 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasets and Benchmarks for Offline Safe Reinforcement Learning
Jun 16, 2023



This paper presents a comprehensive benchmarking suite tailored to offline safe reinforcement learning (RL) challenges, aiming to foster progress in the development and evaluation of safe learning algorithms in both the training and deployment phases. Our benchmark suite contains three packages: 1) expertly crafted safe policies, 2) D4RL-styled datasets along with environment wrappers, and 3) high-quality offline safe RL baseline implementations. We feature a methodical data collection pipeline powered by advanced safe RL algorithms, which facilitates the generation of diverse datasets across 38 popular safe RL tasks, from robot control to autonomous driving. We further introduce an array of data post-processing filters, capable of modifying each dataset's diversity, thereby simulating various data collection conditions. Additionally, we provide elegant and extensible implementations of prevalent offline safe RL algorithms to accelerate research in this area. Through extensive experiments with over 50000 CPU and 800 GPU hours of computations, we evaluate and compare the performance of these baseline algorithms on the collected datasets, offering insights into their strengths, limitations, and potential areas of improvement. Our benchmarking framework serves as a valuable resource for researchers and practitioners, facilitating the development of more robust and reliable offline safe RL solutions in safety-critical applications. The benchmark website is available at \url{www.offline-saferl.org}.
Your Room is not Private: Gradient Inversion Attack for Deep Q-Learning
Jun 15, 2023



The prominence of embodied Artificial Intelligence (AI), which empowers robots to navigate, perceive, and engage within virtual environments, has attracted significant attention, owing to the remarkable advancements in computer vision and large language models. Privacy emerges as a pivotal concern within the realm of embodied AI, as the robot access substantial personal information. However, the issue of privacy leakage in embodied AI tasks, particularly in relation to decision-making algorithms, has not received adequate consideration in research. This paper aims to address this gap by proposing an attack on the Deep Q-Learning algorithm, utilizing gradient inversion to reconstruct states, actions, and Q-values. The choice of using gradients for the attack is motivated by the fact that commonly employed federated learning techniques solely utilize gradients computed based on private user data to optimize models, without storing or transmitting the data to public servers. Nevertheless, these gradients contain sufficient information to potentially expose private data. To validate our approach, we conduct experiments on the AI2THOR simulator and evaluate our algorithm on active perception, a prevalent task in embodied AI. The experimental results convincingly demonstrate the effectiveness of our method in successfully recovering all information from the data across all 120 room layouts.
Embodied Executable Policy Learning with Language-based Scene Summarization
Jun 09, 2023Large Language models (LLMs) have shown remarkable success in assisting robot learning tasks, i.e., complex household planning. However, the performance of pretrained LLMs heavily relies on domain-specific templated text data, which may be infeasible in real-world robot learning tasks with image-based observations. Moreover, existing LLMs with text inputs lack the capability to evolve with non-expert interactions with environments. In this work, we introduce a novel learning paradigm that generates robots' executable actions in the form of text, derived solely from visual observations, using language-based summarization of these observations as the connecting bridge between both domains. Our proposed paradigm stands apart from previous works, which utilized either language instructions or a combination of language and visual data as inputs. Moreover, our method does not require oracle text summarization of the scene, eliminating the need for human involvement in the learning loop, which makes it more practical for real-world robot learning tasks. Our proposed paradigm consists of two modules: the SUM module, which interprets the environment using visual observations and produces a text summary of the scene, and the APM module, which generates executable action policies based on the natural language descriptions provided by the SUM module. We demonstrate that our proposed method can employ two fine-tuning strategies, including imitation learning and reinforcement learning approaches, to adapt to the target test tasks effectively. We conduct extensive experiments involving various SUM/APM model selections, environments, and tasks across 7 house layouts in the VirtualHome environment. Our experimental results demonstrate that our method surpasses existing baselines, confirming the effectiveness of this novel learning paradigm.
MultiSum: A Dataset for Multimodal Summarization and Thumbnail Generation of Videos
Jun 07, 2023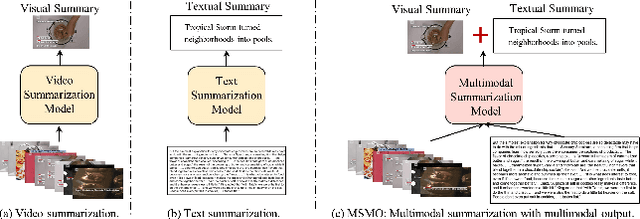
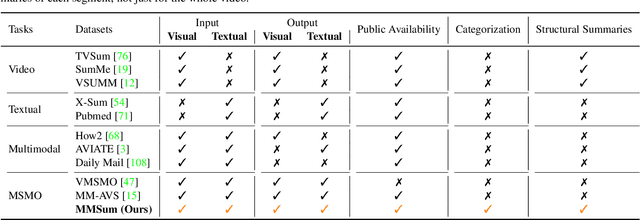
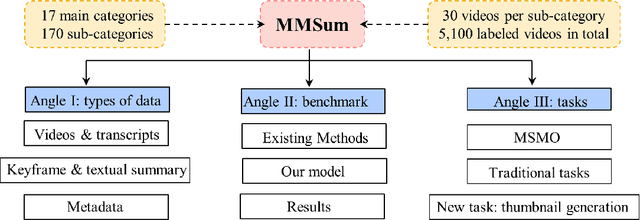
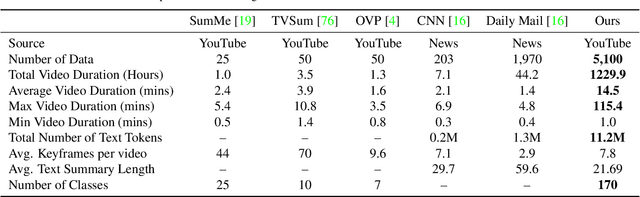
Multimodal summarization with multimodal output (MSMO) has emerged as a promising research direction. Nonetheless, numerous limitations exist within existing public MSMO datasets, including insufficient upkeep, data inaccessibility, limited size, and the absence of proper categorization, which pose significant challenges to effective research. To address these challenges and provide a comprehensive dataset for this new direction, we have meticulously curated the MultiSum dataset. Our new dataset features (1) Human-validated summaries for both video and textual content, providing superior human instruction and labels for multimodal learning. (2) Comprehensively and meticulously arranged categorization, spanning 17 principal categories and 170 subcategories to encapsulate a diverse array of real-world scenarios. (3) Benchmark tests performed on the proposed dataset to assess varied tasks and methods, including video temporal segmentation, video summarization, text summarization, and multimodal summarization. To champion accessibility and collaboration, we release the MultiSum dataset and the data collection tool as fully open-source resources, fostering transparency and accelerating future developments. Our project website can be found at https://multisum-dataset.github.io/.
Bayesian Reparameterization of Reward-Conditioned Reinforcement Learning with Energy-based Models
May 18, 2023



Recently, reward-conditioned reinforcement learning (RCRL) has gained popularity due to its simplicity, flexibility, and off-policy nature. However, we will show that current RCRL approaches are fundamentally limited and fail to address two critical challenges of RCRL -- improving generalization on high reward-to-go (RTG) inputs, and avoiding out-of-distribution (OOD) RTG queries during testing time. To address these challenges when training vanilla RCRL architectures, we propose Bayesian Reparameterized RCRL (BR-RCRL), a novel set of inductive biases for RCRL inspired by Bayes' theorem. BR-RCRL removes a core obstacle preventing vanilla RCRL from generalizing on high RTG inputs -- a tendency that the model treats different RTG inputs as independent values, which we term ``RTG Independence". BR-RCRL also allows us to design an accompanying adaptive inference method, which maximizes total returns while avoiding OOD queries that yield unpredictable behaviors in vanilla RCRL methods. We show that BR-RCRL achieves state-of-the-art performance on the Gym-Mujoco and Atari offline RL benchmarks, improving upon vanilla RCRL by up to 11%.
Hyper-Decision Transformer for Efficient Online Policy Adaptation
Apr 17, 2023Decision Transformers (DT) have demonstrated strong performances in offline reinforcement learning settings, but quickly adapting to unseen novel tasks remains challenging. To address this challenge, we propose a new framework, called Hyper-Decision Transformer (HDT), that can generalize to novel tasks from a handful of demonstrations in a data- and parameter-efficient manner. To achieve such a goal, we propose to augment the base DT with an adaptation module, whose parameters are initialized by a hyper-network. When encountering unseen tasks, the hyper-network takes a handful of demonstrations as inputs and initializes the adaptation module accordingly. This initialization enables HDT to efficiently adapt to novel tasks by only fine-tuning the adaptation module. We validate HDT's generalization capability on object manipulation tasks. We find that with a single expert demonstration and fine-tuning only 0.5% of DT parameters, HDT adapts faster to unseen tasks than fine-tuning the whole DT model. Finally, we explore a more challenging setting where expert actions are not available, and we show that HDT outperforms state-of-the-art baselines in terms of task success rates by a large margin.
Multimodal Representation Learning of Cardiovascular Magnetic Resonance Imaging
Apr 16, 2023Self-supervised learning is crucial for clinical imaging applications, given the lack of explicit labels in healthcare. However, conventional approaches that rely on precise vision-language alignment are not always feasible in complex clinical imaging modalities, such as cardiac magnetic resonance (CMR). CMR provides a comprehensive visualization of cardiac anatomy, physiology, and microstructure, making it challenging to interpret. Additionally, CMR reports require synthesizing information from sequences of images and different views, resulting in potentially weak alignment between the study and diagnosis report pair. To overcome these challenges, we propose \textbf{CMRformer}, a multimodal learning framework to jointly learn sequences of CMR images and associated cardiologist's reports. Moreover, one of the major obstacles to improving CMR study is the lack of large, publicly available datasets. To bridge this gap, we collected a large \textbf{CMR dataset}, which consists of 13,787 studies from clinical cases. By utilizing our proposed CMRformer and our collected dataset, we achieved remarkable performance in real-world clinical tasks, such as CMR image retrieval and diagnosis report retrieval. Furthermore, the learned representations are evaluated to be practically helpful for downstream applications, such as disease classification. Our work could potentially expedite progress in the CMR study and lead to more accurate and effective diagnosis and treatment.
Converting ECG Signals to Images for Efficient Image-text Retrieval via Encoding
Apr 13, 2023



Automated interpretation of electrocardiograms (ECG) has garnered significant attention with the advancements in machine learning methodologies. Despite the growing interest in automated ECG interpretation using machine learning, most current studies focus solely on classification or regression tasks and overlook a crucial aspect of clinical cardio-disease diagnosis: the diagnostic report generated by experienced human clinicians. In this paper, we introduce a novel approach to ECG interpretation, leveraging recent breakthroughs in Large Language Models (LLMs) and Vision-Transformer (ViT) models. Rather than treating ECG diagnosis as a classification or regression task, we propose an alternative method of automatically identifying the most similar clinical cases based on the input ECG data. Also, since interpreting ECG as images are more affordable and accessible, we process ECG as encoded images and adopt a vision-language learning paradigm to jointly learn vision-language alignment between encoded ECG images and ECG diagnosis reports. Encoding ECG into images can result in an efficient ECG retrieval system, which will be highly practical and useful in clinical applications. More importantly, our findings could serve as a crucial resource for providing diagnostic services in regions where only paper-printed ECG images are accessible due to past underdevelopment.
Sharing Low Rank Conformer Weights for Tiny Always-On Ambient Speech Recognition Models
Mar 15, 2023Continued improvements in machine learning techniques offer exciting new opportunities through the use of larger models and larger training datasets. However, there is a growing need to offer these new capabilities on-board low-powered devices such as smartphones, wearables and other embedded environments where only low memory is available. Towards this, we consider methods to reduce the model size of Conformer-based speech recognition models which typically require models with greater than 100M parameters down to just $5$M parameters while minimizing impact on model quality. Such a model allows us to achieve always-on ambient speech recognition on edge devices with low-memory neural processors. We propose model weight reuse at different levels within our model architecture: (i) repeating full conformer block layers, (ii) sharing specific conformer modules across layers, (iii) sharing sub-components per conformer module, and (iv) sharing decomposed sub-component weights after low-rank decomposition. By sharing weights at different levels of our model, we can retain the full model in-memory while increasing the number of virtual transformations applied to the input. Through a series of ablation studies and evaluations, we find that with weight sharing and a low-rank architecture, we can achieve a WER of 2.84 and 2.94 for Librispeech dev-clean and test-clean respectively with a $5$M parameter model.
GOATS: Goal Sampling Adaptation for Scooping with Curriculum Reinforcement Learning
Mar 09, 2023



In this work, we first formulate the problem of goal-conditioned robotic water scooping with reinforcement learning. This task is challenging due to the complex dynamics of fluid and multi-modal goal-reaching. The policy is required to achieve both position goals and water amount goals, which leads to a large convoluted goal state space. To address these challenges, we introduce Goal Sampling Adaptation for Scooping (GOATS), a curriculum reinforcement learning method that can learn an effective and generalizable policy for robot scooping tasks. Specifically, we use a goal-factorized reward formulation and interpolate position goal distributions and amount goal distributions to create curriculum through the learning process. As a result, our proposed method can outperform the baselines in simulation and achieves 5.46% and 8.71% amount errors on bowl scooping and bucket scooping tasks, respectively, under 1000 variations of initial water states in the tank and a large goal state space. Besides being effective in simulation environments, our method can efficiently generalize to noisy real-robot water-scooping scenarios with different physical configurations and unseen settings, demonstrating superior efficacy and generalizability. The videos of this work are available on our project page: https://sites.google.com/view/goatscooping.