in data-driven methods have shown promise, but are sensitive to the quality of training data. Combining learning with classical methods like trajectory optimization and search adds additional structure to the problem and domain knowledge in the form of constraints, which can lead to outperforming the data on which models are trained. We present Diffusion-Informed Probabilistic Contact Search (DIPS), which uses an A* search to plan a sequence of contact modes informed by a diffusion model. We train the diffusion model on a dataset of demonstrations consisting of contact modes and trajectories generated by a trajectory optimizer given those modes. In addition, we use a particle filter-inspired method to reason about variability in diffusion sampling arising from model error, estimating likelihoods of trajectories using a learned discriminator. We show that our method outperforms ablations that do not reason about variability and can plan contact sequences that outperform those found in training data across multiple tasks. We evaluate on simulated tabletop card sliding and screwdriver turning tasks, as well as the screwdriver task in hardware to show that our combined learning and planning approach transfers to the real world.
Multi-finger Manipulation via Trajectory Optimization with Differentiable Rolling and Geometric Constraints
Aug 23, 2024Parameterizing finger rolling and finger-object contacts in a differentiable manner is important for formulating dexterous manipulation as a trajectory optimization problem. In contrast to previous methods which often assume simplified geometries of the robot and object or do not explicitly model finger rolling, we propose a method to further extend the capabilities of dexterous manipulation by accounting for non-trivial geometries of both the robot and the object. By integrating the object's Signed Distance Field (SDF) with a sampling method, our method estimates contact and rolling-related variables and includes those in a trajectory optimization framework. This formulation naturally allows for the emergence of finger-rolling behaviors, enabling the robot to locally adjust the contact points. Our method is tested in a peg alignment task and a screwdriver turning task, where it outperforms the baselines in terms of achieving desired object configurations and avoiding dropping the object. We also successfully apply our method to a real-world screwdriver turning task, demonstrating its robustness to the sim2real gap.
Online augmentation of learned grasp sequence policies for more adaptable and data-efficient in-hand manipulation
Apr 04, 2023



When using a tool, the grasps used for picking it up, reposing, and holding it in a suitable pose for the desired task could be distinct. Therefore, a key challenge for autonomous in-hand tool manipulation is finding a sequence of grasps that facilitates every step of the tool use process while continuously maintaining force closure and stability. Due to the complexity of modeling the contact dynamics, reinforcement learning (RL) techniques can provide a solution in this continuous space subject to highly parameterized physical models. However, these techniques impose a trade-off in adaptability and data efficiency. At test time the tool properties, desired trajectory, and desired application forces could differ substantially from training scenarios. Adapting to this necessitates more data or computationally expensive online policy updates. In this work, we apply the principles of discrete dynamic programming (DP) to augment RL performance with domain knowledge. Specifically, we first design a computationally simple approximation of our environment. We then demonstrate in physical simulation that performing tree searches (i.e., lookaheads) and policy rollouts with this approximation can improve an RL-derived grasp sequence policy with minimal additional online computation. Additionally, we show that pretraining a deep RL network with the DP-derived solution to the discretized problem can speed up policy training.
Hybrid Learning- and Model-Based Planning and Control of In-Hand Manipulation
Sep 20, 2022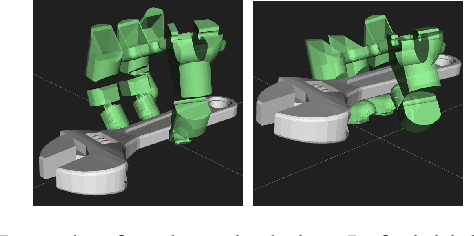
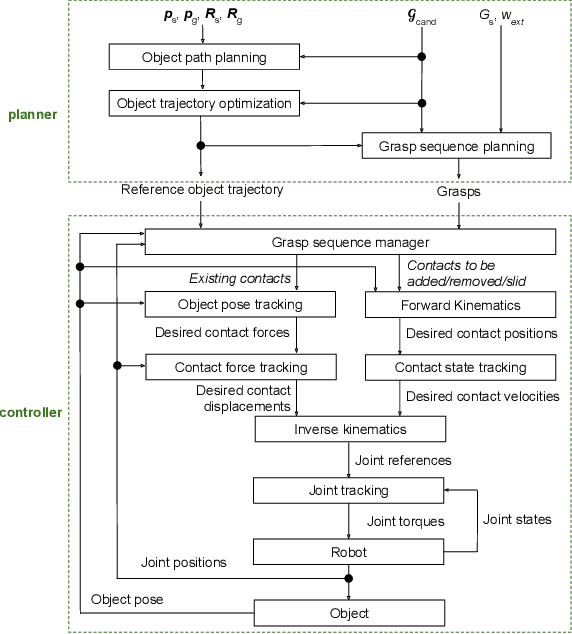
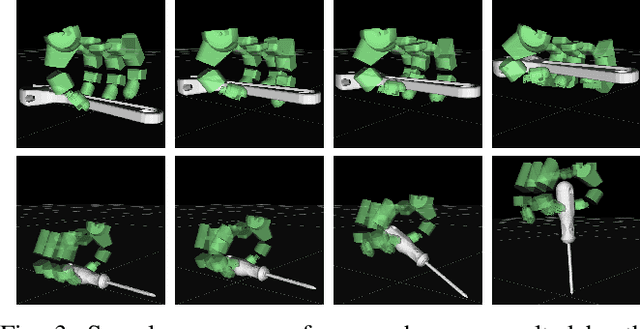
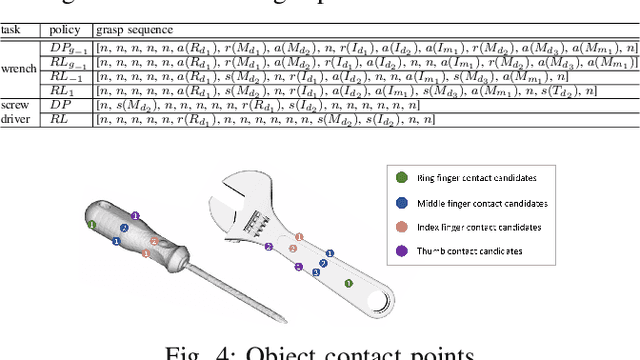
This paper presents a hierarchical framework for planning and control of in-hand manipulation of a rigid object involving grasp changes using fully-actuated multifingered robotic hands. While the framework can be applied to the general dexterous manipulation, we focus on a more complex definition of in-hand manipulation, where at the goal pose the hand has to reach a grasp suitable for using the object as a tool. The high level planner determines the object trajectory as well as the grasp changes, i.e. adding, removing, or sliding fingers, to be executed by the low-level controller. While the grasp sequence is planned online by a learning-based policy to adapt to variations, the trajectory planner and the low-level controller for object tracking and contact force control are exclusively model-based to robustly realize the plan. By infusing the knowledge about the physics of the problem and the low-level controller into the grasp planner, it learns to successfully generate grasps similar to those generated by model-based optimization approaches, obviating the high computation cost of online running of such methods to account for variations. By performing experiments in physics simulation for realistic tool use scenarios, we show the success of our method on different tool-use tasks and dexterous hand models. Additionally, we show that this hybrid method offers more robustness to trajectory and task variations compared to a model-based method.