 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndoorR2X: Indoor Robot-to-Everything Coordination with LLM-Driven Planning
Mar 20, 2026Although robot-to-robot (R2R) communication improves indoor scene understanding beyond what a single robot can achieve, R2R alone cannot overcome partial observability without substantial exploration overhead or scaling team size. In contrast, many indoor environments already include low-cost Internet of Things (IoT) sensors (e.g., cameras) that provide persistent, building-wide context beyond onboard perception. We therefore introduce IndoorR2X, the first benchmark and simulation framework for Large Language Model (LLM)-driven multi-robot task planning with Robot-to-Everything (R2X) perception and communication in indoor environments. IndoorR2X integrates observations from mobile robots and static IoT devices to construct a global semantic state that supports scalable scene understanding, reduces redundant exploration, and enables high-level coordination through LLM-based planning. IndoorR2X provides configurable simulation environments, sensor layouts, robot teams, and task suites to systematically evaluate high-level semantic coordination strategies. Extensive experiments across diverse settings demonstrate that IoT-augmented world modeling improves multi-robot efficiency and reliability, and we highlight key insights and failure modes for advancing LLM-based collaboration between robot teams and indoor IoT sensors.
Affordance RAG: Hierarchical Multimodal Retrieval with Affordance-Aware Embodied Memory for Mobile Manipulation
Dec 22, 2025In this study, we address the problem of open-vocabulary mobile manipulation, where a robot is required to carry a wide range of objects to receptacles based on free-form natural language instructions. This task is challenging, as it involves understanding visual semantics and the affordance of manipulation actions. To tackle these challenges, we propose Affordance RAG, a zero-shot hierarchical multimodal retrieval framework that constructs Affordance-Aware Embodied Memory from pre-explored images. The model retrieves candidate targets based on regional and visual semantics and reranks them with affordance scores, allowing the robot to identify manipulation options that are likely to be executable in real-world environments. Our method outperformed existing approaches in retrieval performance for mobile manipulation instruction in large-scale indoor environments. Furthermore, in real-world experiments where the robot performed mobile manipulation in indoor environments based on free-form instructions, the proposed method achieved a task success rate of 85%, outperforming existing methods in both retrieval performance and overall task success.
Unsupervised Discovery of Long-Term Spatiotemporal Periodic Workflows in Human Activities
Nov 18, 2025Periodic human activities with implicit workflows are common in manufacturing, sports, and daily life. While short-term periodic activities -- characterized by simple structures and high-contrast patterns -- have been widely studied, long-term periodic workflows with low-contrast patterns remain largely underexplored. To bridge this gap, we introduce the first benchmark comprising 580 multimodal human activity sequences featuring long-term periodic workflows. The benchmark supports three evaluation tasks aligned with real-world applications: unsupervised periodic workflow detection, task completion tracking, and procedural anomaly detection. We also propose a lightweight, training-free baseline for modeling diverse periodic workflow patterns. Experiments show that: (i) our benchmark presents significant challenges to both unsupervised periodic detection methods and zero-shot approaches based on powerful large language models (LLMs); (ii) our baseline outperforms competing methods by a substantial margin in all evaluation tasks; and (iii) in real-world applications, our baseline demonstrates deployment advantages on par with traditional supervised workflow detection approaches, eliminating the need for annotation and retraining. Our project page is https://sites.google.com/view/periodicworkflow.
Embodied-RAG: General non-parametric Embodied Memory for Retrieval and Generation
Sep 26, 2024



There is no limit to how much a robot might explore and learn, but all of that knowledge needs to be searchable and actionable. Within language research, retrieval augmented generation (RAG) has become the workhouse of large-scale non-parametric knowledge, however existing techniques do not directly transfer to the embodied domain, which is multimodal, data is highly correlated, and perception requires abstraction. To address these challenges, we introduce Embodied-RAG, a framework that enhances the foundational model of an embodied agent with a non-parametric memory system capable of autonomously constructing hierarchical knowledge for both navigation and language generation. Embodied-RAG handles a full range of spatial and semantic resolutions across diverse environments and query types, whether for a specific object or a holistic description of ambiance. At its core, Embodied-RAG's memory is structured as a semantic forest, storing language descriptions at varying levels of detail. This hierarchical organization allows the system to efficiently generate context-sensitive outputs across different robotic platforms. We demonstrate that Embodied-RAG effectively bridges RAG to the robotics domain, successfully handling over 200 explanation and navigation queries across 19 environments, highlighting its promise for general-purpose non-parametric system for embodied agents.
Toward General-Purpose Robots via Foundation Models: A Survey and Meta-Analysis
Dec 15, 2023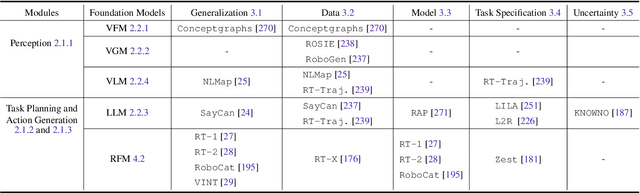
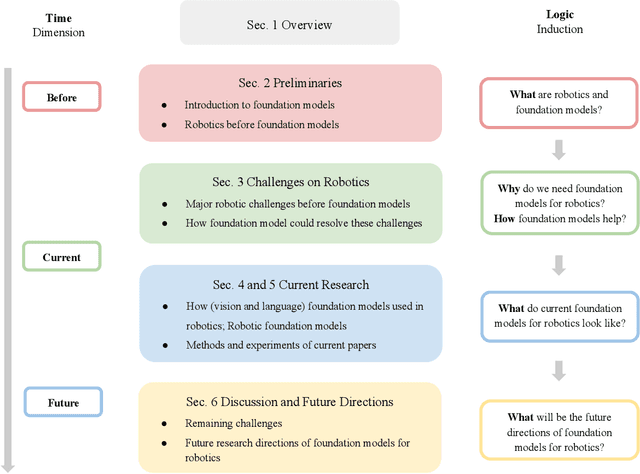
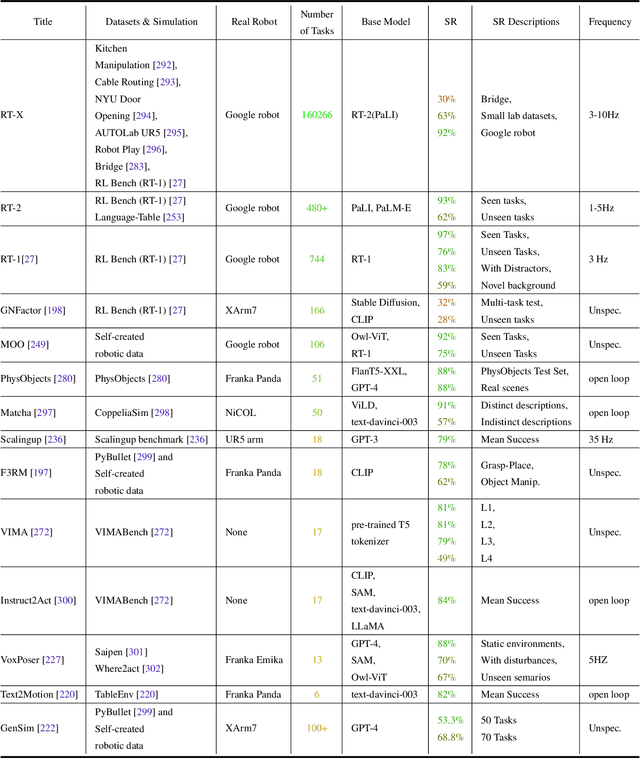
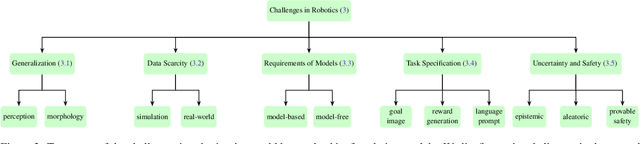
Building general-purpose robots that can operate seamlessly, in any environment, with any object, and utilizing various skills to complete diverse tasks has been a long-standing goal in Artificial Intelligence. Unfortunately, however, most existing robotic systems have been constrained - having been designed for specific tasks, trained on specific datasets, and deployed within specific environments. These systems usually require extensively-labeled data, rely on task-specific models, have numerous generalization issues when deployed in real-world scenarios, and struggle to remain robust to distribution shifts. Motivated by the impressive open-set performance and content generation capabilities of web-scale, large-capacity pre-trained models (i.e., foundation models) in research fields such as Natural Language Processing (NLP) and Computer Vision (CV), we devote this survey to exploring (i) how these existing foundation models from NLP and CV can be applied to the field of robotics, and also exploring (ii) what a robotics-specific foundation model would look like. We begin by providing an overview of what constitutes a conventional robotic system and the fundamental barriers to making it universally applicable. Next, we establish a taxonomy to discuss current work exploring ways to leverage existing foundation models for robotics and develop ones catered to robotics. Finally, we discuss key challenges and promising future directions in using foundation models for enabling general-purpose robotic systems. We encourage readers to view our living GitHub repository of resources, including papers reviewed in this survey as well as related projects and repositories for developing foundation models for robotics.
Reasoning about the Unseen for Efficient Outdoor Object Navigation
Sep 18, 2023Robots should exist anywhere humans do: indoors, outdoors, and even unmapped environments. In contrast, the focus of recent advancements in Object Goal Navigation(OGN) has targeted navigating in indoor environments by leveraging spatial and semantic cues that do not generalize outdoors. While these contributions provide valuable insights into indoor scenarios, the broader spectrum of real-world robotic applications often extends to outdoor settings. As we transition to the vast and complex terrains of outdoor environments, new challenges emerge. Unlike the structured layouts found indoors, outdoor environments lack clear spatial delineations and are riddled with inherent semantic ambiguities. Despite this, humans navigate with ease because we can reason about the unseen. We introduce a new task OUTDOOR, a new mechanism for Large Language Models (LLMs) to accurately hallucinate possible futures, and a new computationally aware success metric for pushing research forward in this more complex domain. Additionally, we show impressive results on both a simulated drone and physical quadruped in outdoor environments. Our agent has no premapping and our formalism outperforms naive LLM-based approaches