 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLidarAugment: Searching for Scalable 3D LiDAR Data Augmentations
Oct 24, 2022



Data augmentations are important in training high-performance 3D object detectors for point clouds. Despite recent efforts on designing new data augmentations, perhaps surprisingly, most state-of-the-art 3D detectors only use a few simple data augmentations. In particular, different from 2D image data augmentations, 3D data augmentations need to account for different representations of input data and require being customized for different models, which introduces significant overhead. In this paper, we resort to a search-based approach, and propose LidarAugment, a practical and effective data augmentation strategy for 3D object detection. Unlike previous approaches where all augmentation policies are tuned in an exponentially large search space, we propose to factorize and align the search space of each data augmentation, which cuts down the 20+ hyperparameters to 2, and significantly reduces the search complexity. We show LidarAugment can be customized for different model architectures with different input representations by a simple 2D grid search, and consistently improve both convolution-based UPillars/StarNet/RSN and transformer-based SWFormer. Furthermore, LidarAugment mitigates overfitting and allows us to scale up 3D detectors to much larger capacity. In particular, by combining with latest 3D detectors, our LidarAugment achieves a new state-of-the-art 74.8 mAPH L2 on Waymo Open Dataset.
Hierarchical Model-Based Imitation Learning for Planning in Autonomous Driving
Oct 18, 2022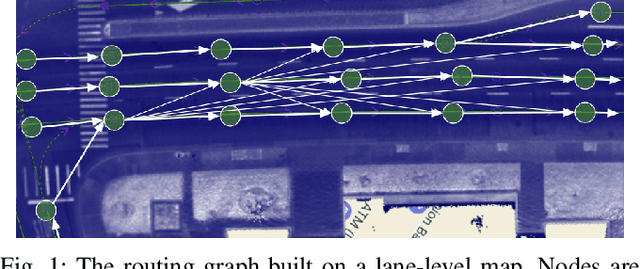
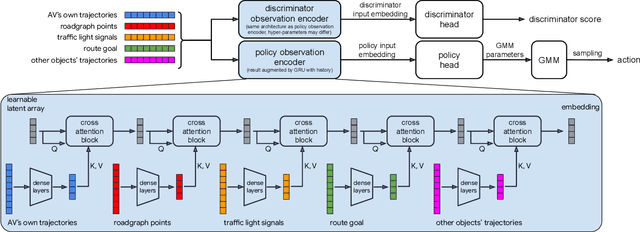
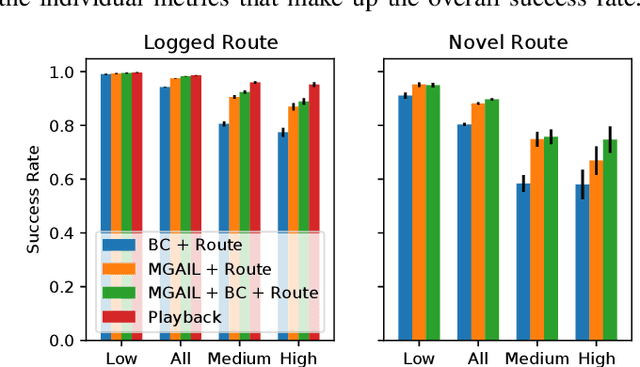
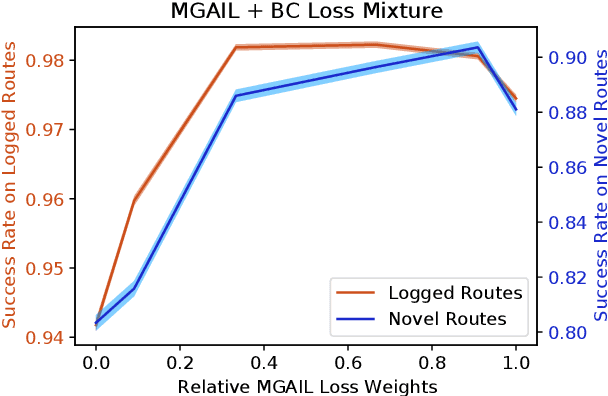
We demonstrate the first large-scale application of model-based generative adversarial imitation learning (MGAIL) to the task of dense urban self-driving. We augment standard MGAIL using a hierarchical model to enable generalization to arbitrary goal routes, and measure performance using a closed-loop evaluation framework with simulated interactive agents. We train policies from expert trajectories collected from real vehicles driving over 100,000 miles in San Francisco, and demonstrate a steerable policy that can navigate robustly even in a zero-shot setting, generalizing to synthetic scenarios with novel goals that never occurred in real-world driving. We also demonstrate the importance of mixing closed-loop MGAIL losses with open-loop behavior cloning losses, and show our best policy approaches the performance of the expert. We evaluate our imitative model in both average and challenging scenarios, and show how it can serve as a useful prior to plan successful trajectories.
CramNet: Camera-Radar Fusion with Ray-Constrained Cross-Attention for Robust 3D Object Detection
Oct 18, 2022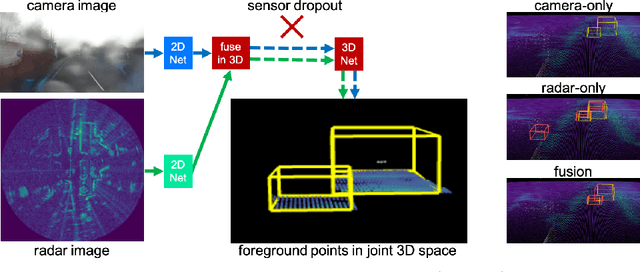

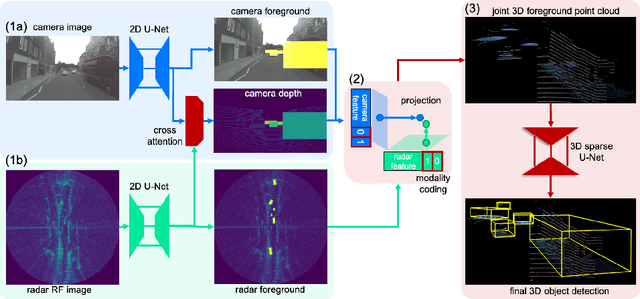
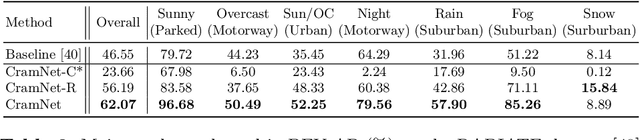
Robust 3D object detection is critical for safe autonomous driving. Camera and radar sensors are synergistic as they capture complementary information and work well under different environmental conditions. Fusing camera and radar data is challenging, however, as each of the sensors lacks information along a perpendicular axis, that is, depth is unknown to camera and elevation is unknown to radar. We propose the camera-radar matching network CramNet, an efficient approach to fuse the sensor readings from camera and radar in a joint 3D space. To leverage radar range measurements for better camera depth predictions, we propose a novel ray-constrained cross-attention mechanism that resolves the ambiguity in the geometric correspondences between camera features and radar features. Our method supports training with sensor modality dropout, which leads to robust 3D object detection, even when a camera or radar sensor suddenly malfunctions on a vehicle. We demonstrate the effectiveness of our fusion approach through extensive experiments on the RADIATE dataset, one of the few large-scale datasets that provide radar radio frequency imagery. A camera-only variant of our method achieves competitive performance in monocular 3D object detection on the Waymo Open Dataset.
Improving the Intra-class Long-tail in 3D Detection via Rare Example Mining
Oct 15, 2022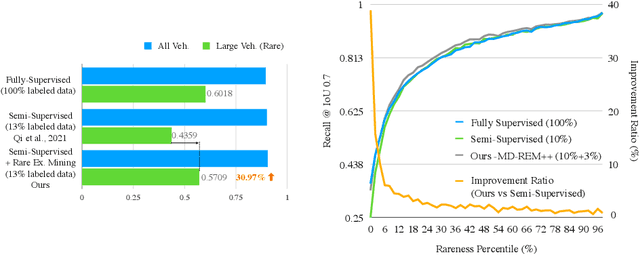
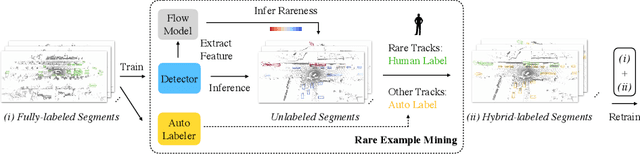
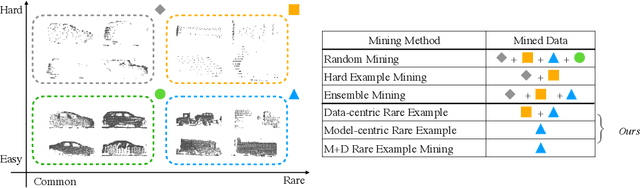
Continued improvements in deep learning architectures have steadily advanced the overall performance of 3D object detectors to levels on par with humans for certain tasks and datasets, where the overall performance is mostly driven by common examples. However, even the best performing models suffer from the most naive mistakes when it comes to rare examples that do not appear frequently in the training data, such as vehicles with irregular geometries. Most studies in the long-tail literature focus on class-imbalanced classification problems with known imbalanced label counts per class, but they are not directly applicable to the intra-class long-tail examples in problems with large intra-class variations such as 3D object detection, where instances with the same class label can have drastically varied properties such as shapes and sizes. Other works propose to mitigate this problem using active learning based on the criteria of uncertainty, difficulty, or diversity. In this study, we identify a new conceptual dimension - rareness - to mine new data for improving the long-tail performance of models. We show that rareness, as opposed to difficulty, is the key to data-centric improvements for 3D detectors, since rareness is the result of a lack in data support while difficulty is related to the fundamental ambiguity in the problem. We propose a general and effective method to identify the rareness of objects based on density estimation in the feature space using flow models, and propose a principled cost-aware formulation for mining rare object tracks, which improves overall model performance, but more importantly - significantly improves the performance for rare objects (by 30.97\%
Motion Inspired Unsupervised Perception and Prediction in Autonomous Driving
Oct 14, 2022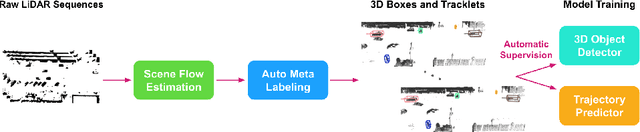
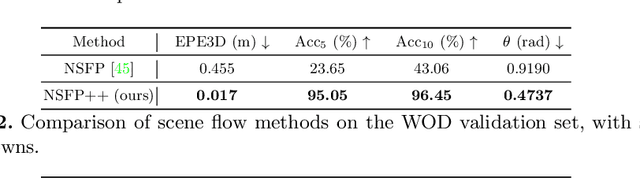

Learning-based perception and prediction modules in modern autonomous driving systems typically rely on expensive human annotation and are designed to perceive only a handful of predefined object categories. This closed-set paradigm is insufficient for the safety-critical autonomous driving task, where the autonomous vehicle needs to process arbitrarily many types of traffic participants and their motion behaviors in a highly dynamic world. To address this difficulty, this paper pioneers a novel and challenging direction, i.e., training perception and prediction models to understand open-set moving objects, with no human supervision. Our proposed framework uses self-learned flow to trigger an automated meta labeling pipeline to achieve automatic supervision. 3D detection experiments on the Waymo Open Dataset show that our method significantly outperforms classical unsupervised approaches and is even competitive to the counterpart with supervised scene flow. We further show that our approach generates highly promising results in open-set 3D detection and trajectory prediction, confirming its potential in closing the safety gap of fully supervised systems.
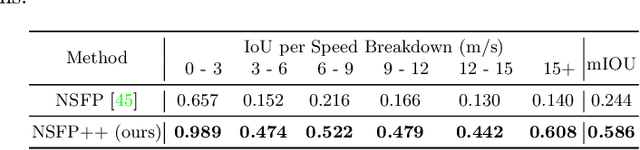
LESS: Label-Efficient Semantic Segmentation for LiDAR Point Clouds
Oct 14, 2022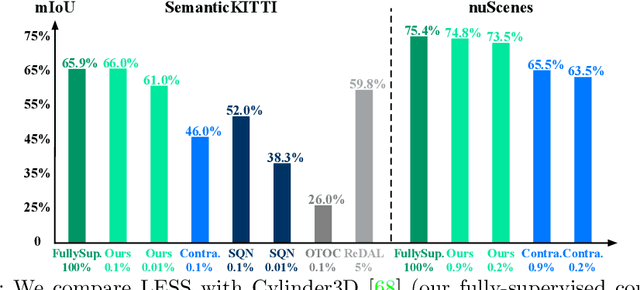
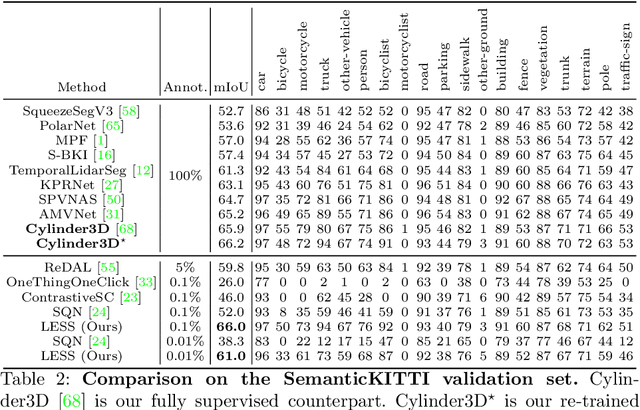
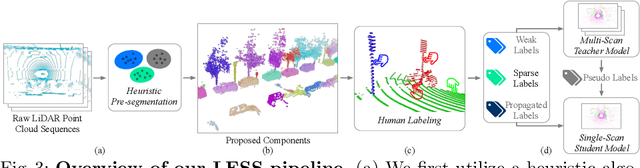
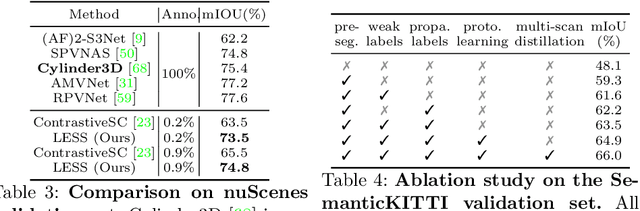
Semantic segmentation of LiDAR point clouds is an important task in autonomous driving. However, training deep models via conventional supervised methods requires large datasets which are costly to label. It is critical to have label-efficient segmentation approaches to scale up the model to new operational domains or to improve performance on rare cases. While most prior works focus on indoor scenes, we are one of the first to propose a label-efficient semantic segmentation pipeline for outdoor scenes with LiDAR point clouds. Our method co-designs an efficient labeling process with semi/weakly supervised learning and is applicable to nearly any 3D semantic segmentation backbones. Specifically, we leverage geometry patterns in outdoor scenes to have a heuristic pre-segmentation to reduce the manual labeling and jointly design the learning targets with the labeling process. In the learning step, we leverage prototype learning to get more descriptive point embeddings and use multi-scan distillation to exploit richer semantics from temporally aggregated point clouds to boost the performance of single-scan models. Evaluated on the SemanticKITTI and the nuScenes datasets, we show that our proposed method outperforms existing label-efficient methods. With extremely limited human annotations (e.g., 0.1% point labels), our proposed method is even highly competitive compared to the fully supervised counterpart with 100% labels.
SWFormer: Sparse Window Transformer for 3D Object Detection in Point Clouds
Oct 13, 2022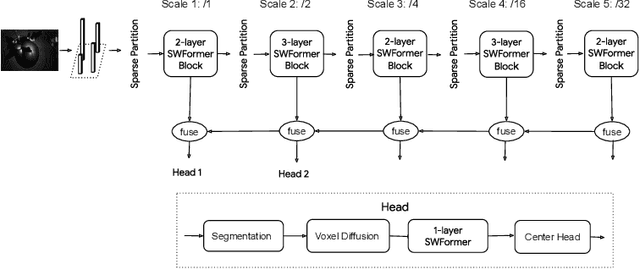
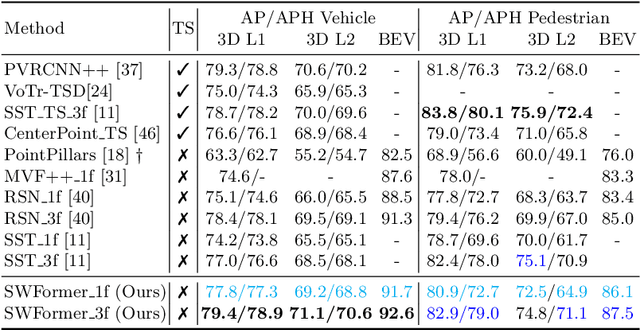
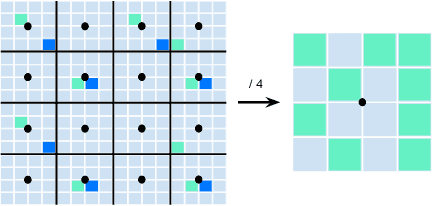

3D object detection in point clouds is a core component for modern robotics and autonomous driving systems. A key challenge in 3D object detection comes from the inherent sparse nature of point occupancy within the 3D scene. In this paper, we propose Sparse Window Transformer (SWFormer ), a scalable and accurate model for 3D object detection, which can take full advantage of the sparsity of point clouds. Built upon the idea of window-based Transformers, SWFormer converts 3D points into sparse voxels and windows, and then processes these variable-length sparse windows efficiently using a bucketing scheme. In addition to self-attention within each spatial window, our SWFormer also captures cross-window correlation with multi-scale feature fusion and window shifting operations. To further address the unique challenge of detecting 3D objects accurately from sparse features, we propose a new voxel diffusion technique. Experimental results on the Waymo Open Dataset show our SWFormer achieves state-of-the-art 73.36 L2 mAPH on vehicle and pedestrian for 3D object detection on the official test set, outperforming all previous single-stage and two-stage models, while being much more efficient.
LidarNAS: Unifying and Searching Neural Architectures for 3D Point Clouds
Oct 10, 2022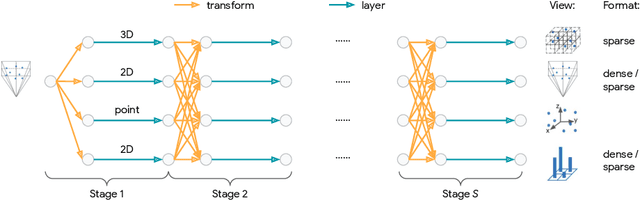
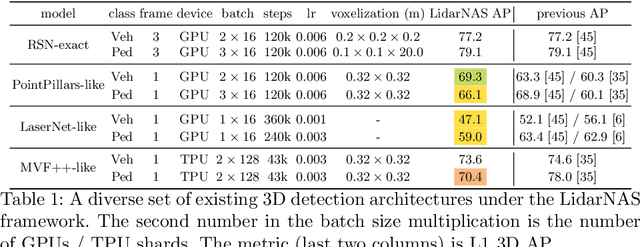

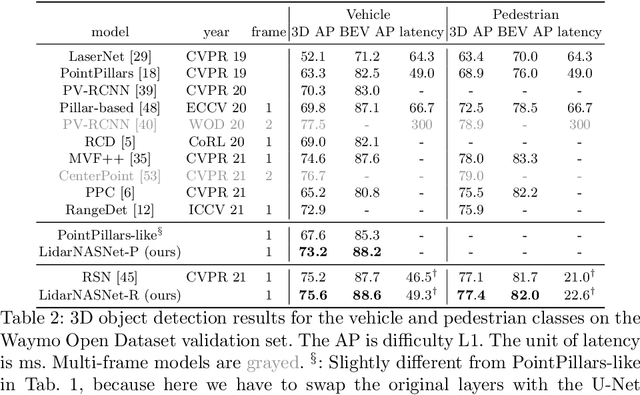
Developing neural models that accurately understand objects in 3D point clouds is essential for the success of robotics and autonomous driving. However, arguably due to the higher-dimensional nature of the data (as compared to images), existing neural architectures exhibit a large variety in their designs, including but not limited to the views considered, the format of the neural features, and the neural operations used. Lack of a unified framework and interpretation makes it hard to put these designs in perspective, as well as systematically explore new ones. In this paper, we begin by proposing a unified framework of such, with the key idea being factorizing the neural networks into a series of view transforms and neural layers. We demonstrate that this modular framework can reproduce a variety of existing works while allowing a fair comparison of backbone designs. Then, we show how this framework can easily materialize into a concrete neural architecture search (NAS) space, allowing a principled NAS-for-3D exploration. In performing evolutionary NAS on the 3D object detection task on the Waymo Open Dataset, not only do we outperform the state-of-the-art models, but also report the interesting finding that NAS tends to discover the same macro-level architecture concept for both the vehicle and pedestrian classes.
LET-3D-AP: Longitudinal Error Tolerant 3D Average Precision for Camera-Only 3D Detection
Jun 15, 2022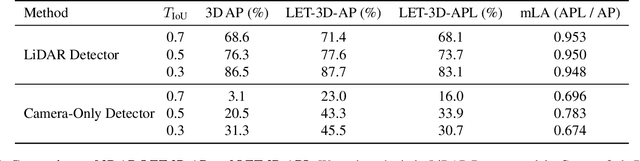
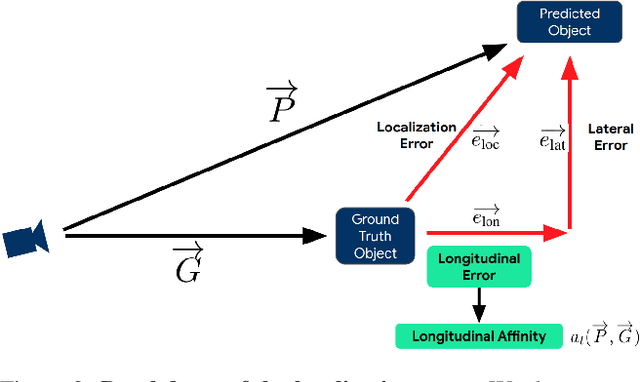
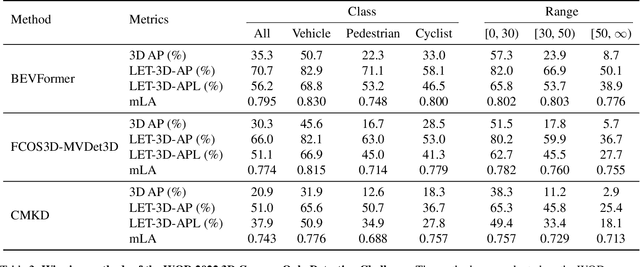
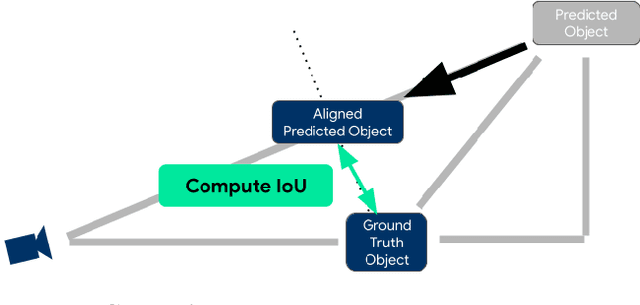
The popular object detection metric 3D Average Precision (3D AP) relies on the intersection over union between predicted bounding boxes and ground truth bounding boxes. However, depth estimation based on cameras has limited accuracy, which may cause otherwise reasonable predictions that suffer from such longitudinal localization errors to be treated as false positives and false negatives. We therefore propose variants of the popular 3D AP metric that are designed to be more permissive with respect to depth estimation errors. Specifically, our novel longitudinal error tolerant metrics, LET-3D-AP and LET-3D-APL, allow longitudinal localization errors of the predicted bounding boxes up to a given tolerance. The proposed metrics have been used in the Waymo Open Dataset 3D Camera-Only Detection Challenge. We believe that they will facilitate advances in the field of camera-only 3D detection by providing more informative performance signals.
Waymo Open Dataset: Panoramic Video Panoptic Segmentation
Jun 15, 2022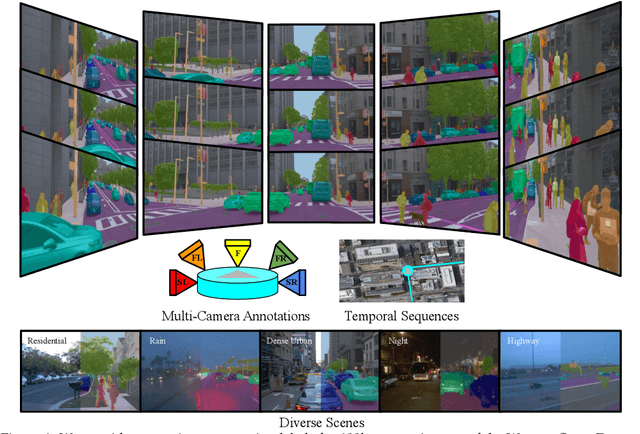

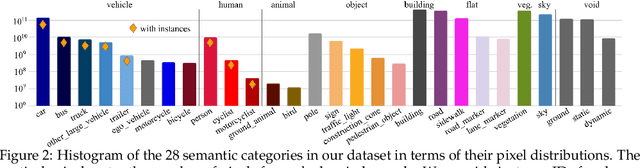
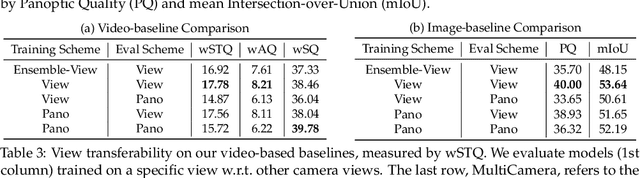
Panoptic image segmentation is the computer vision task of finding groups of pixels in an image and assigning semantic classes and object instance identifiers to them. Research in image segmentation has become increasingly popular due to its critical applications in robotics and autonomous driving. The research community thereby relies on publicly available benchmark dataset to advance the state-of-the-art in computer vision. Due to the high costs of densely labeling the images, however, there is a shortage of publicly available ground truth labels that are suitable for panoptic segmentation. The high labeling costs also make it challenging to extend existing datasets to the video domain and to multi-camera setups. We therefore present the Waymo Open Dataset: Panoramic Video Panoptic Segmentation Dataset, a large-scale dataset that offers high-quality panoptic segmentation labels for autonomous driving. We generate our dataset using the publicly available Waymo Open Dataset, leveraging the diverse set of camera images. Our labels are consistent over time for video processing and consistent across multiple cameras mounted on the vehicles for full panoramic scene understanding. Specifically, we offer labels for 28 semantic categories and 2,860 temporal sequences that were captured by five cameras mounted on autonomous vehicles driving in three different geographical locations, leading to a total of 100k labeled camera images. To the best of our knowledge, this makes our dataset an order of magnitude larger than existing datasets that offer video panoptic segmentation labels. We further propose a new benchmark for Panoramic Video Panoptic Segmentation and establish a number of strong baselines based on the DeepLab family of models. We will make the benchmark and the code publicly available. Find the dataset at https://waymo.com/open.