 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Agent Automation Becomes Profitable: Quantifying and Insuring Autonomous AI Risk through Trace-Economic Underwriting
Jun 15, 2026AI agents can now take irreversible actions in operational systems, but agent-caused losses are still not clearly assigned, priced, or transferred. Providers often disclaim consequential damages, users are left with uncompensated losses, and default human review limits the efficiency gains of automation. We ask when autonomous AI deployment can become economically acceptable despite failure risk. Our answer is to quantify risk at the customer-task-trace episode level and transfer it through insurance. Automation is acceptable when its expected benefit exceeds the premium, control cost, and remaining risk. This requires a defined role with bounded permissions and comparable traces. We introduce trace-economic underwriting, which maps tool-use traces to customer exposure and claimable loss, then uses this representation for pricing, control, and risk transfer. It uses deterministic economic labels rather than an LLM judge. In our trace-to-loss testbed, trace-economic pricing reduces pricing MAE from $17.7K to $569 and removes regressive cross-subsidy. A 300-trace expert audit accepts 295 labels unchanged. On 1,000 real SWE-smith traces, trace-conditioned controls reduce CVaR95 by 72%. Theorem~1 gives a finite-sample scope condition. We release code, labels, and audit sheets.
Learning the Context of Errors: Black-Box Online Adaptation of Time Series Foundation Models
Jun 12, 2026The rapid evolution of Time Series Foundation Models (TSFMs) has advanced zero-shot forecasting across diverse domains. Inspired by the current form of Large Language Models, future TSFMs may be offered as commercialized, closed-source API services. However, many existing online adaptation methods still rely on white-box access for parameter fine-tuning or gradient backpropagation. This paradigm mismatch raises a question: In black-box online adaptation for TSFMs, what should we learn? We answer this with an insight: the predictive errors of the base model are conditioned on both the input and output of the base model (i.e., the context of errors). To validate this insight, we propose ORCA (Online Residual Contextual Adaptation). We conduct extensive experiments across 5 state-of-the-art TSFMs and 8 datasets to demonstrate the effectiveness of our approach. Furthermore, through ablation studies, we quantitatively analyze the impact of different adapter learning hypotheses on the final adaptation performance in black-box online adaptation. Code available at https://github.com/Fifthky/ORCA.
Navigating the Safety-Fidelity Trade-off: Massive-Variate Time Series Forecasting for Power Systems via Probabilistic Scenarios
Jun 11, 2026Probabilistic forecasting models are increasingly deployed on multivariate systems with distinct channel physics and operational constraints, but existing benchmarks evaluate neither property at scale. Public canonical multivariate benchmarks cap out at 2,000 channels, while power-system benchmarks either lack temporal structure or probabilistic evaluation. We introduce PowerPhase, a probabilistic forecasting benchmark built on six transmission grids ranging from 2,000 to 36,964 jointly forecasted channels, more than an order of magnitude beyond popular canonical multivariate benchmarks. Each target trajectory is the output of an AC power-flow solve, and PowerPhase ships with constraint-aware metrics, including Safety_mBrier, NECV, and CVaR-alpha, that complement CRPS and Distortion. Across eight baselines and three seeds, distributional accuracy and constraint satisfaction rank models differently, a trade-off we term safety-fidelity. We further propose PowerForge, a scenario-based quantile forecaster with type-specific decoding heads and a causal bridge between variable groups, which achieves the best average rank on every grid.
Falcon-X: A Time Series Foundation Model for Heterogeneous Multivariate Modeling
May 26, 2026Time series foundation models (TSFMs) are transforming the forecasting paradigm through large-scale cross-domain pretraining. However, most existing TSFMs remain univariate, and recent efforts to enable cross-variate modeling still operate directly within the raw variate space. This design introduces fundamental limitations in semantic alignment and relational expressivity. Specifically, raw-space group mixing lacks a dedicated mechanism to align heterogeneous physical quantities, while standard non-negative attention fails to capture the complex synergistic and antagonistic interactions ubiquitous in real-world systems. To address these challenges, we propose Falcon-X, decouples variates from the raw space and maps them into a unified latent prototype space. Falcon-X employs a Unified Prototype Diff-Attention mechanism that explicitly evaluates both positive and negative semantic affinities to explicitly align heterogeneous variates. Cross-variate interactions are then efficiently performed within this shared space via Latent Entity Attention, naturally facilitating zero-shot structural transfer. Finally, a Variate Reassembly Router robustly reconstructs variate-specific trajectories via a request-and-dispatch mechanism. Extensive evaluations on the GIFT-Eval and fev-bench benchmarks demonstrate that Falcon-X achieves state-of-the-art forecasting performance, offering a principled and scalable paradigm for complex multivariate environments. Falcon-X is publicly released to support future research.
Position: Universal Time Series Foundation Models Rest on a Category Error
Feb 05, 2026This position paper argues that the pursuit of "Universal Foundation Models for Time Series" rests on a fundamental category error, mistaking a structural Container for a semantic Modality. We contend that because time series hold incompatible generative processes (e.g., finance vs. fluid dynamics), monolithic models degenerate into expensive "Generic Filters" that fail to generalize under distributional drift. To address this, we introduce the "Autoregressive Blindness Bound," a theoretical limit proving that history-only models cannot predict intervention-driven regime shifts. We advocate replacing universality with a Causal Control Agent paradigm, where an agent leverages external context to orchestrate a hierarchy of specialized solvers, from frozen domain experts to lightweight Just-in-Time adaptors. We conclude by calling for a shift in benchmarks from "Zero-Shot Accuracy" to "Drift Adaptation Speed" to prioritize robust, control-theoretic systems.
From Internal Diagnosis to External Auditing: A VLM-Driven Paradigm for Online Test-Time Backdoor Defense
Jan 27, 2026Deep Neural Networks remain inherently vulnerable to backdoor attacks. Traditional test-time defenses largely operate under the paradigm of internal diagnosis methods like model repairing or input robustness, yet these approaches are often fragile under advanced attacks as they remain entangled with the victim model's corrupted parameters. We propose a paradigm shift from Internal Diagnosis to External Semantic Auditing, arguing that effective defense requires decoupling safety from the victim model via an independent, semantically grounded auditor. To this end, we present a framework harnessing Universal Vision-Language Models (VLMs) as evolving semantic gatekeepers. We introduce PRISM (Prototype Refinement & Inspection via Statistical Monitoring), which overcomes the domain gap of general VLMs through two key mechanisms: a Hybrid VLM Teacher that dynamically refines visual prototypes online, and an Adaptive Router powered by statistical margin monitoring to calibrate gating thresholds in real-time. Extensive evaluation across 17 datasets and 11 attack types demonstrates that PRISM achieves state-of-the-art performance, suppressing Attack Success Rate to <1% on CIFAR-10 while improving clean accuracy, establishing a new standard for model-agnostic, externalized security.
Breaking the Stealth-Potency Trade-off in Clean-Image Backdoors with Generative Trigger Optimization
Nov 11, 2025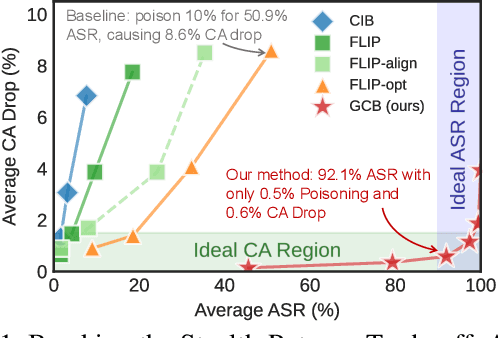
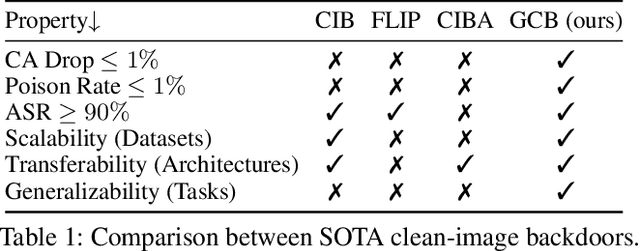
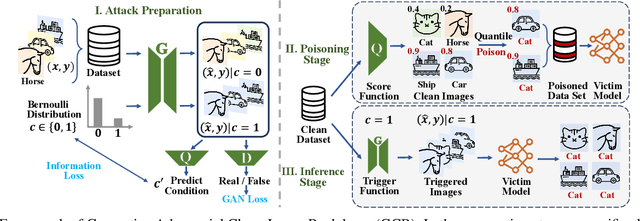
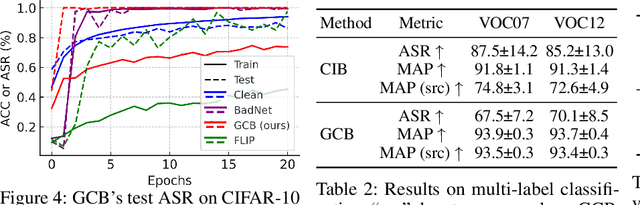
Clean-image backdoor attacks, which use only label manipulation in training datasets to compromise deep neural networks, pose a significant threat to security-critical applications. A critical flaw in existing methods is that the poison rate required for a successful attack induces a proportional, and thus noticeable, drop in Clean Accuracy (CA), undermining their stealthiness. This paper presents a new paradigm for clean-image attacks that minimizes this accuracy degradation by optimizing the trigger itself. We introduce Generative Clean-Image Backdoors (GCB), a framework that uses a conditional InfoGAN to identify naturally occurring image features that can serve as potent and stealthy triggers. By ensuring these triggers are easily separable from benign task-related features, GCB enables a victim model to learn the backdoor from an extremely small set of poisoned examples, resulting in a CA drop of less than 1%. Our experiments demonstrate GCB's remarkable versatility, successfully adapting to six datasets, five architectures, and four tasks, including the first demonstration of clean-image backdoors in regression and segmentation. GCB also exhibits resilience against most of the existing backdoor defenses.
One Surrogate to Fool Them All: Universal, Transferable, and Targeted Adversarial Attacks with CLIP
May 26, 2025Deep Neural Networks (DNNs) have achieved widespread success yet remain prone to adversarial attacks. Typically, such attacks either involve frequent queries to the target model or rely on surrogate models closely mirroring the target model -- often trained with subsets of the target model's training data -- to achieve high attack success rates through transferability. However, in realistic scenarios where training data is inaccessible and excessive queries can raise alarms, crafting adversarial examples becomes more challenging. In this paper, we present UnivIntruder, a novel attack framework that relies solely on a single, publicly available CLIP model and publicly available datasets. By using textual concepts, UnivIntruder generates universal, transferable, and targeted adversarial perturbations that mislead DNNs into misclassifying inputs into adversary-specified classes defined by textual concepts. Our extensive experiments show that our approach achieves an Attack Success Rate (ASR) of up to 85% on ImageNet and over 99% on CIFAR-10, significantly outperforming existing transfer-based methods. Additionally, we reveal real-world vulnerabilities, showing that even without querying target models, UnivIntruder compromises image search engines like Google and Baidu with ASR rates up to 84%, and vision language models like GPT-4 and Claude-3.5 with ASR rates up to 80%. These findings underscore the practicality of our attack in scenarios where traditional avenues are blocked, highlighting the need to reevaluate security paradigms in AI applications.