 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting 3D Object Detection From an Egocentric Perspective
Dec 14, 2021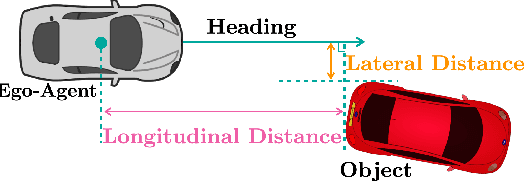
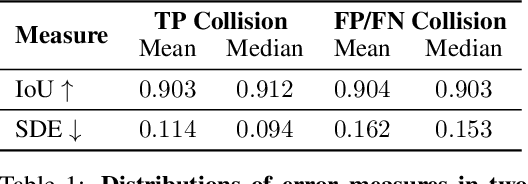
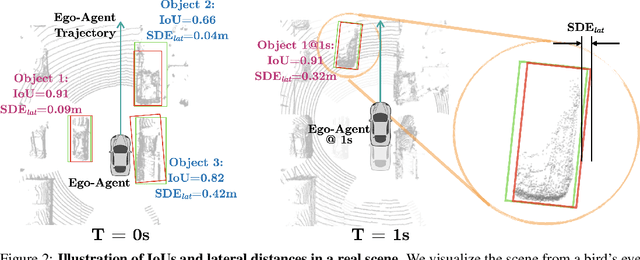
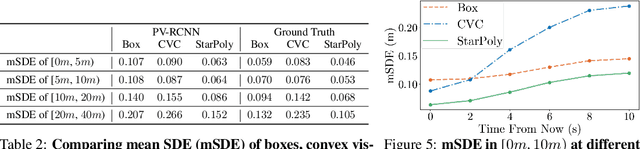
3D object detection is a key module for safety-critical robotics applications such as autonomous driving. For these applications, we care most about how the detections affect the ego-agent's behavior and safety (the egocentric perspective). Intuitively, we seek more accurate descriptions of object geometry when it's more likely to interfere with the ego-agent's motion trajectory. However, current detection metrics, based on box Intersection-over-Union (IoU), are object-centric and aren't designed to capture the spatio-temporal relationship between objects and the ego-agent. To address this issue, we propose a new egocentric measure to evaluate 3D object detection, namely Support Distance Error (SDE). Our analysis based on SDE reveals that the egocentric detection quality is bounded by the coarse geometry of the bounding boxes. Given the insight that SDE would benefit from more accurate geometry descriptions, we propose to represent objects as amodal contours, specifically amodal star-shaped polygons, and devise a simple model, StarPoly, to predict such contours. Our experiments on the large-scale Waymo Open Dataset show that SDE better reflects the impact of detection quality on the ego-agent's safety compared to IoU; and the estimated contours from StarPoly consistently improve the egocentric detection quality over recent 3D object detectors.
SPG: Unsupervised Domain Adaptation for 3D Object Detection via Semantic Point Generation
Aug 15, 2021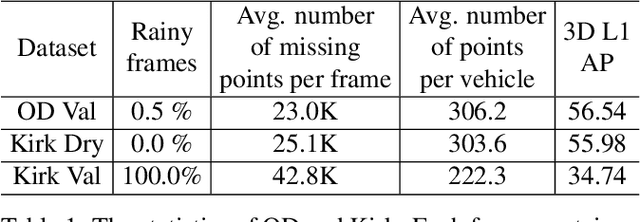

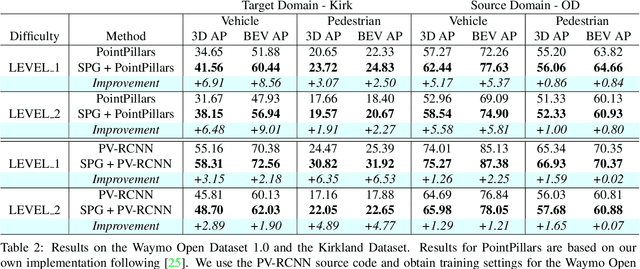
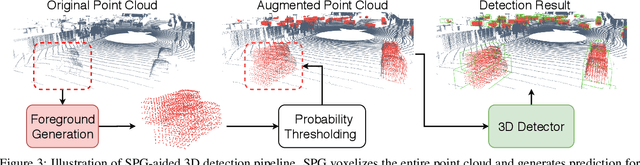
In autonomous driving, a LiDAR-based object detector should perform reliably at different geographic locations and under various weather conditions. While recent 3D detection research focuses on improving performance within a single domain, our study reveals that the performance of modern detectors can drop drastically cross-domain. In this paper, we investigate unsupervised domain adaptation (UDA) for LiDAR-based 3D object detection. On the Waymo Domain Adaptation dataset, we identify the deteriorating point cloud quality as the root cause of the performance drop. To address this issue, we present Semantic Point Generation (SPG), a general approach to enhance the reliability of LiDAR detectors against domain shifts. Specifically, SPG generates semantic points at the predicted foreground regions and faithfully recovers missing parts of the foreground objects, which are caused by phenomena such as occlusions, low reflectance or weather interference. By merging the semantic points with the original points, we obtain an augmented point cloud, which can be directly consumed by modern LiDAR-based detectors. To validate the wide applicability of SPG, we experiment with two representative detectors, PointPillars and PV-RCNN. On the UDA task, SPG significantly improves both detectors across all object categories of interest and at all difficulty levels. SPG can also benefit object detection in the original domain. On the Waymo Open Dataset and KITTI, SPG improves 3D detection results of these two methods across all categories. Combined with PV-RCNN, SPG achieves state-of-the-art 3D detection results on KITTI.
HDMapGen: A Hierarchical Graph Generative Model of High Definition Maps
Jun 28, 2021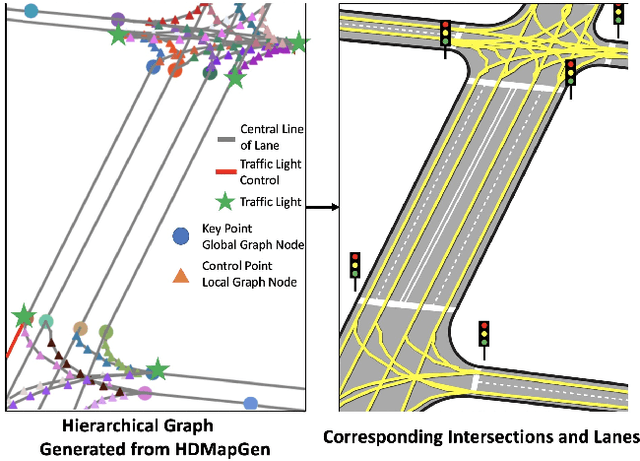
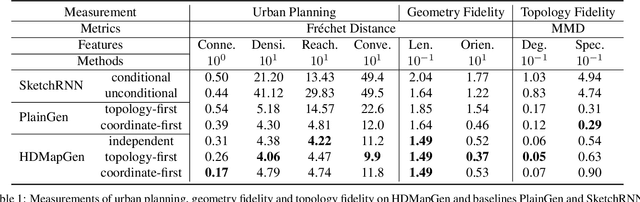
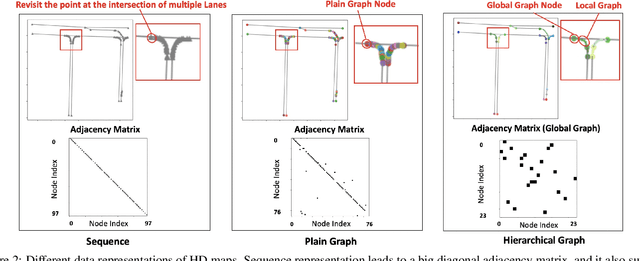

High Definition (HD) maps are maps with precise definitions of road lanes with rich semantics of the traffic rules. They are critical for several key stages in an autonomous driving system, including motion forecasting and planning. However, there are only a small amount of real-world road topologies and geometries, which significantly limits our ability to test out the self-driving stack to generalize onto new unseen scenarios. To address this issue, we introduce a new challenging task to generate HD maps. In this work, we explore several autoregressive models using different data representations, including sequence, plain graph, and hierarchical graph. We propose HDMapGen, a hierarchical graph generation model capable of producing high-quality and diverse HD maps through a coarse-to-fine approach. Experiments on the Argoverse dataset and an in-house dataset show that HDMapGen significantly outperforms baseline methods. Additionally, we demonstrate that HDMapGen achieves high scalability and efficiency.
To the Point: Efficient 3D Object Detection in the Range Image with Graph Convolution Kernels
Jun 25, 2021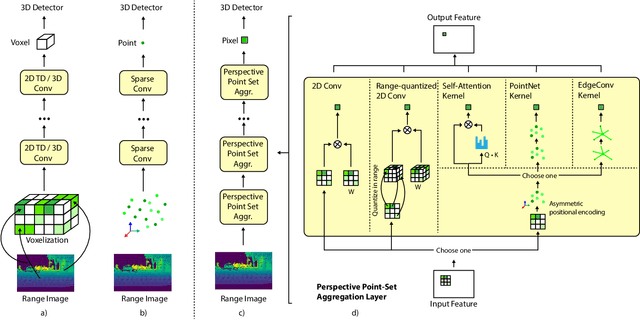
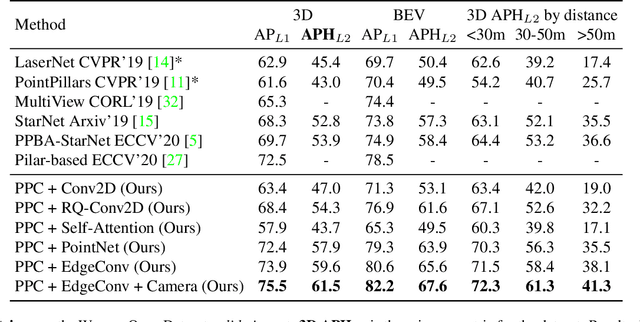
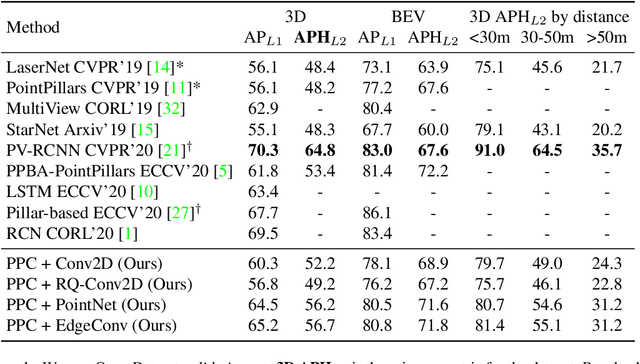
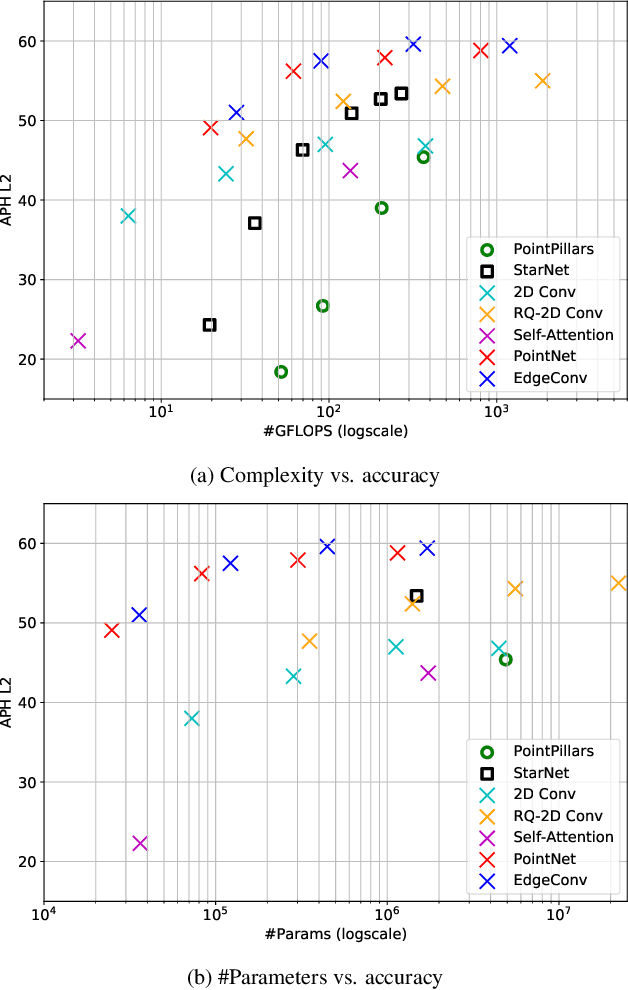
3D object detection is vital for many robotics applications. For tasks where a 2D perspective range image exists, we propose to learn a 3D representation directly from this range image view. To this end, we designed a 2D convolutional network architecture that carries the 3D spherical coordinates of each pixel throughout the network. Its layers can consume any arbitrary convolution kernel in place of the default inner product kernel and exploit the underlying local geometry around each pixel. We outline four such kernels: a dense kernel according to the bag-of-words paradigm, and three graph kernels inspired by recent graph neural network advances: the Transformer, the PointNet, and the Edge Convolution. We also explore cross-modality fusion with the camera image, facilitated by operating in the perspective range image view. Our method performs competitively on the Waymo Open Dataset and improves the state-of-the-art AP for pedestrian detection from 69.7% to 75.5%. It is also efficient in that our smallest model, which still outperforms the popular PointPillars in quality, requires 180 times fewer FLOPS and model parameters
RSN: Range Sparse Net for Efficient, Accurate LiDAR 3D Object Detection
Jun 25, 2021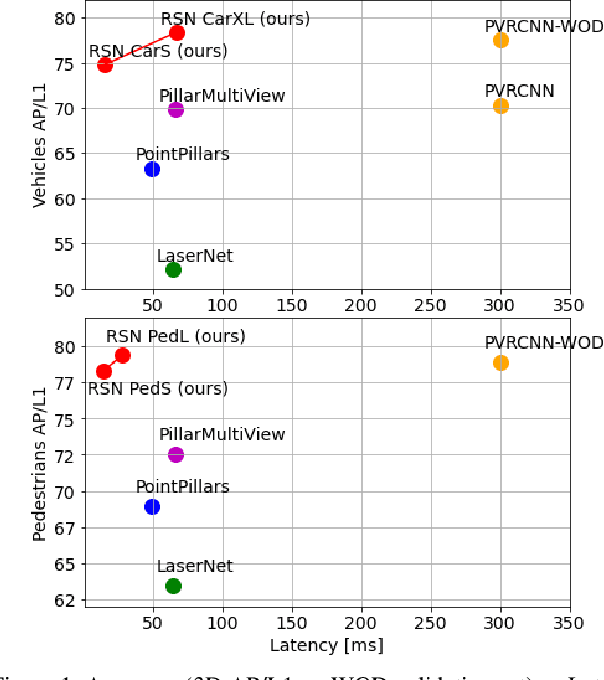
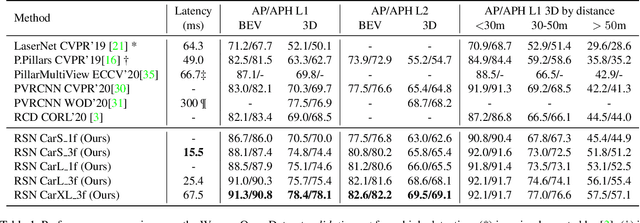
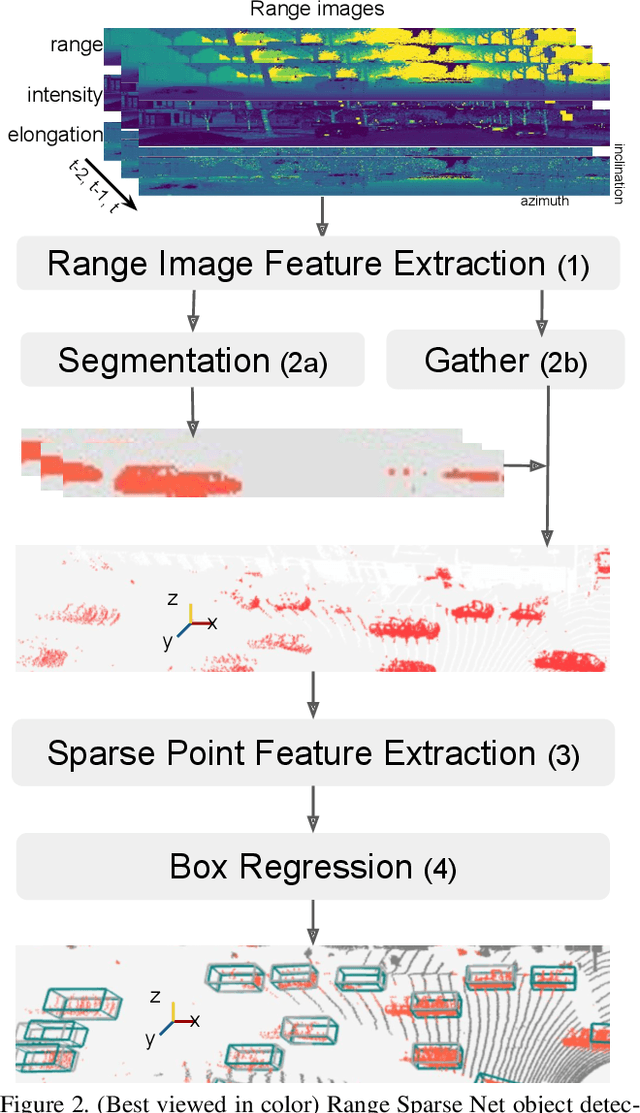
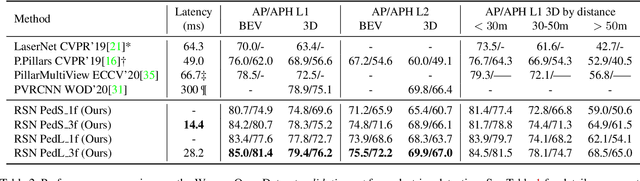
The detection of 3D objects from LiDAR data is a critical component in most autonomous driving systems. Safe, high speed driving needs larger detection ranges, which are enabled by new LiDARs. These larger detection ranges require more efficient and accurate detection models. Towards this goal, we propose Range Sparse Net (RSN), a simple, efficient, and accurate 3D object detector in order to tackle real time 3D object detection in this extended detection regime. RSN predicts foreground points from range images and applies sparse convolutions on the selected foreground points to detect objects. The lightweight 2D convolutions on dense range images results in significantly fewer selected foreground points, thus enabling the later sparse convolutions in RSN to efficiently operate. Combining features from the range image further enhance detection accuracy. RSN runs at more than 60 frames per second on a 150m x 150m detection region on Waymo Open Dataset (WOD) while being more accurate than previously published detectors. As of 11/2020, RSN is ranked first in the WOD leaderboard based on the APH/LEVEL 1 metrics for LiDAR-based pedestrian and vehicle detection, while being several times faster than alternatives.
Large Scale Interactive Motion Forecasting for Autonomous Driving : The Waymo Open Motion Dataset
Apr 20, 2021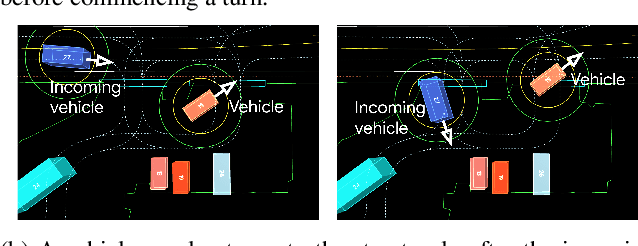
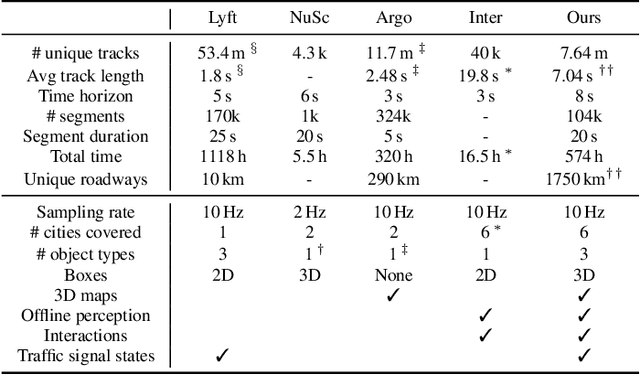
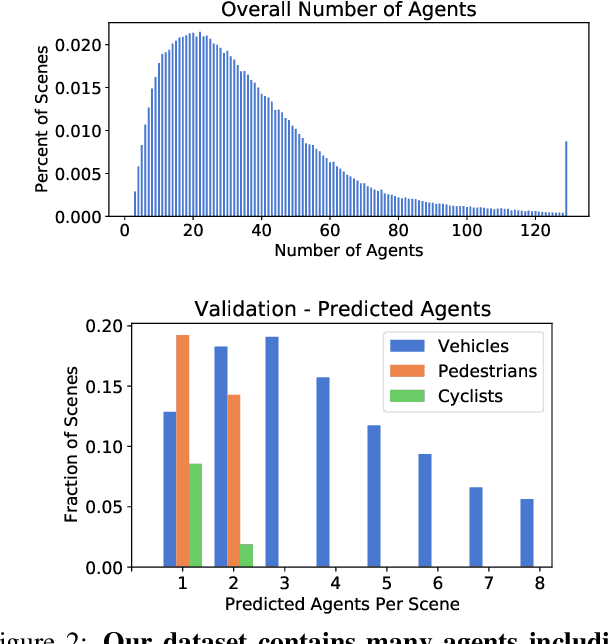
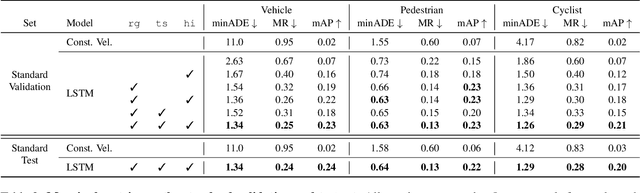
As autonomous driving systems mature, motion forecasting has received increasing attention as a critical requirement for planning. Of particular importance are interactive situations such as merges, unprotected turns, etc., where predicting individual object motion is not sufficient. Joint predictions of multiple objects are required for effective route planning. There has been a critical need for high-quality motion data that is rich in both interactions and annotation to develop motion planning models. In this work, we introduce the most diverse interactive motion dataset to our knowledge, and provide specific labels for interacting objects suitable for developing joint prediction models. With over 100,000 scenes, each 20 seconds long at 10 Hz, our new dataset contains more than 570 hours of unique data over 1750 km of roadways. It was collected by mining for interesting interactions between vehicles, pedestrians, and cyclists across six cities within the United States. We use a high-accuracy 3D auto-labeling system to generate high quality 3D bounding boxes for each road agent, and provide corresponding high definition 3D maps for each scene. Furthermore, we introduce a new set of metrics that provides a comprehensive evaluation of both single agent and joint agent interaction motion forecasting models. Finally, we provide strong baseline models for individual-agent prediction and joint-prediction. We hope that this new large-scale interactive motion dataset will provide new opportunities for advancing motion forecasting models.
Identifying Driver Interactions via Conditional Behavior Prediction
Apr 20, 2021
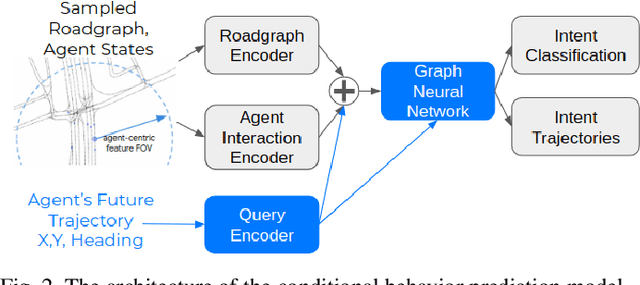
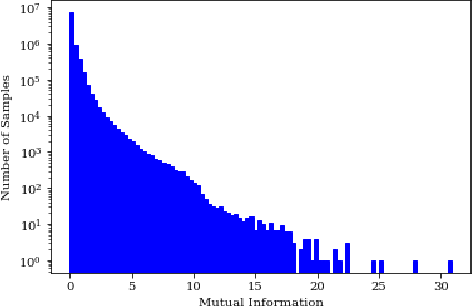
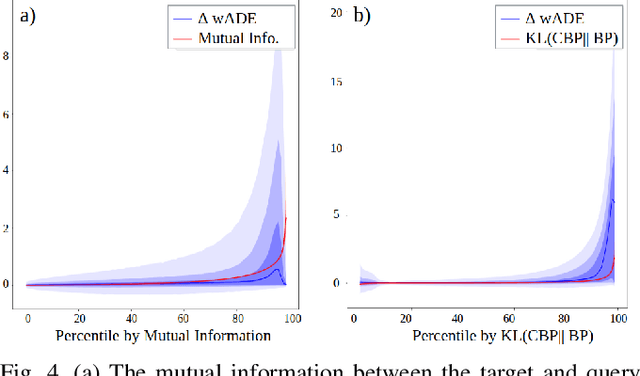
Interactive driving scenarios, such as lane changes, merges and unprotected turns, are some of the most challenging situations for autonomous driving. Planning in interactive scenarios requires accurately modeling the reactions of other agents to different future actions of the ego agent. We develop end-to-end models for conditional behavior prediction (CBP) that take as an input a query future trajectory for an ego-agent, and predict distributions over future trajectories for other agents conditioned on the query. Leveraging such a model, we develop a general-purpose agent interactivity score derived from probabilistic first principles. The interactivity score allows us to find interesting interactive scenarios for training and evaluating behavior prediction models. We further demonstrate that the proposed score is effective for agent prioritization under computational budget constraints.
Offboard 3D Object Detection from Point Cloud Sequences
Mar 08, 2021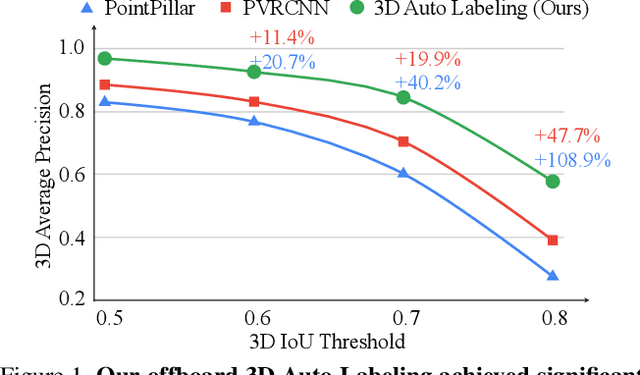
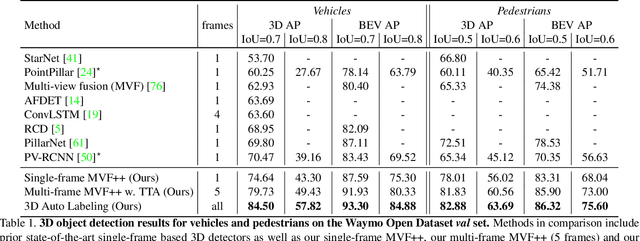
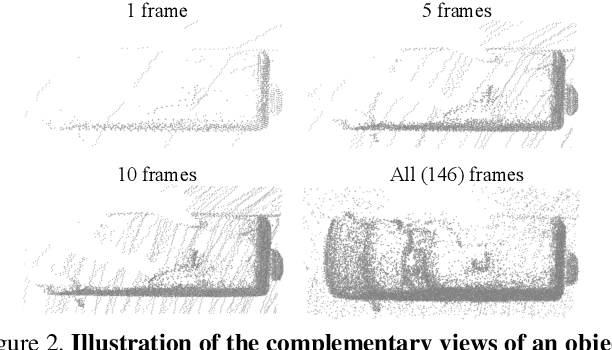

While current 3D object recognition research mostly focuses on the real-time, onboard scenario, there are many offboard use cases of perception that are largely under-explored, such as using machines to automatically generate high-quality 3D labels. Existing 3D object detectors fail to satisfy the high-quality requirement for offboard uses due to the limited input and speed constraints. In this paper, we propose a novel offboard 3D object detection pipeline using point cloud sequence data. Observing that different frames capture complementary views of objects, we design the offboard detector to make use of the temporal points through both multi-frame object detection and novel object-centric refinement models. Evaluated on the Waymo Open Dataset, our pipeline named 3D Auto Labeling shows significant gains compared to the state-of-the-art onboard detectors and our offboard baselines. Its performance is even on par with human labels verified through a human label study. Further experiments demonstrate the application of auto labels for semi-supervised learning and provide extensive analysis to validate various design choices.
Just Pick a Sign: Optimizing Deep Multitask Models with Gradient Sign Dropout
Oct 14, 2020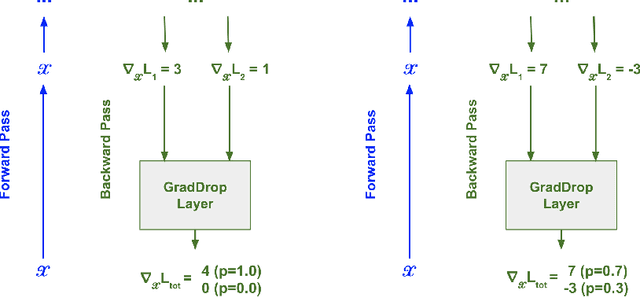
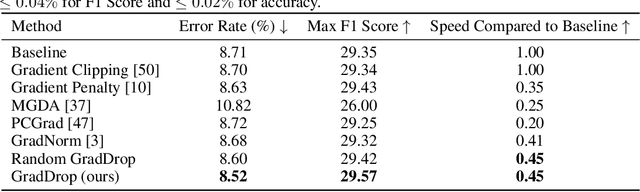
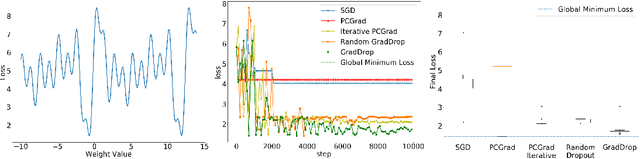
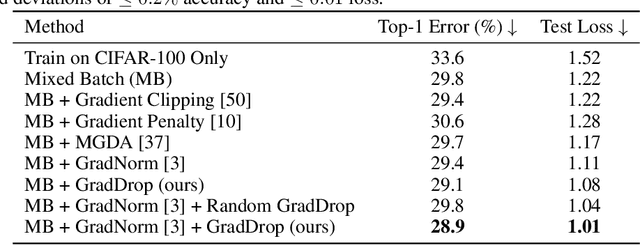
The vast majority of deep models use multiple gradient signals, typically corresponding to a sum of multiple loss terms, to update a shared set of trainable weights. However, these multiple updates can impede optimal training by pulling the model in conflicting directions. We present Gradient Sign Dropout (GradDrop), a probabilistic masking procedure which samples gradients at an activation layer based on their level of consistency. GradDrop is implemented as a simple deep layer that can be used in any deep net and synergizes with other gradient balancing approaches. We show that GradDrop outperforms the state-of-the-art multiloss methods within traditional multitask and transfer learning settings, and we discuss how GradDrop reveals links between optimal multiloss training and gradient stochasticity.
TNT: Target-driveN Trajectory Prediction
Aug 21, 2020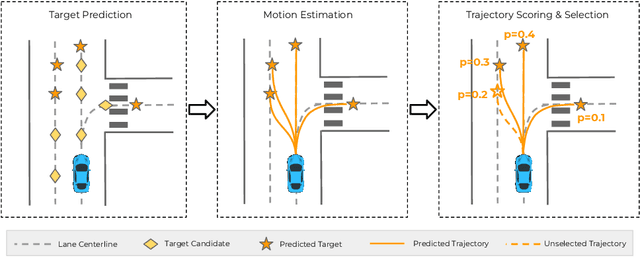
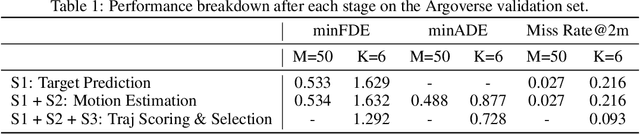
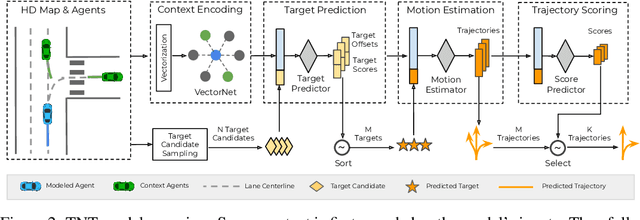
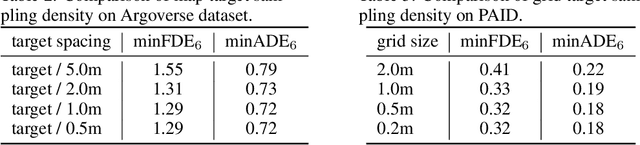
Predicting the future behavior of moving agents is essential for real world applications. It is challenging as the intent of the agent and the corresponding behavior is unknown and intrinsically multimodal. Our key insight is that for prediction within a moderate time horizon, the future modes can be effectively captured by a set of target states. This leads to our target-driven trajectory prediction (TNT) framework. TNT has three stages which are trained end-to-end. It first predicts an agent's potential target states $T$ steps into the future, by encoding its interactions with the environment and the other agents. TNT then generates trajectory state sequences conditioned on targets. A final stage estimates trajectory likelihoods and a final compact set of trajectory predictions is selected. This is in contrast to previous work which models agent intents as latent variables, and relies on test-time sampling to generate diverse trajectories. We benchmark TNT on trajectory prediction of vehicles and pedestrians, where we outperform state-of-the-art on Argoverse Forecasting, INTERACTION, Stanford Drone and an in-house Pedestrian-at-Intersection dataset.