 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImaging with Equivariant Deep Learning
Sep 05, 2022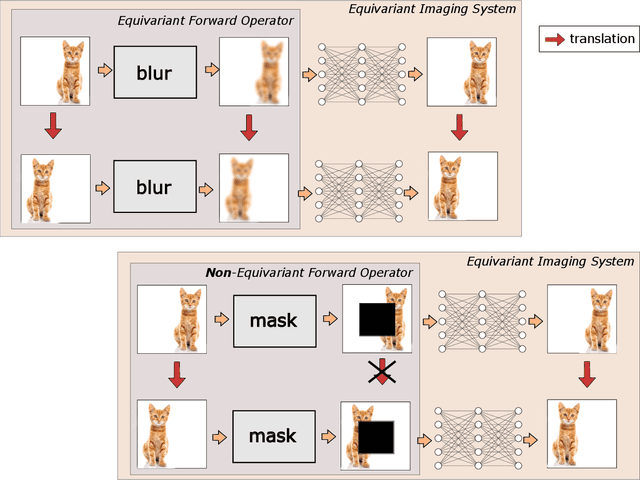

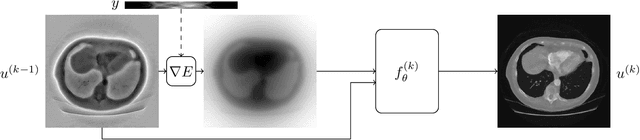

From early image processing to modern computational imaging, successful models and algorithms have relied on a fundamental property of natural signals: symmetry. Here symmetry refers to the invariance property of signal sets to transformations such as translation, rotation or scaling. Symmetry can also be incorporated into deep neural networks in the form of equivariance, allowing for more data-efficient learning. While there has been important advances in the design of end-to-end equivariant networks for image classification in recent years, computational imaging introduces unique challenges for equivariant network solutions since we typically only observe the image through some noisy ill-conditioned forward operator that itself may not be equivariant. We review the emerging field of equivariant imaging and show how it can provide improved generalization and new imaging opportunities. Along the way we show the interplay between the acquisition physics and group actions and links to iterative reconstruction, blind compressed sensing and self-supervised learning.
MaskCLIP: Masked Self-Distillation Advances Contrastive Language-Image Pretraining
Aug 25, 2022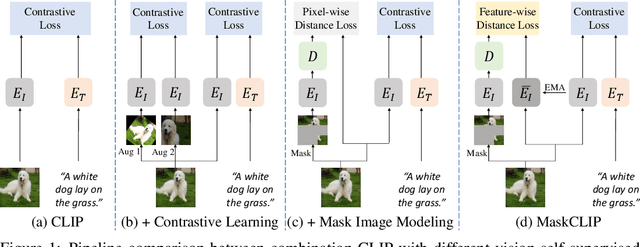
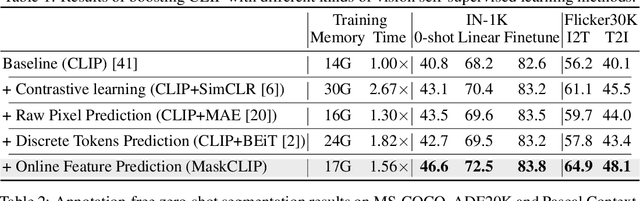
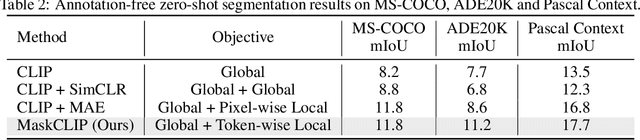
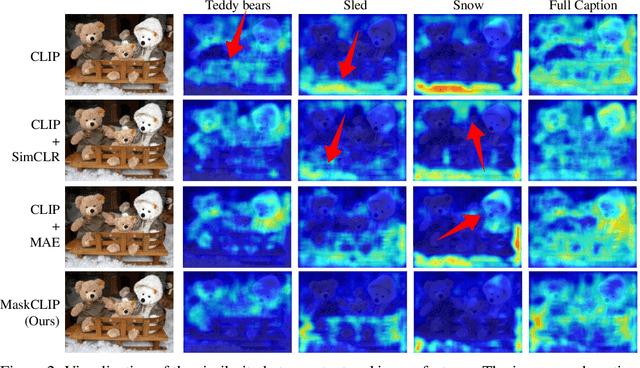
This paper presents a simple yet effective framework MaskCLIP, which incorporates a newly proposed masked self-distillation into contrastive language-image pretraining. The core idea of masked self-distillation is to distill representation from a full image to the representation predicted from a masked image. Such incorporation enjoys two vital benefits. First, masked self-distillation targets local patch representation learning, which is complementary to vision-language contrastive focusing on text-related representation.Second, masked self-distillation is also consistent with vision-language contrastive from the perspective of training objective as both utilize the visual encoder for feature aligning, and thus is able to learn local semantics getting indirect supervision from the language. We provide specially designed experiments with a comprehensive analysis to validate the two benefits. Empirically, we show that MaskCLIP, when applied to various challenging downstream tasks, achieves superior results in linear probing, finetuning as well as the zero-shot performance with the guidance of the language encoder.
Video Mobile-Former: Video Recognition with Efficient Global Spatial-temporal Modeling
Aug 25, 2022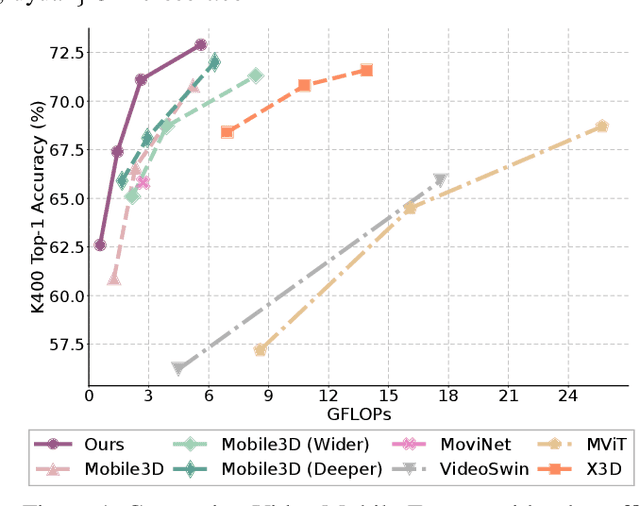
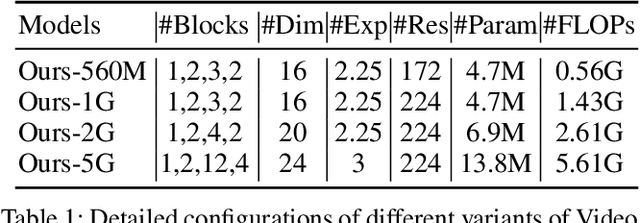
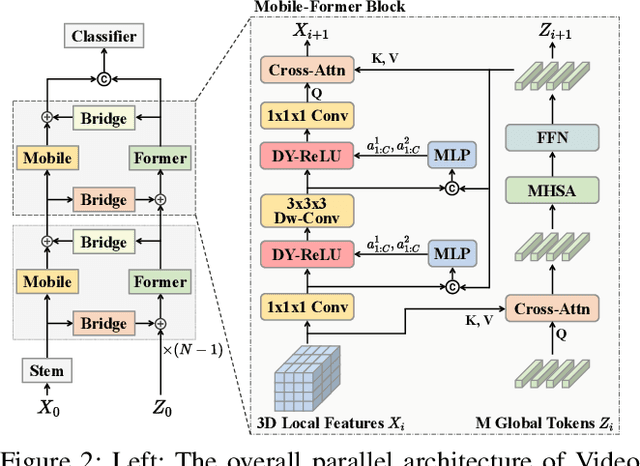
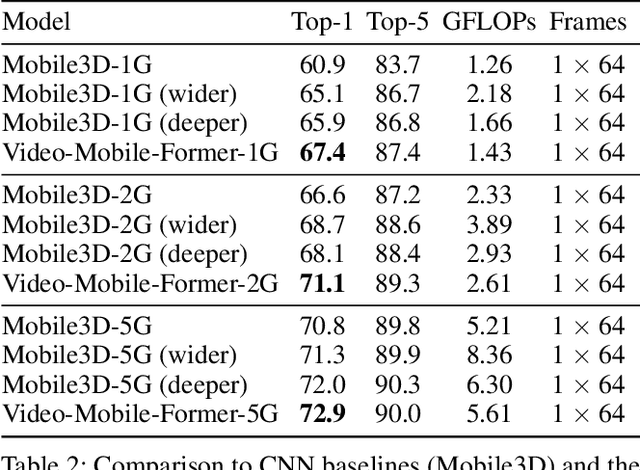
Transformer-based models have achieved top performance on major video recognition benchmarks. Benefiting from the self-attention mechanism, these models show stronger ability of modeling long-range dependencies compared to CNN-based models. However, significant computation overheads, resulted from the quadratic complexity of self-attention on top of a tremendous number of tokens, limit the use of existing video transformers in applications with limited resources like mobile devices. In this paper, we extend Mobile-Former to Video Mobile-Former, which decouples the video architecture into a lightweight 3D-CNNs for local context modeling and a Transformer modules for global interaction modeling in a parallel fashion. To avoid significant computational cost incurred by computing self-attention between the large number of local patches in videos, we propose to use very few global tokens (e.g., 6) for a whole video in Transformers to exchange information with 3D-CNNs with a cross-attention mechanism. Through efficient global spatial-temporal modeling, Video Mobile-Former significantly improves the video recognition performance of alternative lightweight baselines, and outperforms other efficient CNN-based models at the low FLOP regime from 500M to 6G total FLOPs on various video recognition tasks. It is worth noting that Video Mobile-Former is the first Transformer-based video model which constrains the computational budget within 1G FLOPs.
Bootstrapped Masked Autoencoders for Vision BERT Pretraining
Jul 14, 2022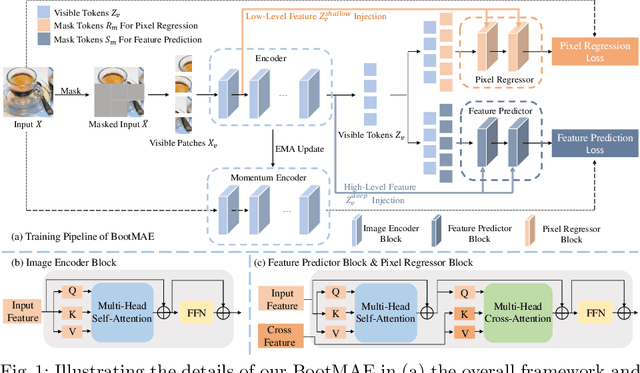



We propose bootstrapped masked autoencoders (BootMAE), a new approach for vision BERT pretraining. BootMAE improves the original masked autoencoders (MAE) with two core designs: 1) momentum encoder that provides online feature as extra BERT prediction targets; 2) target-aware decoder that tries to reduce the pressure on the encoder to memorize target-specific information in BERT pretraining. The first design is motivated by the observation that using a pretrained MAE to extract the features as the BERT prediction target for masked tokens can achieve better pretraining performance. Therefore, we add a momentum encoder in parallel with the original MAE encoder, which bootstraps the pretraining performance by using its own representation as the BERT prediction target. In the second design, we introduce target-specific information (e.g., pixel values of unmasked patches) from the encoder directly to the decoder to reduce the pressure on the encoder of memorizing the target-specific information. Thus, the encoder focuses on semantic modeling, which is the goal of BERT pretraining, and does not need to waste its capacity in memorizing the information of unmasked tokens related to the prediction target. Through extensive experiments, our BootMAE achieves $84.2\%$ Top-1 accuracy on ImageNet-1K with ViT-B backbone, outperforming MAE by $+0.8\%$ under the same pre-training epochs. BootMAE also gets $+1.0$ mIoU improvements on semantic segmentation on ADE20K and $+1.3$ box AP, $+1.4$ mask AP improvement on object detection and segmentation on COCO dataset. Code is released at https://github.com/LightDXY/BootMAE.
Should All Proposals be Treated Equally in Object Detection?
Jul 07, 2022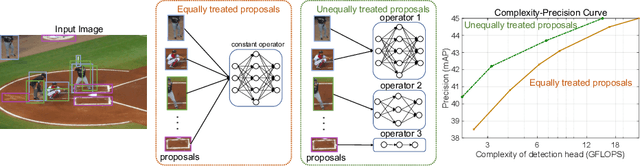
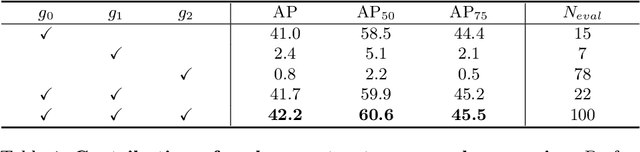
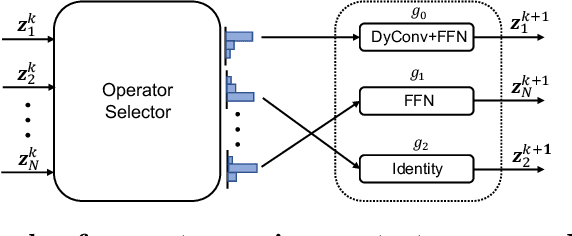
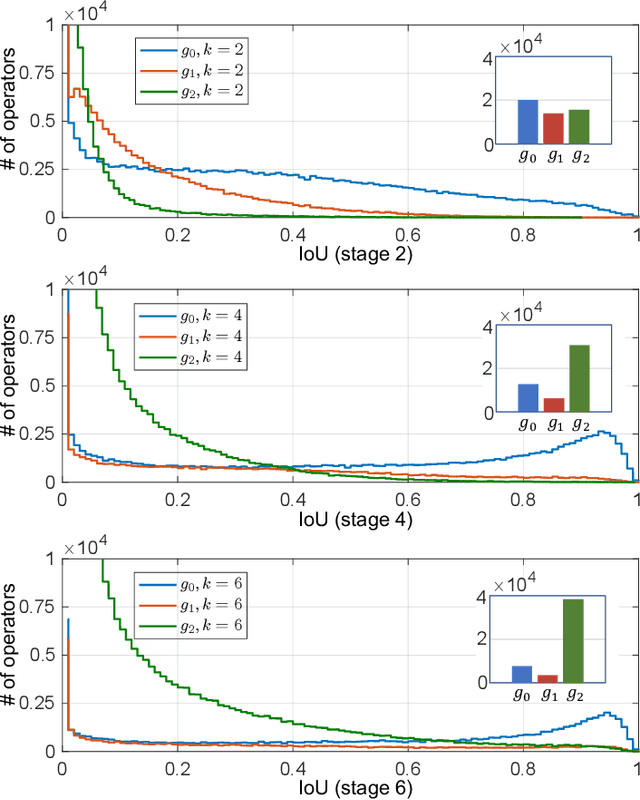
The complexity-precision trade-off of an object detector is a critical problem for resource constrained vision tasks. Previous works have emphasized detectors implemented with efficient backbones. The impact on this trade-off of proposal processing by the detection head is investigated in this work. It is hypothesized that improved detection efficiency requires a paradigm shift, towards the unequal processing of proposals, assigning more computation to good proposals than poor ones. This results in better utilization of available computational budget, enabling higher accuracy for the same FLOPS. We formulate this as a learning problem where the goal is to assign operators to proposals, in the detection head, so that the total computational cost is constrained and the precision is maximized. The key finding is that such matching can be learned as a function that maps each proposal embedding into a one-hot code over operators. While this function induces a complex dynamic network routing mechanism, it can be implemented by a simple MLP and learned end-to-end with off-the-shelf object detectors. This 'dynamic proposal processing' (DPP) is shown to outperform state-of-the-art end-to-end object detectors (DETR, Sparse R-CNN) by a clear margin for a given computational complexity.
Semantic Image Synthesis via Diffusion Models
Jun 30, 2022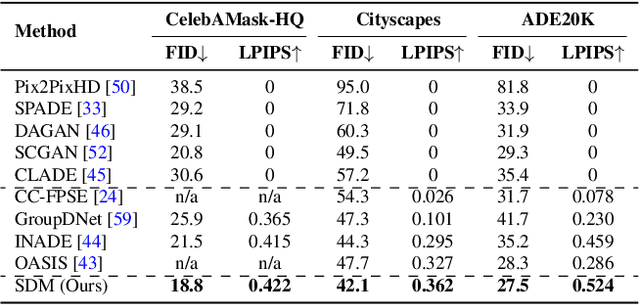
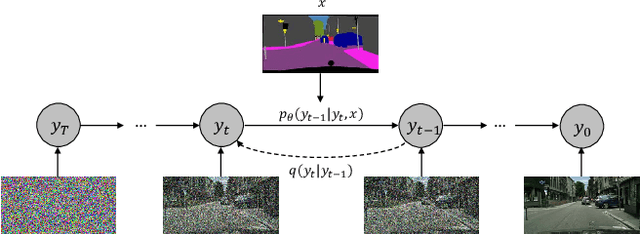
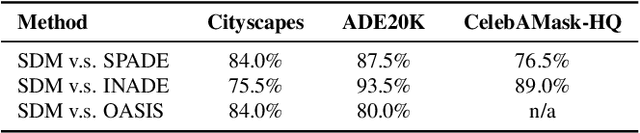
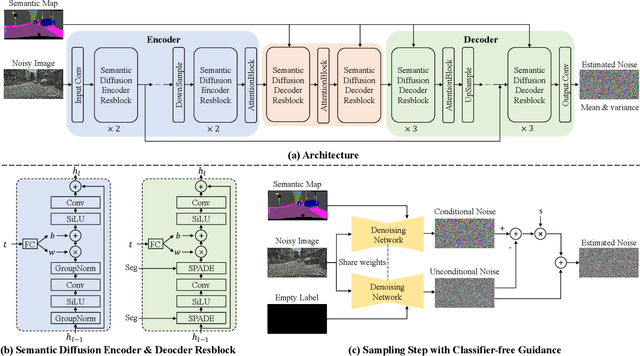
Denoising Diffusion Probabilistic Models (DDPMs) have achieved remarkable success in various image generation tasks compared with Generative Adversarial Nets (GANs). Recent work on semantic image synthesis mainly follows the \emph{de facto} GAN-based approaches, which may lead to unsatisfactory quality or diversity of generated images. In this paper, we propose a novel framework based on DDPM for semantic image synthesis. Unlike previous conditional diffusion model directly feeds the semantic layout and noisy image as input to a U-Net structure, which may not fully leverage the information in the input semantic mask, our framework processes semantic layout and noisy image differently. It feeds noisy image to the encoder of the U-Net structure while the semantic layout to the decoder by multi-layer spatially-adaptive normalization operators. To further improve the generation quality and semantic interpretability in semantic image synthesis, we introduce the classifier-free guidance sampling strategy, which acknowledge the scores of an unconditional model for sampling process. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our proposed method, achieving state-of-the-art performance in terms of fidelity~(FID) and diversity~(LPIPS).
Detection Hub: Unifying Object Detection Datasets via Query Adaptation on Language Embedding
Jun 07, 2022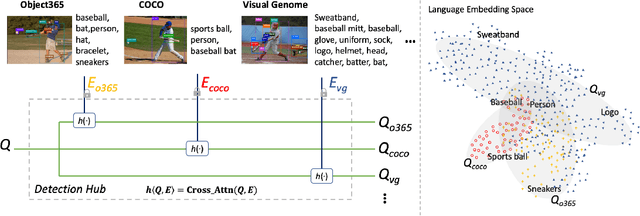

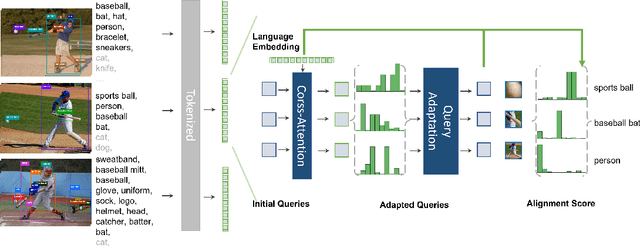
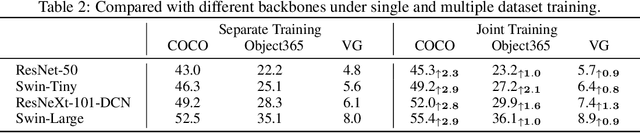
Leveraging large-scale data can introduce performance gains on many computer vision tasks. Unfortunately, this does not happen in object detection when training a single model under multiple datasets together. We observe two main obstacles: taxonomy difference and bounding box annotation inconsistency, which introduces domain gaps in different datasets that prevents us from joint training. In this paper, we show that these two challenges can be effectively addressed by simply adapting object queries on language embedding of categories per dataset. We design a detection hub to dynamically adapt queries on category embedding based on the different distributions of datasets. Unlike previous methods attempted to learn a joint embedding for all datasets, our adaptation method can utilize the language embedding as semantic centers for common categories, while learning the semantic bias towards specific categories belonging to different datasets to handle annotation differences and make up the domain gaps. These novel improvements enable us to end-to-end train a single detector on multiple datasets simultaneously to fully take their advantages. Further experiments on joint training on multiple datasets demonstrate the significant performance gains over separate individual fine-tuned detectors.
REVIVE: Regional Visual Representation Matters in Knowledge-Based Visual Question Answering
Jun 02, 2022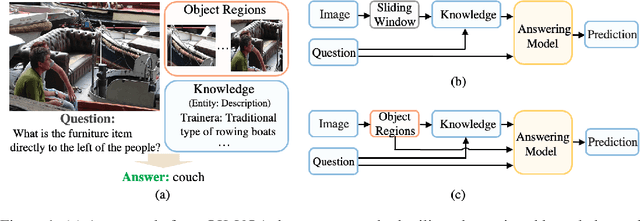
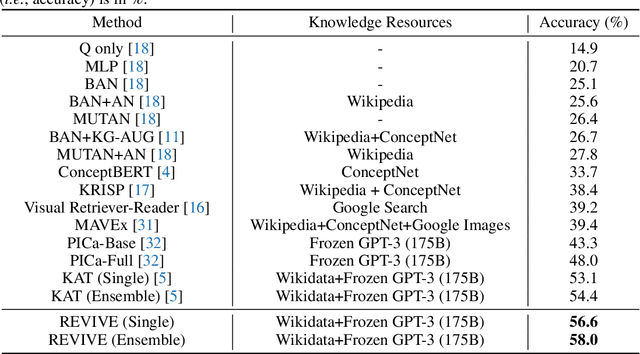
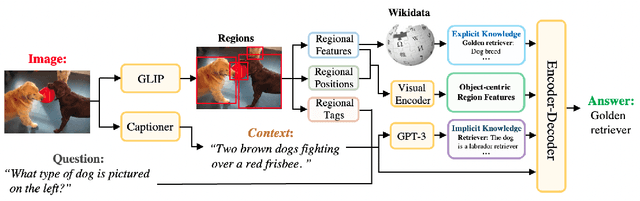

This paper revisits visual representation in knowledge-based visual question answering (VQA) and demonstrates that using regional information in a better way can significantly improve the performance. While visual representation is extensively studied in traditional VQA, it is under-explored in knowledge-based VQA even though these two tasks share the common spirit, i.e., rely on visual input to answer the question. Specifically, we observe that in most state-of-the-art knowledge-based VQA methods: 1) visual features are extracted either from the whole image or in a sliding window manner for retrieving knowledge, and the important relationship within/among object regions is neglected; 2) visual features are not well utilized in the final answering model, which is counter-intuitive to some extent. Based on these observations, we propose a new knowledge-based VQA method REVIVE, which tries to utilize the explicit information of object regions not only in the knowledge retrieval stage but also in the answering model. The key motivation is that object regions and inherent relationships are important for knowledge-based VQA. We perform extensive experiments on the standard OK-VQA dataset and achieve new state-of-the-art performance, i.e., 58.0% accuracy, surpassing previous state-of-the-art method by a large margin (+3.6%). We also conduct detailed analysis and show the necessity of regional information in different framework components for knowledge-based VQA.
Reduce Information Loss in Transformers for Pluralistic Image Inpainting
May 15, 2022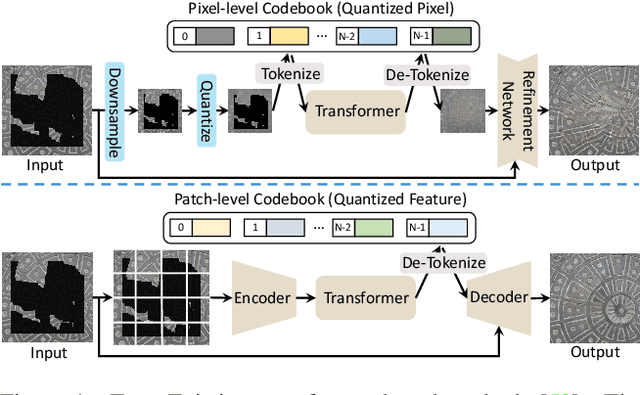
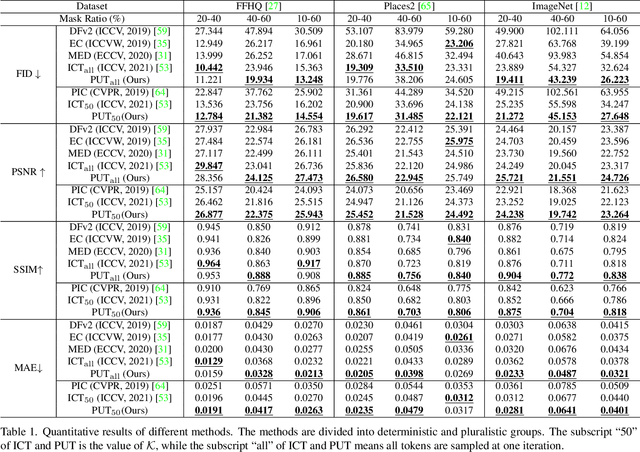
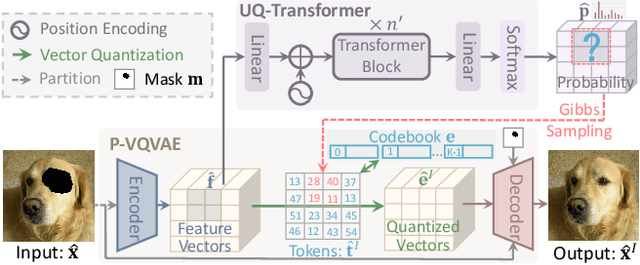

Transformers have achieved great success in pluralistic image inpainting recently. However, we find existing transformer based solutions regard each pixel as a token, thus suffer from information loss issue from two aspects: 1) They downsample the input image into much lower resolutions for efficiency consideration, incurring information loss and extra misalignment for the boundaries of masked regions. 2) They quantize $256^3$ RGB pixels to a small number (such as 512) of quantized pixels. The indices of quantized pixels are used as tokens for the inputs and prediction targets of transformer. Although an extra CNN network is used to upsample and refine the low-resolution results, it is difficult to retrieve the lost information back.To keep input information as much as possible, we propose a new transformer based framework "PUT". Specifically, to avoid input downsampling while maintaining the computation efficiency, we design a patch-based auto-encoder P-VQVAE, where the encoder converts the masked image into non-overlapped patch tokens and the decoder recovers the masked regions from inpainted tokens while keeping the unmasked regions unchanged. To eliminate the information loss caused by quantization, an Un-Quantized Transformer (UQ-Transformer) is applied, which directly takes the features from P-VQVAE encoder as input without quantization and regards the quantized tokens only as prediction targets. Extensive experiments show that PUT greatly outperforms state-of-the-art methods on image fidelity, especially for large masked regions and complex large-scale datasets. Code is available at https://github.com/liuqk3/PUT
i-Code: An Integrative and Composable Multimodal Learning Framework
May 05, 2022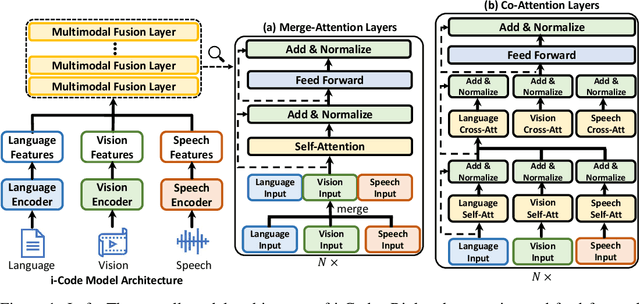
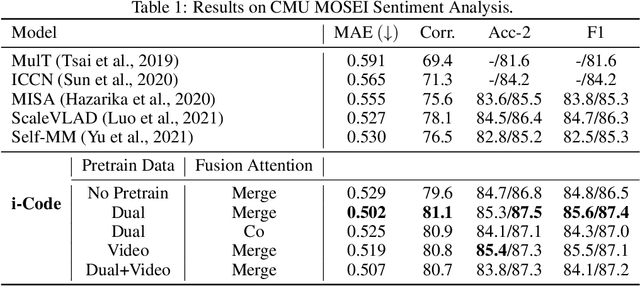
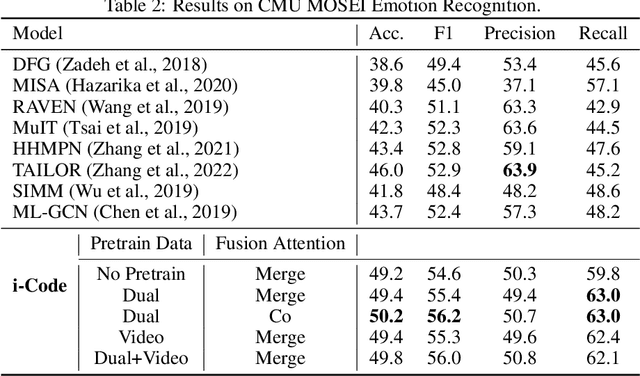

Human intelligence is multimodal; we integrate visual, linguistic, and acoustic signals to maintain a holistic worldview. Most current pretraining methods, however, are limited to one or two modalities. We present i-Code, a self-supervised pretraining framework where users may flexibly combine the modalities of vision, speech, and language into unified and general-purpose vector representations. In this framework, data from each modality are first given to pretrained single-modality encoders. The encoder outputs are then integrated with a multimodal fusion network, which uses novel attention mechanisms and other architectural innovations to effectively combine information from the different modalities. The entire system is pretrained end-to-end with new objectives including masked modality unit modeling and cross-modality contrastive learning. Unlike previous research using only video for pretraining, the i-Code framework can dynamically process single, dual, and triple-modality data during training and inference, flexibly projecting different combinations of modalities into a single representation space. Experimental results demonstrate how i-Code can outperform state-of-the-art techniques on five video understanding tasks and the GLUE NLP benchmark, improving by as much as 11% and demonstrating the power of integrative multimodal pretraining.