 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Sample Selection Bias Precipitates Model Collapse
Jun 11, 2026The proliferation of recursive training on synthetic data can alleviate data scarcity but risks model collapse, where repeated training erodes distributional tails and homogenizes outputs. Data selection is widely viewed as a remedy, yet its reliability depends critically on the reference distribution used by the verifier. We show that in low-resource verification regimes, where each verifier observes only a small, fragmented, and biased slice of the target manifold, selection itself becomes biased. This situation naturally arises in low-resource data silos such as healthcare consortia or proprietary financial institutions, where raw data cannot be pooled and local references are inherently incomplete. As a result, selection preferentially retains samples aligned with the local manifold while pruning globally relevant tail modes, turning from a safeguard against collapse into a mechanism that precipitates it. We theoretically prove that such siloed selection accelerates collapse and induces power-law diversity decay. As an initial mitigation, we construct Wasserstein proxy references from multiple silos without sharing raw data. Empirical results confirm that local-reference selection fails on skewed distributions, whereas collaborative proxy references mitigate diversity degradation, suggesting that recursive synthetic-data pipelines require particular caution when real-data coverage is fragmented or scarce.
Not an Obstacle for Dog, but a Hazard for Human: A Co-Ego Navigation System for Guide Dog Robots
Mar 20, 2026Guide dogs offer independence to Blind and Low-Vision (BLV) individuals, yet their limited availability leaves the vast majority of BLV users without access. Quadruped robotic guide dogs present a promising alternative, but existing systems rely solely on the robot's ground-level sensors for navigation, overlooking a critical class of hazards: obstacles that are transparent to the robot yet dangerous at human body height, such as bent branches. We term this the viewpoint asymmetry problem and present the first system to explicitly address it. Our Co-Ego system adopts a dual-branch obstacle avoidance framework that integrates the robot-centric ground sensing with the user's elevated egocentric perspective to ensure comprehensive navigation safety. Deployed on a quadruped robot, the system is evaluated in a controlled user study with sighted participants under blindfold across three conditions: unassisted, single-view, and cross-view fusion. Results demonstrate that cross-view fusion significantly reduces collision times and cognitive load, verifying the necessity of viewpoint complementarity for safe robotic guide dog navigation.
More Haste, Less Speed: Weaker Single-Layer Watermark Improves Distortion-Free Watermark Ensembles
Feb 12, 2026Watermarking has emerged as a crucial technique for detecting and attributing content generated by large language models. While recent advancements have utilized watermark ensembles to enhance robustness, prevailing methods typically prioritize maximizing the strength of the watermark at every individual layer. In this work, we identify a critical limitation in this "stronger-is-better" approach: strong watermarks significantly reduce the entropy of the token distribution, which paradoxically weakens the effectiveness of watermarking in subsequent layers. We theoretically and empirically show that detectability is bounded by entropy and that watermark ensembles induce a monotonic decrease in both entropy and the expected green-list ratio across layers. To address this inherent trade-off, we propose a general framework that utilizes weaker single-layer watermarks to preserve the entropy required for effective multi-layer ensembling. Empirical evaluations demonstrate that this counter-intuitive strategy mitigates signal decay and consistently outperforms strong baselines in both detectability and robustness.
FP8-RL: A Practical and Stable Low-Precision Stack for LLM Reinforcement Learning
Jan 26, 2026Reinforcement learning (RL) for large language models (LLMs) is increasingly bottlenecked by rollout (generation), where long output sequence lengths make attention and KV-cache memory dominate end-to-end step time. FP8 offers an attractive lever for accelerating RL by reducing compute cost and memory traffic during rollout, but applying FP8 in RL introduces unique engineering and algorithmic challenges: policy weights change every step (requiring repeated quantization and weight synchronization into the inference engine) and low-precision rollouts can deviate from the higher-precision policy assumed by the trainer, causing train-inference mismatch and potential instability. This report presents a practical FP8 rollout stack for LLM RL, implemented in the veRL ecosystem with support for common training backends (e.g., FSDP/Megatron-LM) and inference engines (e.g., vLLM/SGLang). We (i) enable FP8 W8A8 linear-layer rollout using blockwise FP8 quantization, (ii) extend FP8 to KV-cache to remove long-context memory bottlenecks via per-step QKV scale recalibration, and (iii) mitigate mismatch using importance-sampling-based rollout correction (token-level TIS/MIS variants). Across dense and MoE models, these techniques deliver up to 44% rollout throughput gains while preserving learning behavior comparable to BF16 baselines.
As If We've Met Before: LLMs Exhibit Certainty in Recognizing Seen Files
Nov 19, 2025The remarkable language ability of Large Language Models (LLMs) stems from extensive training on vast datasets, often including copyrighted material, which raises serious concerns about unauthorized use. While Membership Inference Attacks (MIAs) offer potential solutions for detecting such violations, existing approaches face critical limitations and challenges due to LLMs' inherent overconfidence, limited access to ground truth training data, and reliance on empirically determined thresholds. We present COPYCHECK, a novel framework that leverages uncertainty signals to detect whether copyrighted content was used in LLM training sets. Our method turns LLM overconfidence from a limitation into an asset by capturing uncertainty patterns that reliably distinguish between ``seen" (training data) and ``unseen" (non-training data) content. COPYCHECK further implements a two-fold strategy: (1) strategic segmentation of files into smaller snippets to reduce dependence on large-scale training data, and (2) uncertainty-guided unsupervised clustering to eliminate the need for empirically tuned thresholds. Experiment results show that COPYCHECK achieves an average balanced accuracy of 90.1% on LLaMA 7b and 91.6% on LLaMA2 7b in detecting seen files. Compared to the SOTA baseline, COPYCHECK achieves over 90% relative improvement, reaching up to 93.8\% balanced accuracy. It further exhibits strong generalizability across architectures, maintaining high performance on GPT-J 6B. This work presents the first application of uncertainty for copyright detection in LLMs, offering practical tools for training data transparency.
Converting ECG Signals to Images for Efficient Image-text Retrieval via Encoding
Apr 13, 2023



Automated interpretation of electrocardiograms (ECG) has garnered significant attention with the advancements in machine learning methodologies. Despite the growing interest in automated ECG interpretation using machine learning, most current studies focus solely on classification or regression tasks and overlook a crucial aspect of clinical cardio-disease diagnosis: the diagnostic report generated by experienced human clinicians. In this paper, we introduce a novel approach to ECG interpretation, leveraging recent breakthroughs in Large Language Models (LLMs) and Vision-Transformer (ViT) models. Rather than treating ECG diagnosis as a classification or regression task, we propose an alternative method of automatically identifying the most similar clinical cases based on the input ECG data. Also, since interpreting ECG as images are more affordable and accessible, we process ECG as encoded images and adopt a vision-language learning paradigm to jointly learn vision-language alignment between encoded ECG images and ECG diagnosis reports. Encoding ECG into images can result in an efficient ECG retrieval system, which will be highly practical and useful in clinical applications. More importantly, our findings could serve as a crucial resource for providing diagnostic services in regions where only paper-printed ECG images are accessible due to past underdevelopment.
OL4EL: Online Learning for Edge-cloud Collaborative Learning on Heterogeneous Edges with Resource Constraints
Apr 23, 2020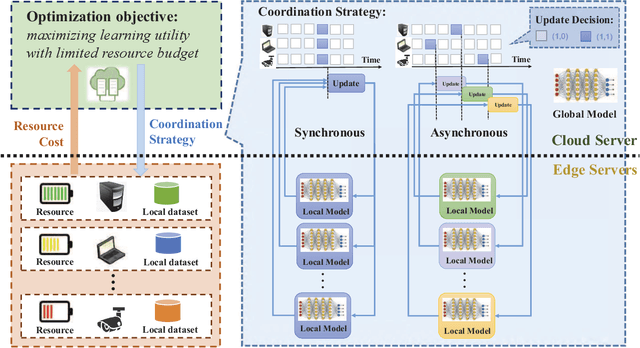
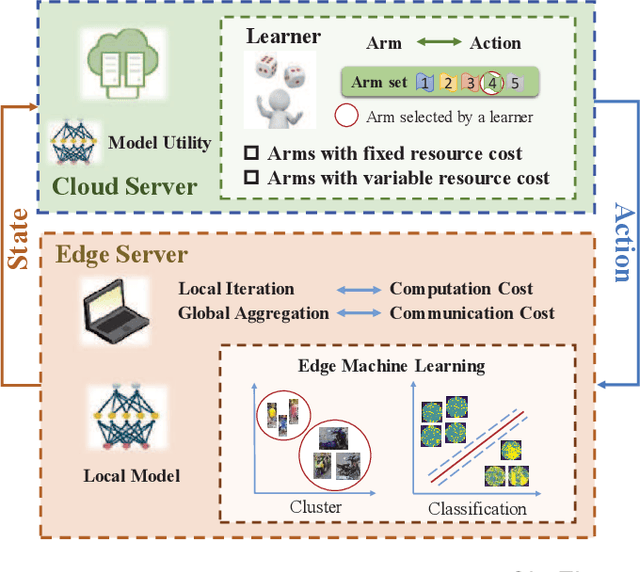
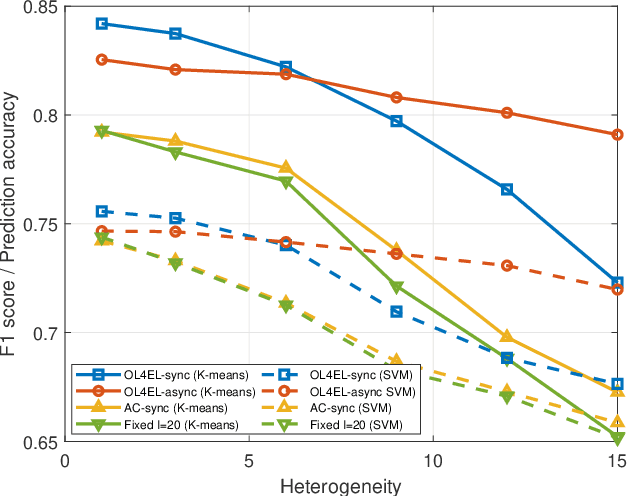
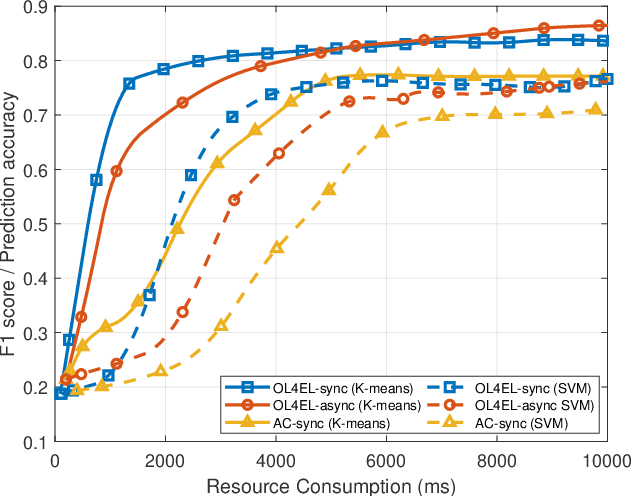
Distributed machine learning (ML) at network edge is a promising paradigm that can preserve both network bandwidth and privacy of data providers. However, heterogeneous and limited computation and communication resources on edge servers (or edges) pose great challenges on distributed ML and formulate a new paradigm of Edge Learning (i.e. edge-cloud collaborative machine learning). In this article, we propose a novel framework of 'learning to learn' for effective Edge Learning (EL) on heterogeneous edges with resource constraints. We first model the dynamic determination of collaboration strategy (i.e. the allocation of local iterations at edge servers and global aggregations on the Cloud during collaborative learning process) as an online optimization problem to achieve the tradeoff between the performance of EL and the resource consumption of edge servers. Then, we propose an Online Learning for EL (OL4EL) framework based on the budget-limited multi-armed bandit model. OL4EL supports both synchronous and asynchronous learning patterns, and can be used for both supervised and unsupervised learning tasks. To evaluate the performance of OL4EL, we conducted both real-world testbed experiments and extensive simulations based on docker containers, where both Support Vector Machine and K-means were considered as use cases. Experimental results demonstrate that OL4EL significantly outperforms state-of-the-art EL and other collaborative ML approaches in terms of the trade-off between learning performance and resource consumption.