 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransframer: Arbitrary Frame Prediction with Generative Models
Mar 18, 2022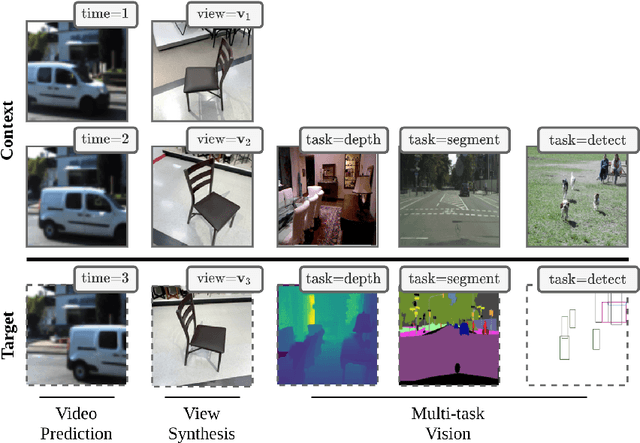

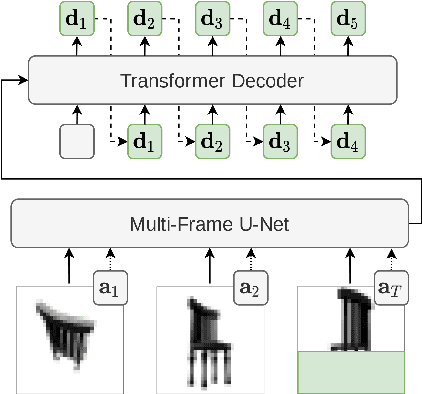

We present a general-purpose framework for image modelling and vision tasks based on probabilistic frame prediction. Our approach unifies a broad range of tasks, from image segmentation, to novel view synthesis and video interpolation. We pair this framework with an architecture we term Transframer, which uses U-Net and Transformer components to condition on annotated context frames, and outputs sequences of sparse, compressed image features. Transframer is the state-of-the-art on a variety of video generation benchmarks, is competitive with the strongest models on few-shot view synthesis, and can generate coherent 30 second videos from a single image without any explicit geometric information. A single generalist Transframer simultaneously produces promising results on 8 tasks, including semantic segmentation, image classification and optical flow prediction with no task-specific architectural components, demonstrating that multi-task computer vision can be tackled using probabilistic image models. Our approach can in principle be applied to a wide range of applications that require learning the conditional structure of annotated image-formatted data.
General-purpose, long-context autoregressive modeling with Perceiver AR
Feb 15, 2022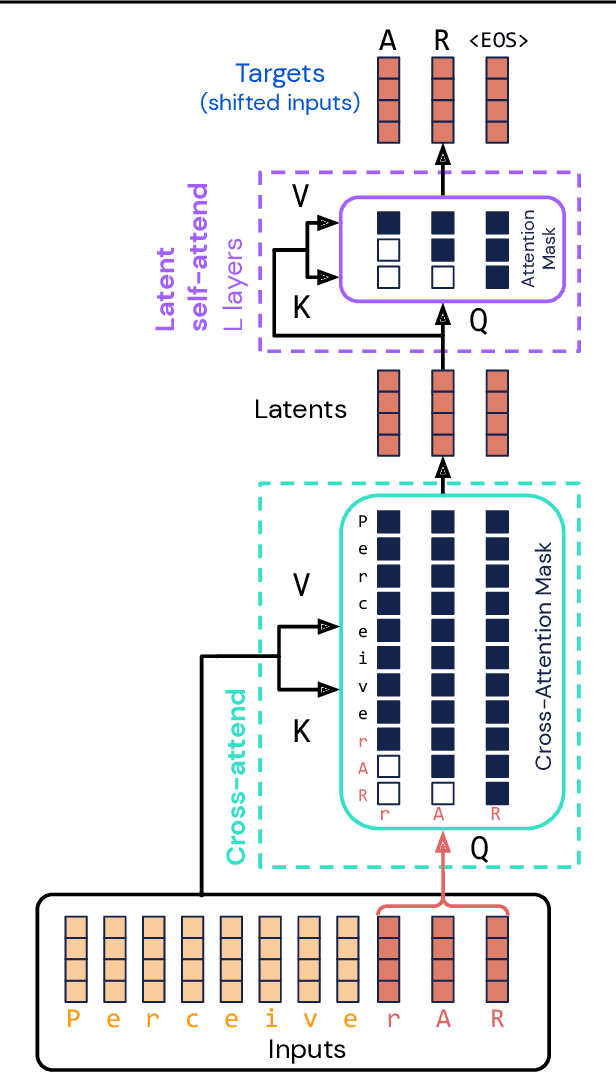
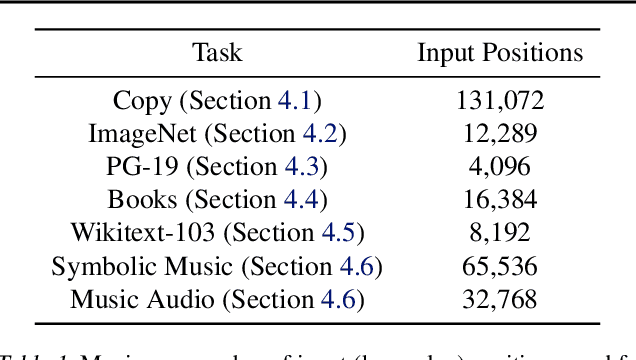
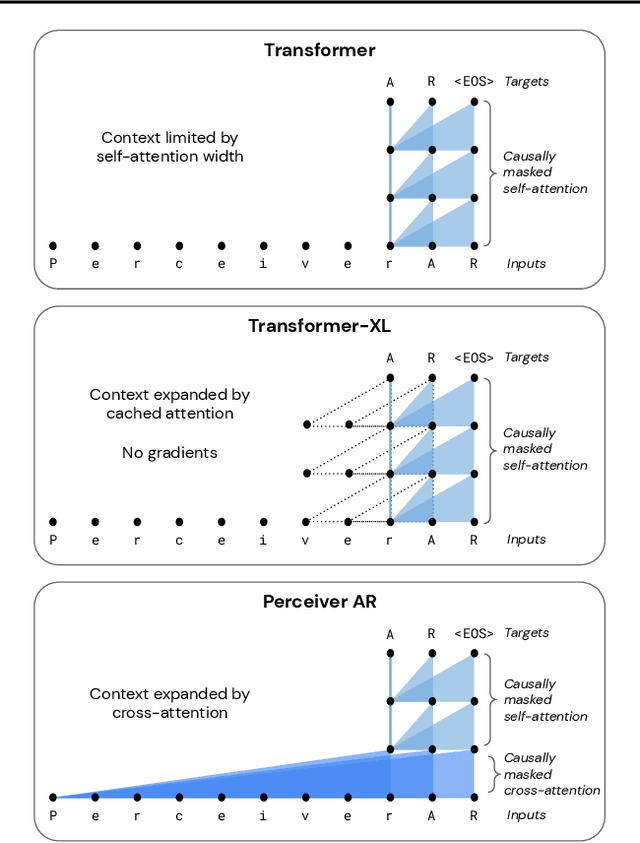
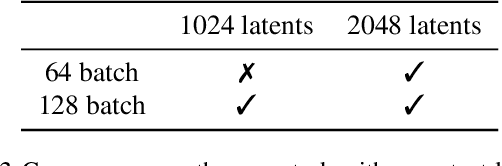
Real-world data is high-dimensional: a book, image, or musical performance can easily contain hundreds of thousands of elements even after compression. However, the most commonly used autoregressive models, Transformers, are prohibitively expensive to scale to the number of inputs and layers needed to capture this long-range structure. We develop Perceiver AR, an autoregressive, modality-agnostic architecture which uses cross-attention to map long-range inputs to a small number of latents while also maintaining end-to-end causal masking. Perceiver AR can directly attend to over a hundred thousand tokens, enabling practical long-context density estimation without the need for hand-crafted sparsity patterns or memory mechanisms. When trained on images or music, Perceiver AR generates outputs with clear long-term coherence and structure. Our architecture also obtains state-of-the-art likelihood on long-sequence benchmarks, including 64 x 64 ImageNet images and PG-19 books.
HDMapGen: A Hierarchical Graph Generative Model of High Definition Maps
Jun 28, 2021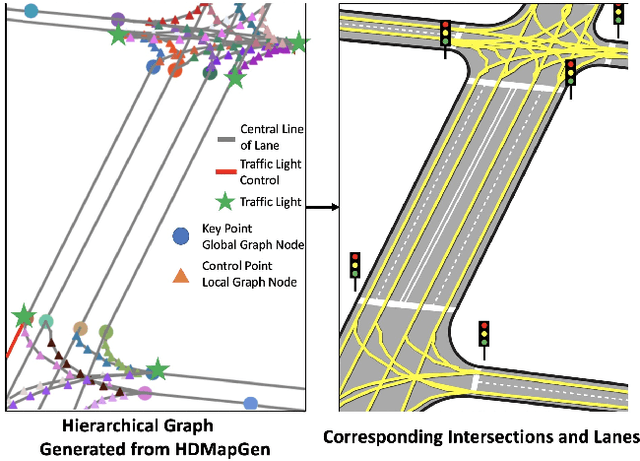
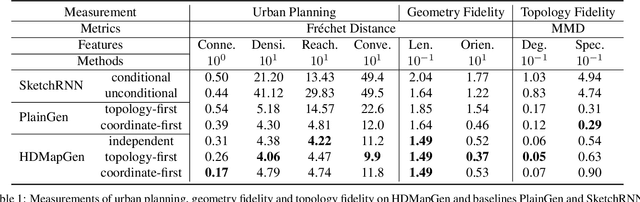
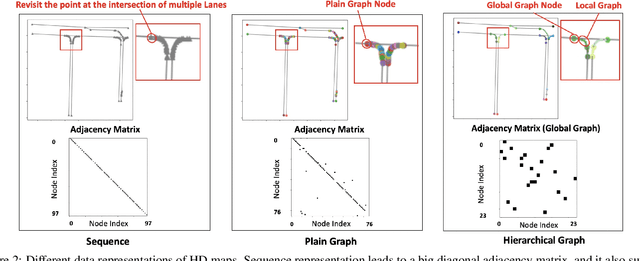

High Definition (HD) maps are maps with precise definitions of road lanes with rich semantics of the traffic rules. They are critical for several key stages in an autonomous driving system, including motion forecasting and planning. However, there are only a small amount of real-world road topologies and geometries, which significantly limits our ability to test out the self-driving stack to generalize onto new unseen scenarios. To address this issue, we introduce a new challenging task to generate HD maps. In this work, we explore several autoregressive models using different data representations, including sequence, plain graph, and hierarchical graph. We propose HDMapGen, a hierarchical graph generation model capable of producing high-quality and diverse HD maps through a coarse-to-fine approach. Experiments on the Argoverse dataset and an in-house dataset show that HDMapGen significantly outperforms baseline methods. Additionally, we demonstrate that HDMapGen achieves high scalability and efficiency.
Variable-rate discrete representation learning
Mar 10, 2021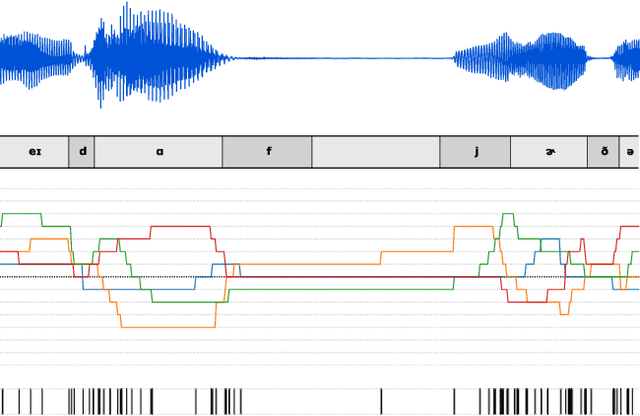

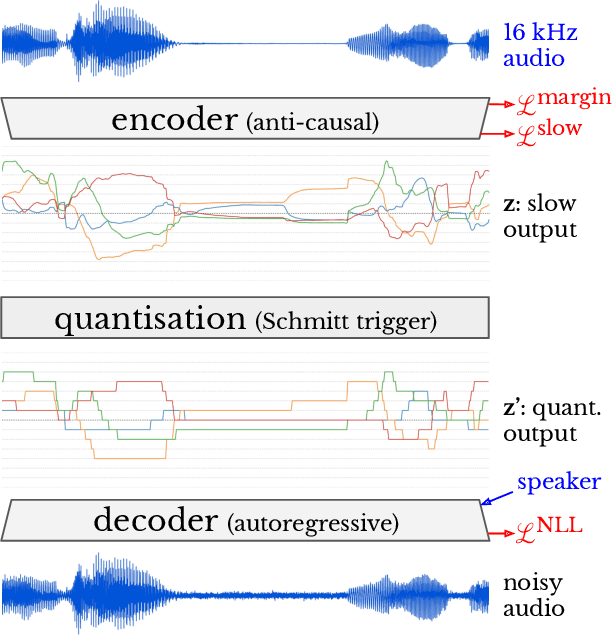

Semantically meaningful information content in perceptual signals is usually unevenly distributed. In speech signals for example, there are often many silences, and the speed of pronunciation can vary considerably. In this work, we propose slow autoencoders (SlowAEs) for unsupervised learning of high-level variable-rate discrete representations of sequences, and apply them to speech. We show that the resulting event-based representations automatically grow or shrink depending on the density of salient information in the input signals, while still allowing for faithful signal reconstruction. We develop run-length Transformers (RLTs) for event-based representation modelling and use them to construct language models in the speech domain, which are able to generate grammatical and semantically coherent utterances and continuations.
Generating Images with Sparse Representations
Mar 05, 2021
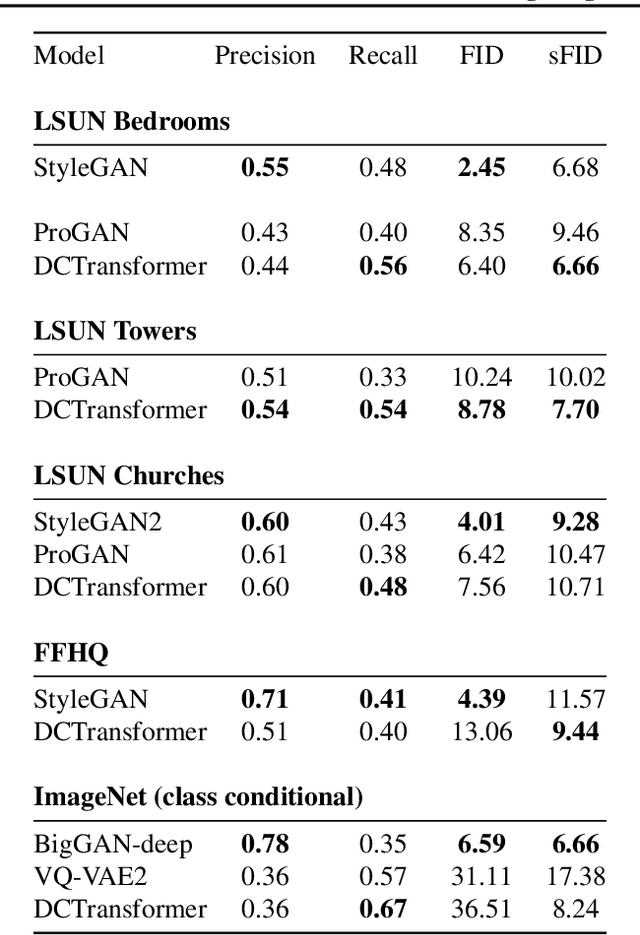
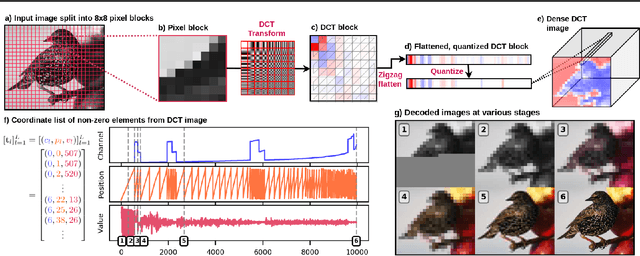
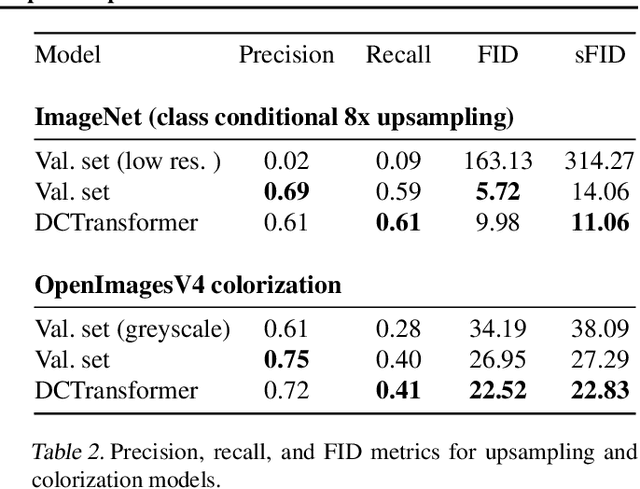
The high dimensionality of images presents architecture and sampling-efficiency challenges for likelihood-based generative models. Previous approaches such as VQ-VAE use deep autoencoders to obtain compact representations, which are more practical as inputs for likelihood-based models. We present an alternative approach, inspired by common image compression methods like JPEG, and convert images to quantized discrete cosine transform (DCT) blocks, which are represented sparsely as a sequence of DCT channel, spatial location, and DCT coefficient triples. We propose a Transformer-based autoregressive architecture, which is trained to sequentially predict the conditional distribution of the next element in such sequences, and which scales effectively to high resolution images. On a range of image datasets, we demonstrate that our approach can generate high quality, diverse images, with sample metric scores competitive with state of the art methods. We additionally show that simple modifications to our method yield effective image colorization and super-resolution models.
PolyGen: An Autoregressive Generative Model of 3D Meshes
Feb 23, 2020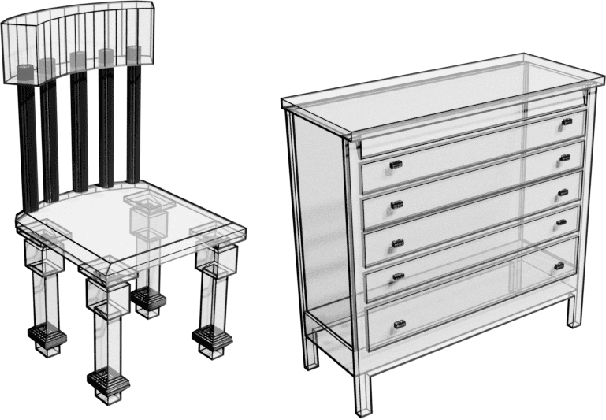
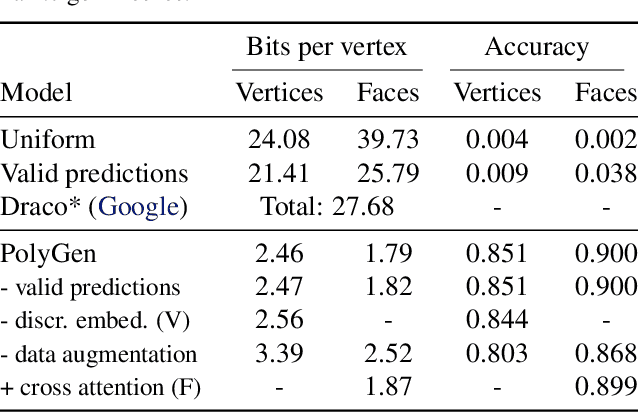
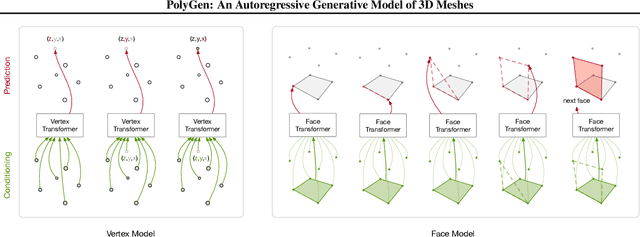
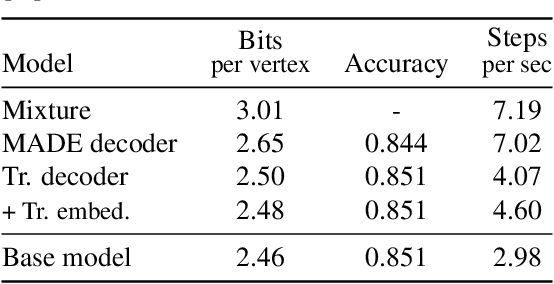
Polygon meshes are an efficient representation of 3D geometry, and are of central importance in computer graphics, robotics and games development. Existing learning-based approaches have avoided the challenges of working with 3D meshes, instead using alternative object representations that are more compatible with neural architectures and training approaches. We present an approach which models the mesh directly, predicting mesh vertices and faces sequentially using a Transformer-based architecture. Our model can condition on a range of inputs, including object classes, voxels, and images, and because the model is probabilistic it can produce samples that capture uncertainty in ambiguous scenarios. We show that the model is capable of producing high-quality, usable meshes, and establish log-likelihood benchmarks for the mesh-modelling task. We also evaluate the conditional models on surface reconstruction metrics against alternative methods, and demonstrate competitive performance despite not training directly on this task.
Efficient Graph Generation with Graph Recurrent Attention Networks
Oct 02, 2019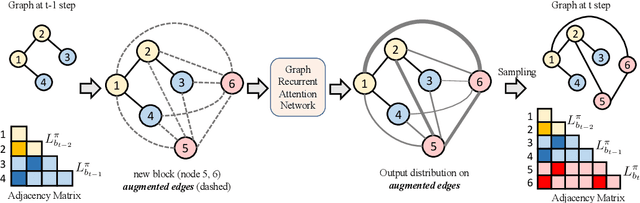
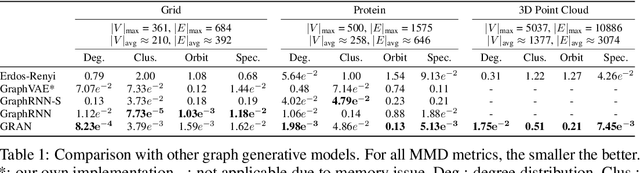
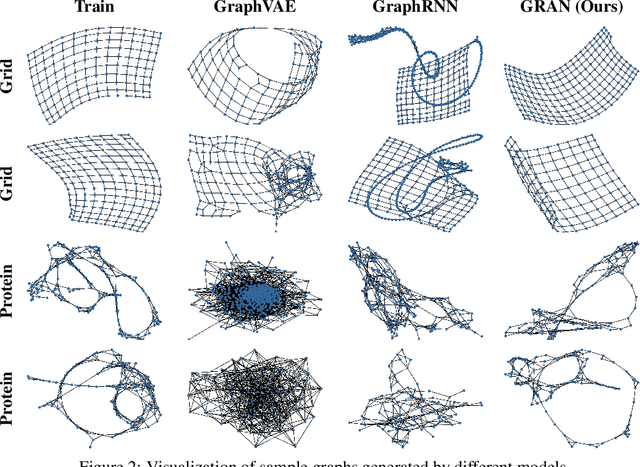
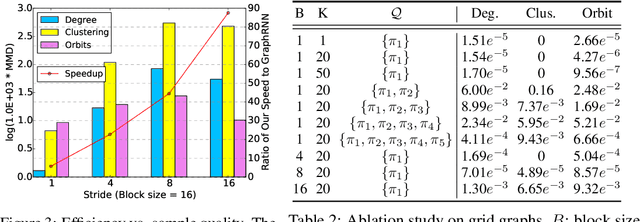
We propose a new family of efficient and expressive deep generative models of graphs, called Graph Recurrent Attention Networks (GRANs). Our model generates graphs one block of nodes and associated edges at a time. The block size and sampling stride allow us to trade off sample quality for efficiency. Compared to previous RNN-based graph generative models, our framework better captures the auto-regressive conditioning between the already-generated and to-be-generated parts of the graph using Graph Neural Networks (GNNs) with attention. This not only reduces the dependency on node ordering but also bypasses the long-term bottleneck caused by the sequential nature of RNNs. Moreover, we parameterize the output distribution per block using a mixture of Bernoulli, which captures the correlations among generated edges within the block. Finally, we propose to handle node orderings in generation by marginalizing over a family of canonical orderings. On standard benchmarks, we achieve state-of-the-art time efficiency and sample quality compared to previous models. Additionally, we show our model is capable of generating large graphs of up to 5K nodes with good quality. To the best of our knowledge, GRAN is the first deep graph generative model that can scale to this size. Our code is released at: https://github.com/lrjconan/GRAN.
Autoregressive Energy Machines
Apr 11, 2019

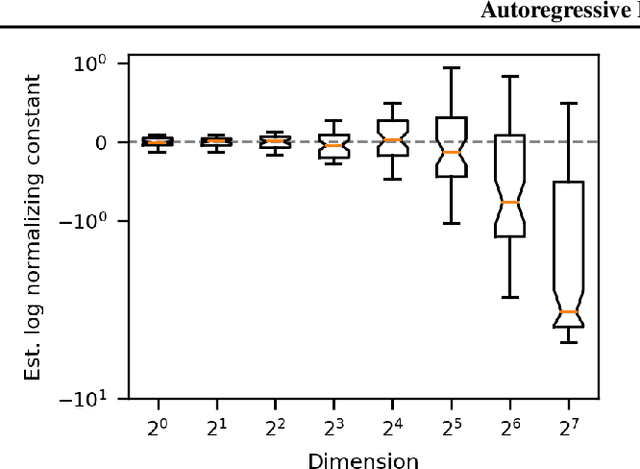
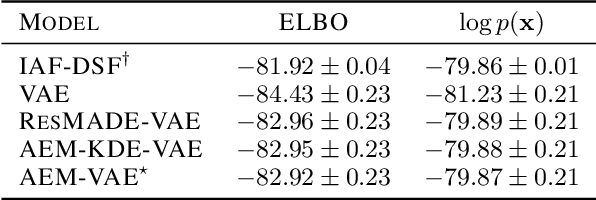
Neural density estimators are flexible families of parametric models which have seen widespread use in unsupervised machine learning in recent years. Maximum-likelihood training typically dictates that these models be constrained to specify an explicit density. However, this limitation can be overcome by instead using a neural network to specify an energy function, or unnormalized density, which can subsequently be normalized to obtain a valid distribution. The challenge with this approach lies in accurately estimating the normalizing constant of the high-dimensional energy function. We propose the Autoregressive Energy Machine, an energy-based model which simultaneously learns an unnormalized density and computes an importance-sampling estimate of the normalizing constant for each conditional in an autoregressive decomposition. The Autoregressive Energy Machine achieves state-of-the-art performance on a suite of density-estimation tasks.
Autoencoders and Probabilistic Inference with Missing Data: An Exact Solution for The Factor Analysis Case
Sep 03, 2018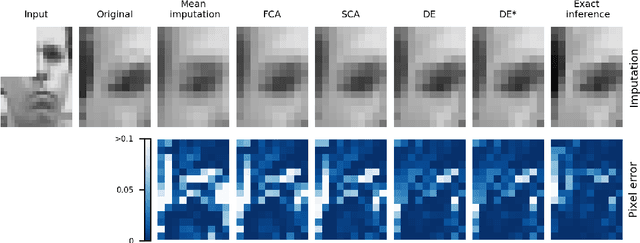



Latent variable models can be used to probabilistically "fill-in" missing data entries. The variational autoencoder architecture (Kingma and Welling, 2014; Rezende et al., 2014) includes a "recognition" or "encoder" network that infers the latent variables given the data variables. However, it is not clear how to handle missing data variables in this network. The factor analysis (FA) model is a basic autoencoder, using linear encoder and decoder networks. We show how to calculate exactly the latent posterior distribution for the factor analysis (FA) model in the presence of missing data, and note that this solution exhibits a non-trivial dependence on the pattern of missingness. We also discuss various approximations to the exact solution. Experiments compare the effectiveness of various approaches to filling in the missing data.
Inverting Supervised Representations with Autoregressive Neural Density Models
Jun 01, 2018



Understanding the nature of representations learned by supervised machine learning models is a significant goal in the machine learning community. We present a method for feature interpretation that makes use of recent advances in autoregressive density estimation models to invert model representations. We train generative inversion models to express a distribution over input features conditioned on intermediate model representations. Insights into the invariances learned by supervised models can be gained by viewing samples from these inversion models. In addition, we can use these inversion models to estimate the mutual information between a model's inputs and its intermediate representations, thus quantifying the amount of information preserved by the network at different stages. Using this method we examine the types of information preserved at different layers of convolutional neural networks, and explore the invariances induced by different architectural choices. Finally we show that the mutual information between inputs and network layers decreases over the course of training, supporting recent work by Shwartz-Ziv and Tishby (2017) on the information bottleneck theory of deep learning.