 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMA-Sim: Bit-Accurate Reference Model of Tensor Cores and Matrix Cores
Nov 14, 2025The rapidly growing computation demands of deep neural networks (DNNs) have driven hardware vendors to integrate matrix multiplication accelerators (MMAs), such as NVIDIA Tensor Cores and AMD Matrix Cores, into modern GPUs. However, due to distinct and undocumented arithmetic specifications for floating-point matrix multiplication, some MMAs can lead to numerical imprecision and inconsistency that can compromise the stability and reproducibility of DNN training and inference. This paper presents MMA-Sim, the first bit-accurate reference model that reveals the detailed arithmetic behaviors of the MMAs from ten GPU architectures (eight from NVIDIA and two from AMD). By dissecting the MMAs using a combination of targeted and randomized tests, our methodology derives nine arithmetic algorithms to simulate the floating-point matrix multiplication of the MMAs. Large-scale validation confirms bitwise equivalence between MMA-Sim and the real hardware. Using MMA-Sim, we investigate arithmetic behaviors that affect DNN training stability, and identify undocumented behaviors that could lead to significant errors.
BAYHENN: Combining Bayesian Deep Learning and Homomorphic Encryption for Secure DNN Inference
Jun 03, 2019

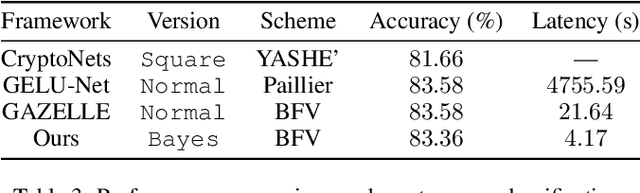
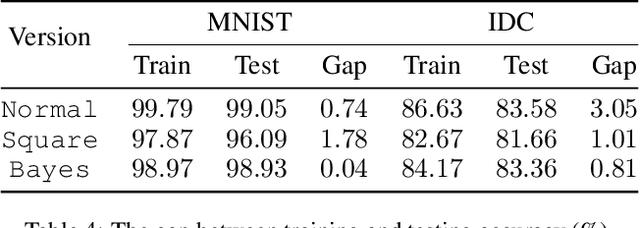
Recently, deep learning as a service (DLaaS) has emerged as a promising way to facilitate the employment of deep neural networks (DNNs) for various purposes. However, using DLaaS also causes potential privacy leakage from both clients and cloud servers. This privacy issue has fueled the research interests on the privacy-preserving inference of DNN models in the cloud service. In this paper, we present a practical solution named BAYHENN for secure DNN inference. It can protect both the client's privacy and server's privacy at the same time. The key strategy of our solution is to combine homomorphic encryption and Bayesian neural networks. Specifically, we use homomorphic encryption to protect a client's raw data and use Bayesian neural networks to protect the DNN weights in a cloud server. To verify the effectiveness of our solution, we conduct experiments on MNIST and a real-life clinical dataset. Our solution achieves consistent latency decreases on both tasks. In particular, our method can outperform the best existing method (GAZELLE) by about 5x, in terms of end-to-end latency.