 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Conformal Calibration of Dynamics Uncertainty from Semantic Images
May 13, 2026We introduce Observation-aware Conformal Uncertainty Local-Calibration (OCULAR), a conformal prediction-based algorithm that uses perception information to provide uncertainty quantification guarantees for unseen test-time environments. While previous conformal approaches lack the ability to discriminate between state-action space regions leading to higher or lower model mismatch, and require environment-specific data, our method uses data collected from visually similar environments to provably calibrate a given linear Gaussian dynamics model of arbitrary fidelity. The prediction regions generated from OCULAR are guaranteed to contain the future system states with, at least, a user-set likelihood, despite both aleatoric and epistemic uncertainty -- i.e., uncertainty arising from both stochastic disturbances and lack of data. Our guarantees are non-asymptotic and distribution-free, not requiring strong assumptions about the unknown real system dynamics. Our calibration procedure enables distinguishing between observation-velocity-action inputs leading to higher and lower next-state-uncertainty, which is helpful for probabilistically-safe planning. We numerically validate our algorithm on a double-integrator system subject to random perturbations and significant model mismatch, using both a simplified sensor and a more realistic simulated camera. Our approach appropriately quantifies uncertainty both when in-distribution and out-of-distribution, being comparatively volume-efficient to baselines requiring environment-specific data.
Simultaneous Extrinsic Contact and In-Hand Pose Estimation via Distributed Tactile Sensing
Dec 29, 2025Prehensile autonomous manipulation, such as peg insertion, tool use, or assembly, require precise in-hand understanding of the object pose and the extrinsic contacts made during interactions. Providing accurate estimation of pose and contacts is challenging. Tactile sensors can provide local geometry at the sensor and force information about the grasp, but the locality of sensing means resolving poses and contacts from tactile alone is often an ill-posed problem, as multiple configurations can be consistent with the observations. Adding visual feedback can help resolve ambiguities, but can suffer from noise and occlusions. In this work, we propose a method that pairs local observations from sensing with the physical constraints of contact. We propose a set of factors that ensure local consistency with tactile observations as well as enforcing physical plausibility, namely, that the estimated pose and contacts must respect the kinematic and force constraints of quasi-static rigid body interactions. We formalize our problem as a factor graph, allowing for efficient estimation. In our experiments, we demonstrate that our method outperforms existing geometric and contact-informed estimation pipelines, especially when only tactile information is available. Video results can be found at https://tacgraph.github.io/.
Lies We Can Trust: Quantifying Action Uncertainty with Inaccurate Stochastic Dynamics through Conformalized Nonholonomic Lie Groups
Dec 11, 2025We propose Conformal Lie-group Action Prediction Sets (CLAPS), a symmetry-aware conformal prediction-based algorithm that constructs, for a given action, a set guaranteed to contain the resulting system configuration at a user-defined probability. Our assurance holds under both aleatoric and epistemic uncertainty, non-asymptotically, and does not require strong assumptions about the true system dynamics, the uncertainty sources, or the quality of the approximate dynamics model. Typically, uncertainty quantification is tackled by making strong assumptions about the error distribution or magnitude, or by relying on uncalibrated uncertainty estimates - i.e., with no link to frequentist probabilities - which are insufficient for safe control. Recently, conformal prediction has emerged as a statistical framework capable of providing distribution-free probabilistic guarantees on test-time prediction accuracy. While current conformal methods treat robots as Euclidean points, many systems have non-Euclidean configurations, e.g., some mobile robots have SE(2). In this work, we rigorously analyze configuration errors using Lie groups, extending previous Euclidean Space theoretical guarantees to SE(2). Our experiments on a simulated JetBot, and on a real MBot, suggest that by considering the configuration space's structure, our symmetry-informed nonconformity score leads to more volume-efficient prediction regions which represent the underlying uncertainty better than existing approaches.
Unified Multimodal Diffusion Forcing for Forceful Manipulation
Nov 06, 2025Given a dataset of expert trajectories, standard imitation learning approaches typically learn a direct mapping from observations (e.g., RGB images) to actions. However, such methods often overlook the rich interplay between different modalities, i.e., sensory inputs, actions, and rewards, which is crucial for modeling robot behavior and understanding task outcomes. In this work, we propose Multimodal Diffusion Forcing, a unified framework for learning from multimodal robot trajectories that extends beyond action generation. Rather than modeling a fixed distribution, MDF applies random partial masking and trains a diffusion model to reconstruct the trajectory. This training objective encourages the model to learn temporal and cross-modal dependencies, such as predicting the effects of actions on force signals or inferring states from partial observations. We evaluate MDF on contact-rich, forceful manipulation tasks in simulated and real-world environments. Our results show that MDF not only delivers versatile functionalities, but also achieves strong performance, and robustness under noisy observations. More visualizations can be found on our website https://unified-df.github.io
Diffusing Trajectory Optimization Problems for Recovery During Multi-Finger Manipulation
Oct 08, 2025Multi-fingered hands are emerging as powerful platforms for performing fine manipulation tasks, including tool use. However, environmental perturbations or execution errors can impede task performance, motivating the use of recovery behaviors that enable normal task execution to resume. In this work, we take advantage of recent advances in diffusion models to construct a framework that autonomously identifies when recovery is necessary and optimizes contact-rich trajectories to recover. We use a diffusion model trained on the task to estimate when states are not conducive to task execution, framed as an out-of-distribution detection problem. We then use diffusion sampling to project these states in-distribution and use trajectory optimization to plan contact-rich recovery trajectories. We also propose a novel diffusion-based approach that distills this process to efficiently diffuse the full parameterization, including constraints, goal state, and initialization, of the recovery trajectory optimization problem, saving time during online execution. We compare our method to a reinforcement learning baseline and other methods that do not explicitly plan contact interactions, including on a hardware screwdriver-turning task where we show that recovering using our method improves task performance by 96% and that ours is the only method evaluated that can attempt recovery without causing catastrophic task failure. Videos can be found at https://dtourrecovery.github.io/.
AnoF-Diff: One-Step Diffusion-Based Anomaly Detection for Forceful Tool Use
Sep 18, 2025Multivariate time-series anomaly detection, which is critical for identifying unexpected events, has been explored in the field of machine learning for several decades. However, directly applying these methods to data from forceful tool use tasks is challenging because streaming sensor data in the real world tends to be inherently noisy, exhibits non-stationary behavior, and varies across different tasks and tools. To address these challenges, we propose a method, AnoF-Diff, based on the diffusion model to extract force-torque features from time-series data and use force-torque features to detect anomalies. We compare our method with other state-of-the-art methods in terms of F1-score and Area Under the Receiver Operating Characteristic curve (AUROC) on four forceful tool-use tasks, demonstrating that our method has better performance and is more robust to a noisy dataset. We also propose the method of parallel anomaly score evaluation based on one-step diffusion and demonstrate how our method can be used for online anomaly detection in several forceful tool use experiments.
Planning-Query-Guided Model Generation for Model-Based Deformable Object Manipulation
Aug 26, 2025Efficient planning in high-dimensional spaces, such as those involving deformable objects, requires computationally tractable yet sufficiently expressive dynamics models. This paper introduces a method that automatically generates task-specific, spatially adaptive dynamics models by learning which regions of the object require high-resolution modeling to achieve good task performance for a given planning query. Task performance depends on the complex interplay between the dynamics model, world dynamics, control, and task requirements. Our proposed diffusion-based model generator predicts per-region model resolutions based on start and goal pointclouds that define the planning query. To efficiently collect the data for learning this mapping, a two-stage process optimizes resolution using predictive dynamics as a prior before directly optimizing using closed-loop performance. On a tree-manipulation task, our method doubles planning speed with only a small decrease in task performance over using a full-resolution model. This approach informs a path towards using previous planning and control data to generate computationally efficient yet sufficiently expressive dynamics models for new tasks.
Estimating Deformable-Rigid Contact Interactions for a Deformable Tool via Learning and Model-Based Optimization
May 16, 2025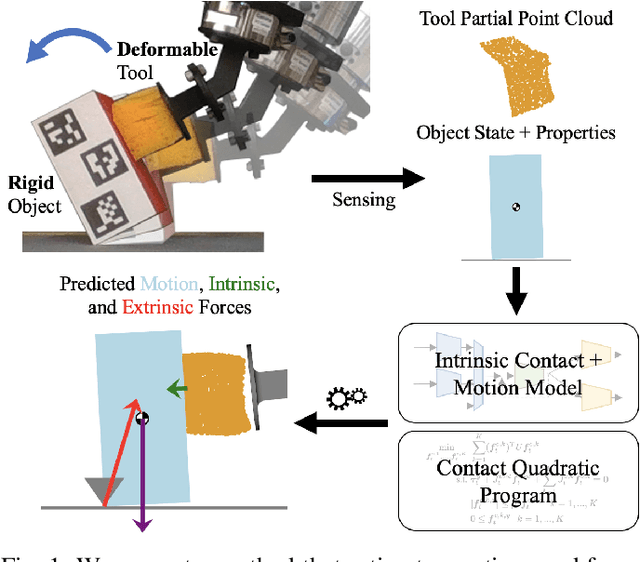
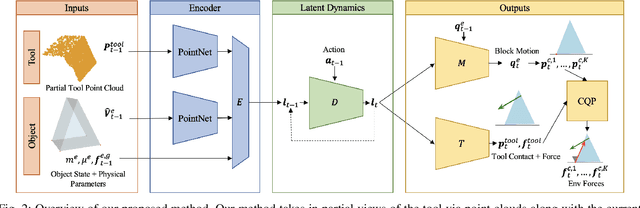
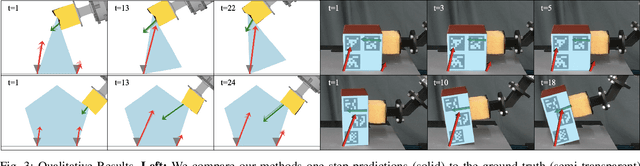
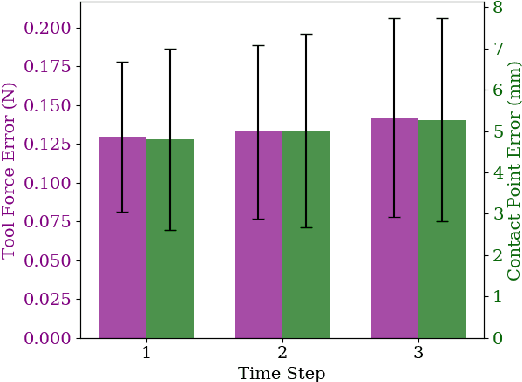
Dexterous manipulation requires careful reasoning over extrinsic contacts. The prevalence of deforming tools in human environments, the use of deformable sensors, and the increasing number of soft robots yields a need for approaches that enable dexterous manipulation through contact reasoning where not all contacts are well characterized by classical rigid body contact models. Here, we consider the case of a deforming tool dexterously manipulating a rigid object. We propose a hybrid learning and first-principles approach to the modeling of simultaneous motion and force transfer of tools and objects. The learned module is responsible for jointly estimating the rigid object's motion and the deformable tool's imparted contact forces. We then propose a Contact Quadratic Program to recover forces between the environment and object subject to quasi-static equilibrium and Coulomb friction. The results is a system capable of modeling both intrinsic and extrinsic motions, contacts, and forces during dexterous deformable manipulation. We train our method in simulation and show that our method outperforms baselines under varying block geometries and physical properties, during pushing and pivoting manipulations, and demonstrate transfer to real world interactions. Video results can be found at https://deform-rigid-contact.github.io/.
Language-Guided Object Search in Agricultural Environments
Mar 03, 2025Creating robots that can assist in farms and gardens can help reduce the mental and physical workload experienced by farm workers. We tackle the problem of object search in a farm environment, providing a method that allows a robot to semantically reason about the location of an unseen target object among a set of previously seen objects in the environment using a Large Language Model (LLM). We leverage object-to-object semantic relationships to plan a path through the environment that will allow us to accurately and efficiently locate our target object while also reducing the overall distance traveled, without needing high-level room or area-level semantic relationships. During our evaluations, we found that our method outperformed a current state-of-the-art baseline and our ablations. Our offline testing yielded an average path efficiency of 84%, reflecting how closely the predicted path aligns with the ideal path. Upon deploying our system on the Boston Dynamics Spot robot in a real-world farm environment, we found that our system had a success rate of 80%, with a success weighted by path length of 0.67, which demonstrates a reasonable trade-off between task success and path efficiency under real-world conditions. The project website can be viewed at https://adi-balaji.github.io/losae/
Implicit Contact Diffuser: Sequential Contact Reasoning with Latent Point Cloud Diffusion
Oct 21, 2024



Long-horizon contact-rich manipulation has long been a challenging problem, as it requires reasoning over both discrete contact modes and continuous object motion. We introduce Implicit Contact Diffuser (ICD), a diffusion-based model that generates a sequence of neural descriptors that specify a series of contact relationships between the object and the environment. This sequence is then used as guidance for an MPC method to accomplish a given task. The key advantage of this approach is that the latent descriptors provide more task-relevant guidance to MPC, helping to avoid local minima for contact-rich manipulation tasks. Our experiments demonstrate that ICD outperforms baselines on complex, long-horizon, contact-rich manipulation tasks, such as cable routing and notebook folding. Additionally, our experiments also indicate that \methodshort can generalize a target contact relationship to a different environment. More visualizations can be found on our website $\href{https://implicit-contact-diffuser.github.io/}{https://implicit-contact-diffuser.github.io}$