 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViSA: 3D-Aware Video Shading for Real-Time Upper-Body Avatar Creation
Dec 09, 2025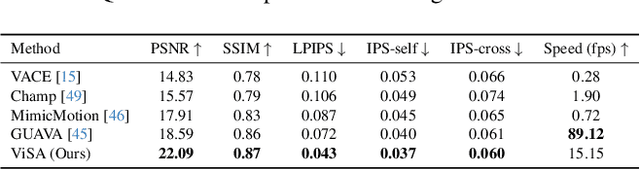
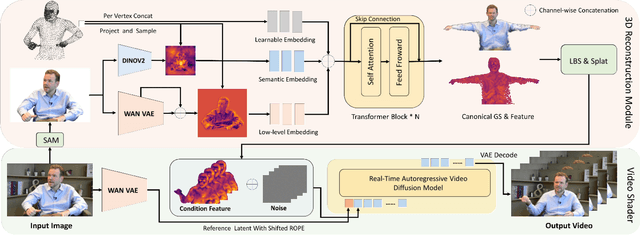
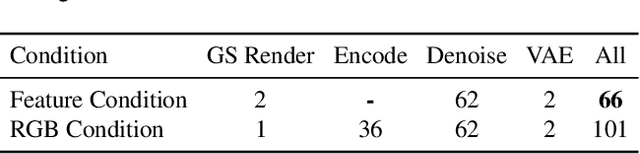
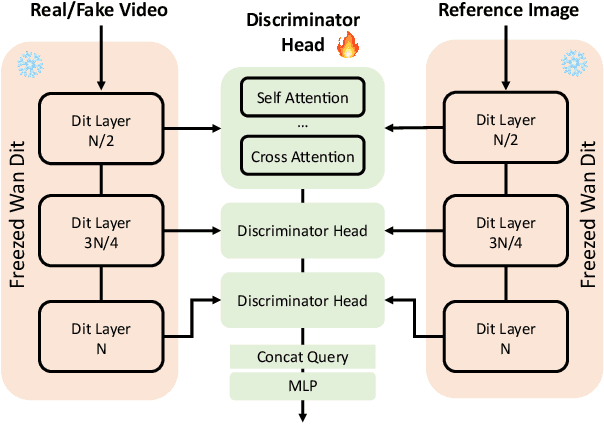
Generating high-fidelity upper-body 3D avatars from one-shot input image remains a significant challenge. Current 3D avatar generation methods, which rely on large reconstruction models, are fast and capable of producing stable body structures, but they often suffer from artifacts such as blurry textures and stiff, unnatural motion. In contrast, generative video models show promising performance by synthesizing photorealistic and dynamic results, but they frequently struggle with unstable behavior, including body structural errors and identity drift. To address these limitations, we propose a novel approach that combines the strengths of both paradigms. Our framework employs a 3D reconstruction model to provide robust structural and appearance priors, which in turn guides a real-time autoregressive video diffusion model for rendering. This process enables the model to synthesize high-frequency, photorealistic details and fluid dynamics in real time, effectively reducing texture blur and motion stiffness while preventing the structural inconsistencies common in video generation methods. By uniting the geometric stability of 3D reconstruction with the generative capabilities of video models, our method produces high-fidelity digital avatars with realistic appearance and dynamic, temporally coherent motion. Experiments demonstrate that our approach significantly reduces artifacts and achieves substantial improvements in visual quality over leading methods, providing a robust and efficient solution for real-time applications such as gaming and virtual reality. Project page: https://lhyfst.github.io/visa
Unsupervised Discovery of Long-Term Spatiotemporal Periodic Workflows in Human Activities
Nov 18, 2025Periodic human activities with implicit workflows are common in manufacturing, sports, and daily life. While short-term periodic activities -- characterized by simple structures and high-contrast patterns -- have been widely studied, long-term periodic workflows with low-contrast patterns remain largely underexplored. To bridge this gap, we introduce the first benchmark comprising 580 multimodal human activity sequences featuring long-term periodic workflows. The benchmark supports three evaluation tasks aligned with real-world applications: unsupervised periodic workflow detection, task completion tracking, and procedural anomaly detection. We also propose a lightweight, training-free baseline for modeling diverse periodic workflow patterns. Experiments show that: (i) our benchmark presents significant challenges to both unsupervised periodic detection methods and zero-shot approaches based on powerful large language models (LLMs); (ii) our baseline outperforms competing methods by a substantial margin in all evaluation tasks; and (iii) in real-world applications, our baseline demonstrates deployment advantages on par with traditional supervised workflow detection approaches, eliminating the need for annotation and retraining. Our project page is https://sites.google.com/view/periodicworkflow.
An approach of deep reinforcement learning for maximizing the net present value of stochastic projects
Nov 17, 2025



This paper investigates a project with stochastic activity durations and cash flows under discrete scenarios, where activities must satisfy precedence constraints generating cash inflows and outflows. The objective is to maximize expected net present value (NPV) by accelerating inflows and deferring outflows. We formulate the problem as a discrete-time Markov Decision Process (MDP) and propose a Double Deep Q-Network (DDQN) approach. Comparative experiments demonstrate that DDQN outperforms traditional rigid and dynamic strategies, particularly in large-scale or highly uncertain environments, exhibiting superior computational capability, policy reliability, and adaptability. Ablation studies further reveal that the dual-network architecture mitigates overestimation of action values, while the target network substantially improves training convergence and robustness. These results indicate that DDQN not only achieves higher expected NPV in complex project optimization but also provides a reliable framework for stable and effective policy implementation.
Catastrophic Forgetting in Kolmogorov-Arnold Networks
Nov 16, 2025Catastrophic forgetting is a longstanding challenge in continual learning, where models lose knowledge from earlier tasks when learning new ones. While various mitigation strategies have been proposed for Multi-Layer Perceptrons (MLPs), recent architectural advances like Kolmogorov-Arnold Networks (KANs) have been suggested to offer intrinsic resistance to forgetting by leveraging localized spline-based activations. However, the practical behavior of KANs under continual learning remains unclear, and their limitations are not well understood. To address this, we present a comprehensive study of catastrophic forgetting in KANs and develop a theoretical framework that links forgetting to activation support overlap and intrinsic data dimension. We validate these analyses through systematic experiments on synthetic and vision tasks, measuring forgetting dynamics under varying model configurations and data complexity. Further, we introduce KAN-LoRA, a novel adapter design for parameter-efficient continual fine-tuning of language models, and evaluate its effectiveness in knowledge editing tasks. Our findings reveal that while KANs exhibit promising retention in low-dimensional algorithmic settings, they remain vulnerable to forgetting in high-dimensional domains such as image classification and language modeling. These results advance the understanding of KANs' strengths and limitations, offering practical insights for continual learning system design.
MMA-Sim: Bit-Accurate Reference Model of Tensor Cores and Matrix Cores
Nov 14, 2025The rapidly growing computation demands of deep neural networks (DNNs) have driven hardware vendors to integrate matrix multiplication accelerators (MMAs), such as NVIDIA Tensor Cores and AMD Matrix Cores, into modern GPUs. However, due to distinct and undocumented arithmetic specifications for floating-point matrix multiplication, some MMAs can lead to numerical imprecision and inconsistency that can compromise the stability and reproducibility of DNN training and inference. This paper presents MMA-Sim, the first bit-accurate reference model that reveals the detailed arithmetic behaviors of the MMAs from ten GPU architectures (eight from NVIDIA and two from AMD). By dissecting the MMAs using a combination of targeted and randomized tests, our methodology derives nine arithmetic algorithms to simulate the floating-point matrix multiplication of the MMAs. Large-scale validation confirms bitwise equivalence between MMA-Sim and the real hardware. Using MMA-Sim, we investigate arithmetic behaviors that affect DNN training stability, and identify undocumented behaviors that could lead to significant errors.
Bridging the Initialization Gap: A Co-Optimization Framework for Mixed-Size Global Placement
Nov 13, 2025Global placement is a critical step with high computational complexity in VLSI physical design. Modern analytical placers formulate the placement problem as a nonlinear optimization, where initialization strongly affects both convergence behavior and final placement quality. However, existing initialization methods exhibit a trade-off: area-aware initializers account for cell areas but are computationally expensive and can dominate total runtime, while fast point-based initializers ignore cell area, leading to a modeling gap that impairs convergence and solution quality. We propose a lightweight co-optimization framework that bridges this initialization gap through two strategies. First, an area-hint refinement initializer incorporates heuristic cell area information into a signed graph signal by augmenting the netlist graph with virtual nodes and negative-weight edges, yielding an area-aware and spectrally smooth placement initialization. Second, a macro-schedule placement procedure progressively restores area constraints, enabling a smooth transition from the refined initializer to the full area-aware objective and producing high-quality placement results. We evaluate the framework on macro-heavy ISPD2005 academic benchmarks and two real-world industrial designs across two technology nodes (12 cases in total). Experimental results show that our method consistently improves half-perimeter wirelength (HPWL) over point-based initializers in 11 out of 12 cases, achieving up to 2.2% HPWL reduction, while running approximately 100 times faster than the state-of-the-art area-aware initializer.
Breaking the Stealth-Potency Trade-off in Clean-Image Backdoors with Generative Trigger Optimization
Nov 11, 2025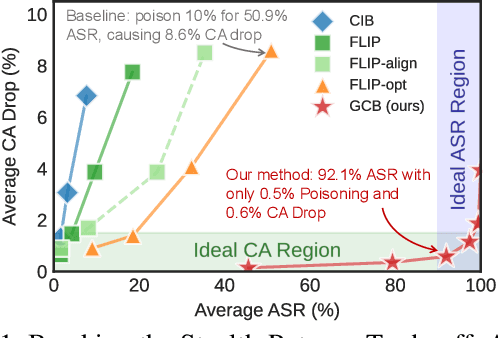
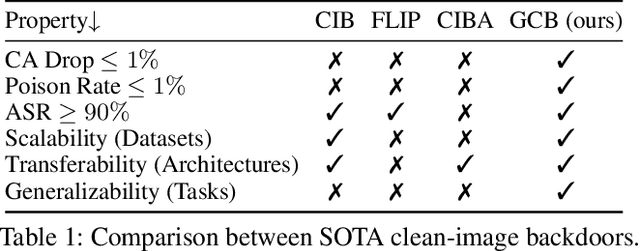
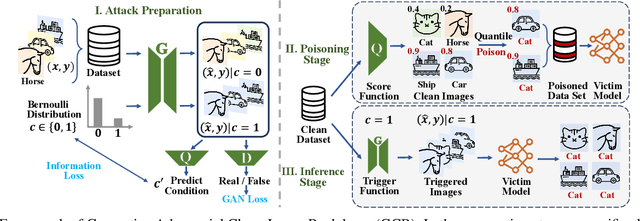
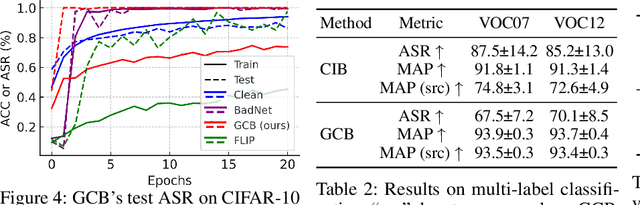
Clean-image backdoor attacks, which use only label manipulation in training datasets to compromise deep neural networks, pose a significant threat to security-critical applications. A critical flaw in existing methods is that the poison rate required for a successful attack induces a proportional, and thus noticeable, drop in Clean Accuracy (CA), undermining their stealthiness. This paper presents a new paradigm for clean-image attacks that minimizes this accuracy degradation by optimizing the trigger itself. We introduce Generative Clean-Image Backdoors (GCB), a framework that uses a conditional InfoGAN to identify naturally occurring image features that can serve as potent and stealthy triggers. By ensuring these triggers are easily separable from benign task-related features, GCB enables a victim model to learn the backdoor from an extremely small set of poisoned examples, resulting in a CA drop of less than 1%. Our experiments demonstrate GCB's remarkable versatility, successfully adapting to six datasets, five architectures, and four tasks, including the first demonstration of clean-image backdoors in regression and segmentation. GCB also exhibits resilience against most of the existing backdoor defenses.
Compression then Matching: An Efficient Pre-training Paradigm for Multimodal Embedding
Nov 11, 2025Vision-language models advance multimodal representation learning by acquiring transferable semantic embeddings, thereby substantially enhancing performance across a range of vision-language tasks, including cross-modal retrieval, clustering, and classification. An effective embedding is expected to comprehensively preserve the semantic content of the input while simultaneously emphasizing features that are discriminative for downstream tasks. Recent approaches demonstrate that VLMs can be adapted into competitive embedding models via large-scale contrastive learning, enabling the simultaneous optimization of two complementary objectives. We argue that the two aforementioned objectives can be decoupled: a comprehensive understanding of the input facilitates the embedding model in achieving superior performance in downstream tasks via contrastive learning. In this paper, we propose CoMa, a compressed pre-training phase, which serves as a warm-up stage for contrastive learning. Experiments demonstrate that with only a small amount of pre-training data, we can transform a VLM into a competitive embedding model. CoMa achieves new state-of-the-art results among VLMs of comparable size on the MMEB, realizing optimization in both efficiency and effectiveness.
Rep2Text: Decoding Full Text from a Single LLM Token Representation
Nov 09, 2025Large language models (LLMs) have achieved remarkable progress across diverse tasks, yet their internal mechanisms remain largely opaque. In this work, we address a fundamental question: to what extent can the original input text be recovered from a single last-token representation within an LLM? We propose Rep2Text, a novel framework for decoding full text from last-token representations. Rep2Text employs a trainable adapter that projects a target model's internal representations into the embedding space of a decoding language model, which then autoregressively reconstructs the input text. Experiments on various model combinations (Llama-3.1-8B, Gemma-7B, Mistral-7B-v0.1, Llama-3.2-3B) demonstrate that, on average, over half of the information in 16-token sequences can be recovered from this compressed representation while maintaining strong semantic integrity and coherence. Furthermore, our analysis reveals an information bottleneck effect: longer sequences exhibit decreased token-level recovery while preserving strong semantic integrity. Besides, our framework also demonstrates robust generalization to out-of-distribution medical data.
LiveStar: Live Streaming Assistant for Real-World Online Video Understanding
Nov 07, 2025Despite significant progress in Video Large Language Models (Video-LLMs) for offline video understanding, existing online Video-LLMs typically struggle to simultaneously process continuous frame-by-frame inputs and determine optimal response timing, often compromising real-time responsiveness and narrative coherence. To address these limitations, we introduce LiveStar, a pioneering live streaming assistant that achieves always-on proactive responses through adaptive streaming decoding. Specifically, LiveStar incorporates: (1) a training strategy enabling incremental video-language alignment for variable-length video streams, preserving temporal consistency across dynamically evolving frame sequences; (2) a response-silence decoding framework that determines optimal proactive response timing via a single forward pass verification; (3) memory-aware acceleration via peak-end memory compression for online inference on 10+ minute videos, combined with streaming key-value cache to achieve 1.53x faster inference. We also construct an OmniStar dataset, a comprehensive dataset for training and benchmarking that encompasses 15 diverse real-world scenarios and 5 evaluation tasks for online video understanding. Extensive experiments across three benchmarks demonstrate LiveStar's state-of-the-art performance, achieving an average 19.5% improvement in semantic correctness with 18.1% reduced timing difference compared to existing online Video-LLMs, while improving FPS by 12.0% across all five OmniStar tasks. Our model and dataset can be accessed at https://github.com/yzy-bupt/LiveStar.